33 KiB
- Mysql Group Replication
Mysql Group Replication
Mysql Group Replication可以用于创建弹性、高可用、有容错的replication拓扑。
groups可以在single-primary mode下进行执行,其支持自动的primary选举,在同一时刻只有一个server接收更新操作。
另外,groups也支持multi-primary mode部署,此时所有servers都能够接收写操作,即使多个写请求是并行发送的。
MGR存在一个内置的group membership service,其在任一时刻都能为所有servers提供一致且可用的组视图。server可以加入和离开group,group view也会随之改变。在某些时刻,server可能非预期的离开group,在这种情况下failure detection机制将会自动感知并通知group去更新group view。
group replication是作为mysql server的插件被提供的。可以通过Innodb Cluster来部署mysql server instances group。
为了部署多个mysql实例,可以使用Innodb Cluster,其能够通过Mysql Shell轻松的管理mysql server实例组。Innodb Cluster和Mysql Router无缝集成,在应用连接到集群式,无需在应用中编写failover流程。
Group Replication Background
创建有容错性系统的最常用方式是采用冗余组件的方案,即使组件被移除,系统仍可按预期继续运行。这样将会增加系统的复杂性,特别的,replicated databases必须维护和管理多台server;并且,servers以集群的方式对外提供服务,还需要处理其他若干的经典分布式系统问题:如network partition或split brain问题。
mysql group replication提供了distributed state machine replication,并保证了servers间的强协同;server在作为同一group的一部分,会自动的彼此之间进行协调。
对于待提交的事务,majority of group必须就事务在global transactions中的顺序达成一致。决定事务commit或abort是由每个server单独处理的,但是所有server中,该事务提交/回滚状态都完全一致。如果存在network partition,导致members不能就transaction order达成一致,那么系统将不能继续处理,直至该问题被解决。故而,MGR中存在内置、自动的split-brain保护机制。
上述所有内容都由GCS(Group Communication System)协议提供,其提供了如下内容
- 故障检测机制
- group membership service
- safe and completely ordered message delivery
上述所有机制都保证了数据在group of servers之间能够被一致的复制。GCS技术的核心基于Paxos算法实现,其用作group communication engine。
Replication Technologies
传统的mysql replication提供了一种简单的source to replica的复制方法:
- source为primary实例
- replica为secondaries实例
source将会应用事务,并对事务进行提交。之后,事务会异步的被发送到replicas,接收到事务的replica会对事务进行重新执行(statement-based replicaion)或被应用(row-based replication)。在默认情况下,所有的server都拥有数据的完整副本。
默认情况下,mysql的异步replication示例图如下:
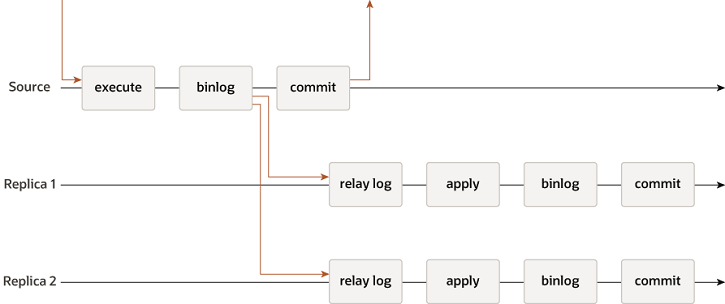
除此之外,还存在半同步的replication,其在协议中添加了同步步骤。示例如下所示,primary会等待replicas接收到事务并向primary返回ack,在接收到ack后才会执行commit操作。
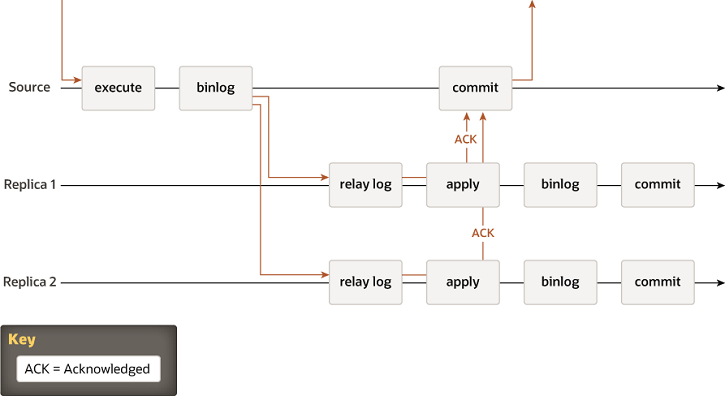
上面两张图为传统的asynchronous MYSQL replication protocol。
group replication
