11 KiB
事务
事务分类
事务通常可分为如下类型:
- 扁平事务(flat transaction)
- 带保存点的扁平事务(flat transaction with savepoints)
- 链事务(chained transaction)
- 嵌套事务(nested transaction)
- 分布式事务(distributed transaction)
扁平事务
扁平事务为最常用的事务,在扁平事务中,所有操作都处于统一层次,其由begin work开始,并由commit work或rollback work结束。
扁平事务的操作是原子的,要么都提交,要么都回滚。
带有保存点的扁平事务
对于带有保存点的扁平事务,其支持在事务执行过程中回滚到同一事务中较早的一个状态。
在事务执行过程中,可能并不希望所有的操作都回滚,放弃所有操作的代价可能太大。通过保存点,可以记住事务当前的状态,在后续发生错误后,事务能够回到保存点当时的状态。
相较于扁平事务只能够全部回滚,带保存点的扁平事务能够回滚到保存点时的状态。
保存点可以通过save work来创建,使用示例如下所示

链事务
可视为保存点事务的一个变种。在使用带保存点的事务时,如果系统发生崩溃,那么所有的保存点都会消失。在后续重启进行恢复时,事务需要从开始处重新执行,而不是从最近的一个保存点开始执行。
若事务在数据库未提交时发生崩溃,那么在数据库再次重启执行recovery操作时,会对未提交的事务进行回滚,即使之前事务存在保存点,也会全部回滚
链事务的思想是,当提交事务时,释放不必要的数据对象,将必要的上下文隐式传递给下一个要开始的事务。提交事务和开始下一个事务操作必须为原子操作,下一个事务必须徐要能看到上一个事务的结果,示例如下:

和带保存点的扁平事务不同的是,带保存点的扁平事务能够回滚到任意正确的保存点,而链事务只能回滚当前事务。
且链事务和带保存点的扁平事务,对于锁的处理也不同:
链事务:对于每个事务,commit后释放持有的锁带保存点的扁平事务:在整个事务提交前,不会释放持有的锁
嵌套事务
嵌套事务为一个层次结构框架,由顶层事务控制各个层次的事务。嵌套在顶层事务中的事务被称为子事务。
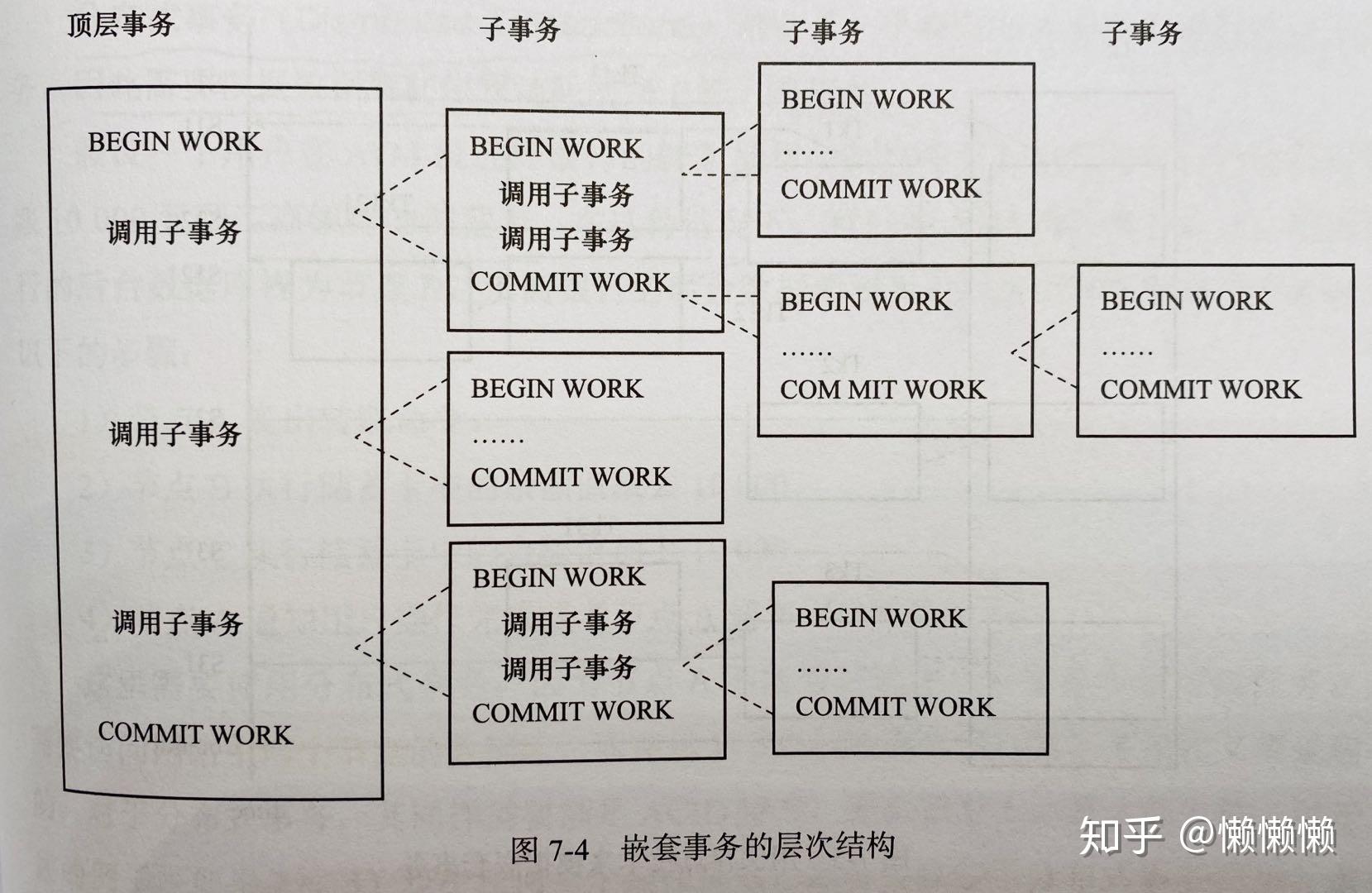
如下为Moss理论嵌套事务的定义:
- 嵌套事务是由若干事务组成的一颗树,子树既可以是嵌套事务,又可以是扁平事务
- 处在叶子节点的事务是扁平事务
- 位于根节点的事务被称为顶层事务,其他事务被称为子事务,事务的
predecessor被称为父事务,事务的下一层事务被称为子事务 - 子事务既可以提交又可以回滚,但是子事务的提交并不会立马生效,除非其父事务已经被提交。
任何子事务都在顶层事务提交后才真正提交 - 树中任何一个事务的回滚会引其所有子事务都一起回滚
在Moss理论中,实际工作被交由叶子节点来完成,只有叶子节点的事务才能够访问数据库,发送消息,获取其他类型的资源。高层事务仅仅负责逻辑控制,即负责何时调用相关子事务。
即使一个系统不支持嵌套事务,也可以通过保存点技术来模拟嵌套事务。
savepoint和嵌套事务区别
在使用保存点来模拟嵌套事务时,在锁持有方面和嵌套事务有差别。
- 嵌套事务:在使用嵌套事务时,不同子事务在数据库持有的锁不同
- 保存点:在通过保存点来模拟嵌套事务时,用户无法选择哪些锁被哪些子事务继承,无论有多少个保存点,所有的锁都可以得到访问
分布式事务
通常是在分布式环境运行的扁平事务,需要访问网络中的不同节点。
分布式事务同样需要满足ACID的特性,要么都发生,要么都不发生。
对于innodb存储引擎,其支持扁平事务、带有保存点的扁平事务、链事务、分布式事务。innodb并不原生支持嵌套事务,单可以通过带保存点的事务来模拟串行的嵌套事务。