group replication是一种用于实现fault-tolerant系统的技术。replication group是一系列servers的集合,其中每个server都含有数据的完整副本,servers之间通过message进行交互。
group中的communication layer提供了一系列保证,例如atomic message和total order message delivery。
Mysql Group Replication基于这些特性、抽象,实现了multi-source update everywhere replication protocol。一个replication group由多个server组成,每个server在每时每刻都独立的执行事务。
- read/write事务都只在其被group同意之后才提交;即对于read/write事务,都要由整个group决定其是否能被提交,故而提交操作并不是由源服务器单方面决定的。(read/write transaction代表事务中包含写操作的事务)。
- read-only事务则是不需要group内其他server的协助,立刻就能提交
当read/write事务准备好在源server上提交时,都会原子性的广播write values和write set:
- write values:代表被修改后的整行数据
- write set:被修改数据的唯一标识符
由于transaction是被原子广播的,故而,要么group中所有servers都接收到该事务,要么group中所有servers都未收到该事务。并且,对于所有servers,其接收到的所有事务都相同,并且所有事务按照相同的顺序被接收,并且,会为所有事务建立一个global total order。
但是,事务在不同的servers上并行执行时,可能会发生冲突。在被称为certification的过程中,该冲突通过查看和比较两个不同并行事务的write sets来检测。在certification的过程中,冲突检测在行级别执行:如果两个并行的事务在不同的servers上执行,并且修改了相同的行,那么这将会存在冲突。
该冲突将会按照如下方案被解决:对于在global total order中排序靠前的事务,其将会在所有server上被提交;而排序靠后的事务则是会终止,在源服务器上被提交,并且被group中的其他servers丢弃。
例如,t1和t2在不同的servers上并发执行,两者都修改了同一行,t2的排序在t1之前,那么在冲突中t2将会获胜而t1会回滚。上述规则则是分布式的first commit wins rule。
如果两个事务发生冲突的可能性高于不冲突的可能性,那么最好让其在相同的server上执行,并且通过server的local lock机制来对事务进行同步;而不是在不同的server上执行,并因certification造成回滚。
对于已经被认证的事务进行applying和externalizing,group replicaion允许server在不破坏一致性和有效性的前提下偏离agreed order of the transactions。group replication是一个最终一致性的系统,代表incoming traffic降低或停止时,所有的group members都将包含相同的data content。当traffic较高时,事务可以以稍微不同的顺序进行externalizing,并且,事务在进行externalizing时,在一些servers进行externalizing的时机也可能早于其他servers。(externalizing指的即是实际提交事务并使事务的修改对client可见;applying指的是server应用来自其他server的事务修改)。
例如,在mulit-primary模式下,一个本地事务可能在certification之后立马就被externalized,即使一个来自remote server的transaction在global order中顺序更靠前并且尚未被applied。当certification过程中,多个transactions间不涉及冲突时,该操作是被允许的。
在single-primary模式下,在primary server上,可能小概率会发生并发、非冲突的本地事务按照和global order agreed by group replication的顺序进行提交和externalized。
在不接受来自客户端写入操作的secondaries节点上,事务总是按照agreed order被提交和externalized。
具体mysql group replication protocol的示意图如下所示:
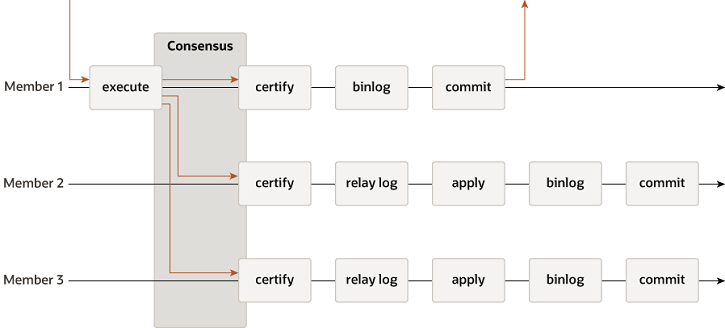
Group replication Use Cases
Group Replication通过将系统状态复制到一组servers,能够创建一个有冗余性的容错系统。即使部分服务器随后fail,只要不是所有或majority发生故障,那么系统仍然可访问。
取决于group中故障server的数量不同,group可能出现性能下降或可拓展性降低的情况,但是整个系统仍然是可用的。server的故障是隔离和独立的,故障由group membership service来进行追踪,其基于分布式的failure detector,该detector能够在任何server自愿退出或异常退出group时发送信号。
在该系统中,无需进行server failover,且multi-source update everywhere的特性确保在单台server故障的场景下,update操作的执行仍然不会受阻。总而言之,mysql group replication保证了数据库服务是持续可用的。
需要认识到的是,即使数据库服务整体是可用的,当server非预期的退出时,连接到该故障server的clients仍然需要被重定向或故障转移到其他server。该处理流程不应由group replication来处理,而是应该由connector/load balancer/router/其他中间件来处理。
总之,mysql group replication提供了一个高可用、高弹性、可靠的mysql服务。
Exmaple Use Cases
如下示例为group replication的典型用例场景:
Elastic Replication: 适用于高灵活度复制结构的环境,servers的数量需要可以动态的增加或缩减,并尽可能的减少副作用Highly Available Shards: sharding是一种实现write scale-out的流行方案,可以使用mysql group replication来实现高可用shards,其中每个shard都被映射到一个replication groupasync source-replica replication的替代方案: 在某些场景下,使用单个source server可能会造成单点争用,向整个group写入在特定场景下则更具有可拓展性(MGR支持多主模式部署,能够在group范围内缓解写压力)
Multi-primary and Single-Primary Modes
Group Replication可以在single-primary或multi-primary模式上工作。该group mode为一个group范围内的配置设置,通过system variable group_replication_single_primary_mode来指定,在所有group members中该variable必须都相同。
ON: 该值代表single-primary mode,也为变量的默认值OFF: 该值代表multi-primary mode
在group中,所有的members其
group_replication_single_primary_mode变量的值都必须相同
在group replication运行时,并无法手动修改group_replication_single_primary_mode的值,但是,在group replication运行时,可以使用group_replication_switch_to_single_primary_mode()和group_replication_switch_to_multi_primary_mode()方法来将group从一个模式切换到另一个模式。这些方法能够修改group的mode,并且确保数据的一致性和安全性。
不管处于哪种mode下,group replciation都不会处理client的failover,其必须由中间件framework例如Mysql Router/proxy/connector/应用本身来处理。
Single-Primary Mode
在single-primary mode(group_replication_single_primary_mode=ON)时,group中只存在一个primary server(被设置为read/write mode)。group中所有其他的members都被设置为read-only mode(super_read_only=ON)。该primary server通常会引导整个集群的启动,所有其他加入到group中的servers都会识别到primary server并且自动被设置为read-only mode.