事务实现
对于事务的ACID特性,其实现如下:
I(隔离性):事务隔离性通过锁来实现A(原子性), D(持久性):事务的原子性和持久性可以通过redo log来实现C(一致性):事务一致性通过undo log来实现
redo
redo log(重做日志)用于实现事务的持久性,其由两部分组成:
- 内存中的重做日志缓冲(redo log buffer)
- 磁盘中的重做日志文件(redo log file)
redo log persists before transaction committed
innodb存储引擎支持事务,其通过force log at commit机制实现事务的持久性,即当事务提交时,必须先将该事务的所有日志写入到磁盘的日志文件中进行持久化,直到该过程完成后事务才提交完成。
上述描述中
提交时将事务所有日志写入到磁盘的日志文件中,这句话中日志代表redo log 和 undo log。
- redo log用于保证事务持久性
- undo log用于帮助事务回滚,也用于mvcc功能
redo log和undo log比较
- redo log在mysql server运行时,只会被顺序的写入,server运行时并不会被读取
- undo log则不同,在server运行时可能需要对事务进行回滚或执行mvcc操作,此时可能需要对undo log文件进行
随机读写
redo log和binlog的比较
binglog通常用于对数据库进行point in time形式的恢复(从某个时间点起恢复数据)以及主从复制;但是,binlog和redo log的差别如下:
- binlog针对的是mysql数据库级别,不止用于innodb,还用于其他存储引擎
- redo log属于innodb存储引擎级别
- binlog实际记录的是对应sql语句,属于逻辑日志
- redo log实际记录的格式则是物理格式,具体为针对某个页面的物理修改
redo log和 bin log日志写入磁盘的时机也有所不同:
- bin log
仅在事务提交后才进行一次写入 - redo log
在事务执行过程中也可能发生写入(redo log buffer满后会写入到磁盘中),故而,redo log file中同一事务写入的redo log内容可能并非是连续的,多个事务在写入redo log时可能会交叉写入
innodb_flush_log_at_trx_commit
参数innodb_flush_log_at_trx_commit用于控制redo log/ undo log刷新到磁盘的策略,该参数默认值为1,即事务提交时刷新日志到磁盘。除了默认值之外,还可以为该参数设置如下值:
- 0: 事务提交时不刷新日志到磁盘,仅在master thread中刷新日志到磁盘,master thread中刷新操作每秒触发一次
- 2:事务提交时刷新日志,但是仅将日志写入到文件系统的缓存中,
并不进行fsync操作
将innodb_flush_log_at_trx_commit参数设置为0或2虽然可以在一定幅度上提高性能,但是会丧失数据库的ACID特性。
log block
在innodb中,redo都是以512字节的大小为单位进行存储的,即redo log buffer、redo log file都是以block的形式进行保存,block的大小为512字节。
block & atomic
若针对相同的页,redo log的大小大于512字节,那么其会被分割为多个block进行存储。且由于redo log block的大小和磁盘扇区相同,故而在将block时,无需使用double write机制,针对特定的block,起写入为原子的,要么写入成功要么写入失败,不会像页(page)一样存在dirty的情况。