在single-primary mode时,group replication会强制只有一个server能够向group中写入,相比于multi-primary mode,single-primary mode的数据一致性检查可以不那么严格,DDL statements也无需额外谨慎的处理。
group_replication_enforce_update_everywhere_checks
group_replication_enforce_update_everywhere_checks选项能够启用/禁用对group的严格一致性检查。当在single-primary mode下部署时,或将group的mode修改为single-primary mode时,该system variable的值必须被设置为OFF。
被指定为primary server的member可以按如下方式进行变更:
- 如果该primary正常/非预期退出group,那么新primary的选举将会自动被触发
- 可以通过
group_replication_set_as_primary()方法将指定的member任命为primary - 如果使用
group_replication_switch_to_single_primary_mode()方法将group从multi-primary mode切换为single-primary mode,那么将会自动选举出一个新的primary,或者可以通过方法指定primary
当new primary server被选举出后(自动或手动),岂会被自动设置为read/write状态;并且其他的group members将会变为secondaries,状态变为read-only,具体流程如下图所示:
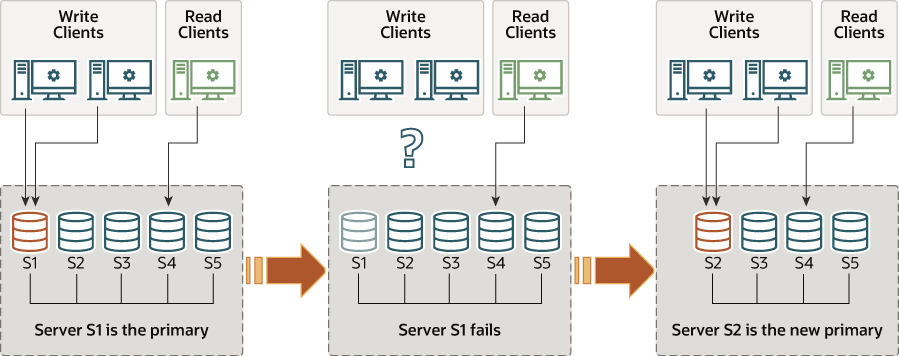
当新primary被选中时,可能会存在部分变更的积压,这些变更已经在old primary中被应用,但是还没有被应用到new primary中。在这种情况下,直到new primary追上old primary之前,read/write transaction可能造成冲突并被回滚,而read-only transaction则可能会读取过时的数据。
通过group replication flow control mechanism,将会将fast member和slow member的差异最小化,在该机制被激活并经合理调优的情况下,可以有效降低该上述情况的发生概率。
group_replication_consistency
可以通过该system variable来设置group的事务一致性级别,从而解决上述问题。
BEFORE_ON_PRIMARY_FAILOVER: 该值为默认值- 将该变量设置为
BEFORE_ON_PRIMARY_FAILOVER或更高级别时,新选举出的primary将会暂时持有新事务,直到primary完成积压changes的applying
- 将该变量设置为
Primary Election Algorithm
自动的primary member选举过程涉及每个member:每个member都会查看group的new view,对潜在的new primary members进行排序,并且选择最合适的member。在每个member的决策过程中,都会独立的在本地进行决策,决策遵循mysql server的primary election algorithm。
由于所有的members都必须就决策达成一致,如果其他group member运行的mysql server版本较低时,members会调整其primary election algorithm,令其行为和group内最低版本的mysql server保持一致。
在members选举primary时,会考虑如下因素,考虑顺序如下:
- 首先考虑的因素为
哪个member运行最低的mysql server version,所有group members都会首先按照mysql server version进行排序 - 如果存在多个members都运行最低的mysql server version,那么第二个考虑的因素为members中每个member的member weight,member weight由
group_replication_member_weight进行指定group_replication_member_weightsystem variable通过一个范围为0-100的数字进行指定,所有members的weight默认为50,该值设置越小,排序越靠后,值设置越大,排序越靠前- 通过weighting function可以令硬件更好的member优先级更高,或在primary计划维护时转移至特定的节点
- 如果存在多个members运行相同的mysql server version,并且多个members都拥有最高的member weight,那么考虑的第三个因素则是每个member UUID的字典序,UUID通过
server_uuidsystem variable来指定。拥有最小server UUID的member将会被选中为primary
Finding the Primary
在部署在single-primary mode下时,如果要找出哪个server为当前的primary,可以通过performance_schema.replication_group_members表中的MEMBER_ROLE来进行判断,示例如下:
mysql> SELECT MEMBER_HOST, MEMBER_ROLE FROM performance_schema.replication_group_members;
+-------------------------+-------------+
| MEMBER_HOST | MEMBER_ROLE |
+-------------------------+-------------+
| remote1.example.com | PRIMARY |
| remote2.example.com | SECONDARY |
| remote3.example.com | SECONDARY |
+-------------------------+-------------+
Multi-Primary Mode
在multi-primary mode(group_replication_single_primary_mode=OFF)下,没有member拥有特殊的role。任何member在加入group时都被设置为read/write模式,即使在并发情况下也能执行write transaction。
如果一个member停止接收write transactions,例如发生非预期的server exit,连接到member的clients将会被重定向或failover到其他的任一处于read/write模式的member。group replciation本身并不会处理client-side failover,可以使用中间件来处理,例如mysql router。
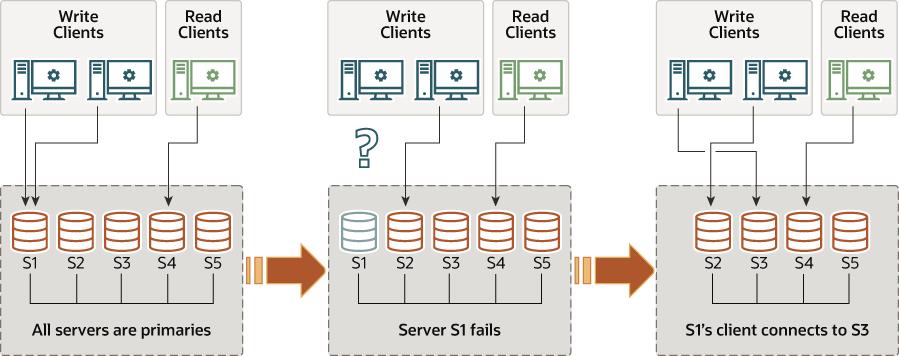
group replication是一个最终一致性的系统,其代表当incoming traffic降低或停止时,所有group members都会包含相同的数据内容。当traffic流动时,某些members对transactions进行externalized的时机可能位于另一些members之前。尤其是某些member的写吞吐可能低于其他member,导致连接到该member的client可能读取到过时数据。
在multi-primary mode下,较慢的member也可能会积累过多的待认证事务和待applying的事务,导致冲突和认证失败的风险更高。为了限制该问题,可以采用group replication的flow control mechansim机制来最小化fast member和slow member的差异。
如果想要为group中的每个事务提供一致性保证,可以使用group_replication_consistency系统变量实现。可以根据group中工作负载和数据读写的优先级来选择合适的设置,同时应考虑提升一致性所引入的同步操作对性能带来的影响。可以针对独立的session来设置该系统变量,从而保护对并发性敏感的事务。
Transaction checks
当group在multi-primary mode下部署时,事务将会被校验,确保其和该模式兼容。如下strict consistency checks将会在multi-primary部署模式下被校验:
- 如果事务在SERIALIZABLE的隔离级别下被执行,那么在
synchronizing itself with the group时(指通过原子广播向group发送write set和write values时),提交操作将会失败 - 如果事务执行时目标table拥有级联约束,那么在
synchronizing itself with the group时,其提交将会失败- 如果在MGR中允许级联,在不同的members中,级联操作影响的行可能有不同,这样会影响members中数据的一致性
上述校验通过group_replication_enforce_update_everywhere_checks的system variable来进行控制。在multi-primary mode的场景下,system variable应该被设置为ON,但是该校验可以被关闭,通过将system variable设置为OFF。当在single-primary模式下部署时,system variable必须被设置为OFF
Data Definition Statements
在Group Replication在multi-primary模式下的拓扑中,需要额外关注DDL的执行场景。
mysql 8.4支持atomic ddl,ddl语句的执行要么提交、要么删除,类似一个原子的事务。对于DDL语句,无论其是否是原子的,都会隐式的终止当前session中活跃的事务,如同在执行ddl statements之前执行了COMMIT。这将代表,DDL statements无法在另一事务中执行,也无法在start transaction ... commit中执行,更无法将多个ddl statements整合在一个事务中执行。
Group Replication基于的是乐观的replication范式,statements首先会被乐观的执行,并且在后续有需要时回滚。每个server在执行statements之前,不会先确保在group内达成共识。故而,在multi-primary mode下,对DDL进行复制需要更加注意。