redo log block中包含的内容除了日志本身外,还包含log block header和log block tailer内容。log block header + log block content + log block tailer合计占用512字节,其中,各部分大小如下:
log block header: 12字节大小log block content: 492字节大小log block tailer: 8字节大小
如上所示,每个redo log block可实际存储的内容大小为492字节。
log block header
log block header大小为12字节,由如下部分组成:
LOG_BLOCK_HDR_NO: 占用4字节LOG_BLOCK_HDR_DATA_LEN: 占用2字节LOG_BLOCK_FIRST_REC_GROUP: 占用2字节LOG_BLOCK_CHECKPOINT_NO: 占用4字节
LOG_BLOCK_HDR_NO
log buffer由log block所组成,可以将log buffer看作是log block的数组,故而,log block header中LOG_BLOCK_HDR_NO起代表当前block在buffer中的位置。
LOG_BLOCK_HDR_NO由于表示的是log buffer中的数组小标,故而可知LOG_BLOCK_HDR_NO其是递增的,并且可以循环使用。LOG_BLOCK_HDR_NO的大小为4字节,但是其首位用作flush bit,故而,其可表示的最大长度为2^31 bytes = 2GiB。
LOG_BLOCK_HDR_DATA_LEN
LOG_BLOCK_HDR_DATA_LEN大小为2字节,代表log block所占用的大小,当log block被写满时,该值为0x200,表示当前log block使用完block中所有的可用空间,即log block的大小为512字节。
LOG_BLOCK_FIRST_REC_GROUP
LOG_BLOCK_FIRST_REC_GROUP占用2个字节,表示log block中第一个日志所处的偏移量。
LOG_BLOCK-FIRST_REC_GROUP的取值可能存在如下场景:
- 该值大小和
LOG_BLOCK_HDR_DATA_LEN相同,则代表当前block中不包含新的日志
下图表示事务T1的重做日志占用762字节,事务T2的重做日志占用100字节的场景。

由于每个block中最多只能保存492字节的数据,故而T1事务的762字节需要分布在两个block中,第一个block保存492字节的数据,第二个block中保存剩余270字节的数据。
- 其中,左侧的block,其
LOG_BLOCK_FIRST_REC_GROUP值为12,代表第一个record开始的位置紧接在log block header之后 - 而右侧的block,其
LOG_BLOCK_FIRST_REC_GROUP的值为12 + 270 = 282 bytes。在存放第一条record之前,不仅有log block header对应的12字节,还有之前T1剩余日志的270字节
LOG_BLOCK_CHECKPOINT_NO
LOG_BLOCK_CHECKPOINT_NO占用4字节大小,代表log block最后被写入时的检查点第四字节的值。
LSN(log sequence number)为一个全局唯一且单调递增的64位数字,当发生数据修改时,redo log内容会增加,此时LSN也会增加。
CHECKPOINT则是一个LSN值,同样为64位整数,代表位于CHECKPOINT之前所有的修改已经被持久化到数据库中,位于CHECKPOINT之前的redo log内容可以被安全的覆盖。