如果在执行DDL对schema进行变更时,也对同一张表的数据执行了DML变更,那么在DDL变更被完成并复制到所有members之前,需要确保DML操作在同一个server上被处理。
如果没有确保上述行为,那么可能会导致数据的不一致性,从而导致操作被中断或被部分完成。
但是,当group通过single-primary模式被部署时,该问题则不会发生,所有修改操作都会被发送到同一server,即primary server。
Version Compatibility
为了实现最佳兼容性和性能,group中的所有members都应当运行在相同的mysql server版本下,从而保证相同版本的group replication。在multi-primary mode下,该要求将更加重要,因为所有加入到group的members都处于read/write模式。如果group中的成员运行了多个mysql版本,则存在部分成员和其他成员不兼容的风险,不同版本成员之间支持的方法可能有所不同。
为了防范上述问题,当新member加入到group时(包含之前的member被升级或重启的场景),该member将会对group中的其他members进行兼容性检查。
在multi-primary mode下,兼容性检查的结果尤为重要。如果新加入member运行的mysql server版本比当前group中member最小的版本号更高,那么其将以read-only的模式加入到group中。
如果group运行在multi-primary mode下,使用了不同的mysql server versions,group replication将自动管理memebers的read/write和read-only状态。如果member离开group,那么离开后当前运行最低版本的members将会自动被设置为read/write模式。
如果将运行在single-primary mode下的group修改为在multi-primary下运行,那么可以使用group_replication_switch_to_multi_primary_mode()方法,group replication将会自动将members设置为正确的模式。并且,对于运行的版本比lowest-version高的members,其状态将会被自动设置为read-only,而运行lowest-version则将会被设置为read/write状态。
Group Membership
在mysql group replication中,多个servers组成了replication group。group拥有UUID形式的名称。group是动态的,server可以在任何时刻加入/离开group。在server加入或离开group时,group能够对自身进行调整。
如果server加入到group,其会自动从现存的server处拉取最新的状态,令自身保持最新状态。如果server离开group(例如因维护而下线),那么剩余的servers将会监测到server已经离开,并且自动对group进行reconfigure。
group replication中拥有一个group membership service,其定义了哪些servers处于online状态并加入到group。online servers的列表被称为view。group中每个server都拥有一致的view,能够获知给定时刻哪些servers作为group中的members是活跃的。
group members不仅需要对事务的提交达成一致,也需要对当前的view达成一致。如果现有members认同一个新的server应该成为group的一部分,那么group将被reconfigure,并将该server纳入group,这也将触发view的变更。如果server离开group,不管是主动还是非预期退出,group将会动态调整配置并且触发view的变更。
如果member自愿离开group,那么其首先会触发动态的group reconfiguration,在此期间所有的members都应该就new view without the leaving server达成一致。
但是,如果member非预期的退出group(例如因网络连接中断而停止运行),则非预期退出的member无法发起reconfiguration。在该场景下,group replication的failure detection mechanism将会在member离开的短暂时间期间之后检测到该退出行为,并且提出a reconfiguration of the group without the failed member。
当member主动离开group时,reconfiguration需要majority of servers达成一致,但是如果该group无法达成一致(例如因为网络分区导致在线servers数量没有达到majority),那么系统将无法动态的更改configuration;为了防止split-brain场景,系统会处于阻塞状态。对于该种情况,需要管理员的干预。
对于member而言,下线一小段时间,并且在failure detection mechanism探知到该failure前尝试重新加入group是可能的,此时group也不会reconfigre并移除该member。在该场景下,重新加入group的member将会忘记之前的状态,但是,若存在其他members发送给其崩溃前状态的消息,这将可能会造成数据不一致的问题。
为了检测这种情况,MGR会检测相同server的新实例(server address和port号相同)想要加入到group,而server的旧实例也被作为member的场景。那么,在这种情况下,新实例的加入操作将会被阻塞,直到旧实例可以通过reconfiguration被移除。
group_replication_member_expel_timeout
通过group_replication_member_expel_timeout的system variable,引入了一个waiting period,允许members该时间内重新连接到group,从而避免被从group中驱逐。如果member在该时间范围内重新连接到了group,那么该member可以重新在group中处于活跃状态。但是,当member超过expel timeout并且从group中被驱逐时,或通过STOP GROUP_REPLICATION语句停止group replication时,或server failure时,其必须作为新的实例加入到group中。
Failure detection
group replication failure detection mechanism是一个分布式的service,用于检测group中server没有和其他servers沟通的情况,从而判定该server有停止服务的嫌疑。如果在group的共识中该嫌疑为true,那么group将会做出协调一致的决定,将该member逐出group。
将不参与communicating的member驱逐出group是必要的,因为group在对transaction或view change需要majority of members达成一致。如果member不参与这些决策,group必须对member进行移除,从而增加group中包含majority of correctly working members的可能性,从而能够继续处理transactions。
在replication group中,每两个member间都有一个point-to-point的communication channel,从而形成了一个full connected graph。这些连接通过group communication engine(XCom, a Paxos variant)来进行管,连接使用TCP/IP sockets。
如果member经过5s都没有从另一个member处接收到消息,那么其会假设另一个member已经处于failed状态,并且在其自己的performance_schema.replication_group_members中将failed member的状态标记为UNREACHABLE。通常来说,两个member都会假定对方failed,因为二者之间没有进行通信。但是,有小概率存在如下场景:member A假定member B处于failed状态,但是member B仍然认为member A正常;这可能是由routing和firewall导致的问题。当member被group的其他members怀疑时,其将假设所有的其他members都已经失败。
如果怀疑持续超过10s,那么发出怀疑的member将会尝试将被怀疑member可能已经失败的观点传播给group中的其他members。如果member实际上和group中的其他members隔离,其会尝试传播其view,但是该传播不会产生任何后果,因为其无法让其view与其他members达成共识。
怀疑只会在满足如下条件时生效:
- memeber是notifier
- 怀疑持续的时间足够长,可以被传播到group中的其他members
- group中其他的members就该怀疑达成一致
在该种场景下,被怀疑member将会根据协调决策被标记为从group中移除的状态,并且在等待group_replication_member_expel_timeout后,由移除机制检测到并执行移除操作。
Fault-tolerance
mysql group replication基于Paxos分布式算法来实现,为servers间提供了分布式协调。故而,其需要majority of servers处于活跃状态,从而参与决策。这直接影响了系统可以容忍的failures个数。
当server的数量为2*f+1时,其能够容忍f个failures
故而,能够影响1个failure的group必须含有3个servers。当一个server失败时,剩下的2个servers仍然能够形成majority(2~3),并允许系统继续执行决策。但是,当故障的server达到两台时,group将会陷入阻塞状态,因无法达成majority的决策条件。
下表展示了不同group规模下可容忍的failures数量和形成majority的数量
| group size | majority | instant failures tolerated |
|---|---|---|
| 1 | 1 | 0 |
| 2 | 2 | 0 |
| 3 | 2 | 1 |
| 4 | 3 | 1 |
| 5 | 3 | 2 |
| 6 | 4 | 2 |
| 7 | 4 | 3 |
若group size为n,各指标计算公式如下:
majority:floor(n/2)+1tolerated failures:n - floor(n/2) - 1
Observability
在group replication plugin中,存在大量的自动功能,但是,有时需要对其进行观测。故而,整个系统的状态(包括view、冲突数据、service状态)可以通过performance_schema的表来查询。replication protocol的分布式特性以及servers就元数据和事务达成一致并同步的事实,使得检查group状态变得更加容易。
例如,可以通过连接到single server并通过select语句查询performance_schema中对应的表来获取local information和global information。
group replication plugin architecture
mysql group replication是mysql plugin,其基于现存的mysql replication结构构建,利用了binary log、row-based logging、global transaction identifiers等特性。其和当前mysql的框架做了集成,例如performance_schema、plugin和service结构。下图展示了mysql group replication的架构:
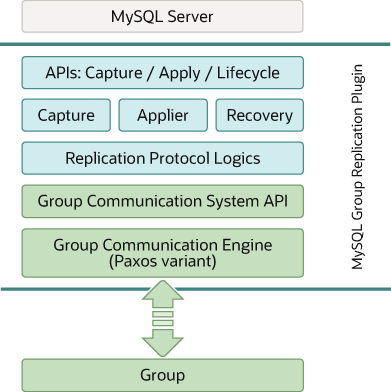
APIs for Capture, Apply, Lifecycle
mysql group replication plugin包含了一系列用于capture、apply、lifecycle的API,其可以用于控制plugin和mysql server的交互。存在令消息在server和plugin之间双向流动的接口,这些接口将mysql server core和group replication plugin进行了隔离,并且接口大部分都是位于事务执行pipeline的hooks。
在server到plugin的方向,存在如下事件通知:
- server starting
- server recovering
- server being ready to accept connections
- server being about to commit a transaction
在plugin到server的方向,plugin会指示server去执行一些操作,例如对正在执行中的事务进行提交/回滚,将事务放入relay log中排队
components
再group replication plugin的再下一层,则是一系列components,对被路由给其的notification进行响应。
- capture component负责对执行事务的上下文进行跟踪
- applier component负责再database执行远程事务
- recovery component用于管理分布式recovery,并负责将加入到group的server更新到最新
protocol
再下一层,则是replciation protocol module,包含了replication protocol的特定逻辑。其处理冲突检测,接收事务并将事务传播给group。
GCS API/XCom
最后两层则是GCS API和基于Paxos实现的group communication engine(XCom)。
GCS API是高层API,对构建replicated state machine所需的属性进行了抽象,其将消息曾的实现和插件的上层进行了解耦。
group communication engine则是负责处理replication group中members的通信。
Getting Started
mysql group replication为mysql server提供了插件。在group中,每个server都需要配置并安装插件。
Deploying Group Replication in Single-Primary Mode
在group中,每个mysql server都可以运行在一台独立的物理host machine上,这也是部署group replication推荐的方式。本次介绍了如何创建一个拥有3个server实例的replication group,每个实例都运行在一个不同的host machine上。
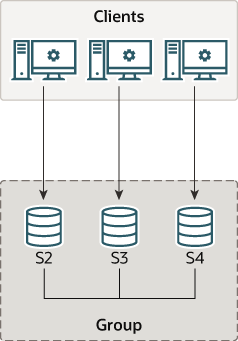
上述为replication group的结构示意图。
Deploying Instances for Group Replication
在本示例中,group中会包含3个实例,也是创建group所需的最少示例数。为group增加更多的实例能够提升group的fault tolerance。
当group中包含3个实例时,group可以容忍一个实例的失败。通过向group中添加更多实例,group可容忍的失败实例数量也会增加。group中可以使用的最大实例数量为9.