# 事务
## 事务分类
事务通常可分为如下类型:
- 扁平事务(flat transaction)
- 带保存点的扁平事务(flat transaction with savepoints)
- 链事务(chained transaction)
- 嵌套事务(nested transaction)
- 分布式事务(distributed transaction)
### 扁平事务
扁平事务为最常用的事务,在扁平事务中,所有操作都处于统一层次,其由`begin work`开始,并由`commit work`或`rollback work`结束。
扁平事务的操作是原子的,要么都提交,要么都回滚。
### 带有保存点的扁平事务
对于带有保存点的扁平事务,`其支持在事务执行过程中回滚到同一事务中较早的一个状态`。
在事务执行过程中,可能并不希望所有的操作都回滚,放弃所有操作的代价可能太大。通过`保存点`,可以记住事务当前的状态,在后续发生错误后,事务能够回到保存点当时的状态。
相较于扁平事务只能够全部回滚,带保存点的扁平事务能够回滚到保存点时的状态。
保存点可以通过`save work`来创建,使用示例如下所示
 ### 链事务
可视为保存点事务的一个变种。在使用带保存点的事务时,如果系统发生崩溃,那么所有的保存点都会消失。`在后续重启进行恢复时,事务需要从开始处重新执行`,而不是从最近的一个保存点开始执行。
> 若事务在数据库未提交时发生崩溃,那么在数据库再次重启执行recovery操作时,会对未提交的事务进行回滚,即使之前事务存在保存点,也会全部回滚
链事务的思想是,当提交事务时,释放不必要的数据对象,将必要的上下文隐式传递给下一个要开始的事务。`提交事务和开始下一个事务操作必须为原子操作`,下一个事务必须徐要能看到上一个事务的结果,示例如下:
### 链事务
可视为保存点事务的一个变种。在使用带保存点的事务时,如果系统发生崩溃,那么所有的保存点都会消失。`在后续重启进行恢复时,事务需要从开始处重新执行`,而不是从最近的一个保存点开始执行。
> 若事务在数据库未提交时发生崩溃,那么在数据库再次重启执行recovery操作时,会对未提交的事务进行回滚,即使之前事务存在保存点,也会全部回滚
链事务的思想是,当提交事务时,释放不必要的数据对象,将必要的上下文隐式传递给下一个要开始的事务。`提交事务和开始下一个事务操作必须为原子操作`,下一个事务必须徐要能看到上一个事务的结果,示例如下:
 和带保存点的扁平事务不同的是,带保存点的扁平事务能够回滚到任意正确的保存点,而链事务只能回滚当前事务。
且链事务和带保存点的扁平事务,对于锁的处理也不同:
- `链事务`:对于每个事务,commit后释放持有的锁
- `带保存点的扁平事务`:在整个事务提交前,不会释放持有的锁
### 嵌套事务
嵌套事务为一个层次结构框架,由顶层事务控制各个层次的事务。嵌套在顶层事务中的事务被称为`子事务`。
和带保存点的扁平事务不同的是,带保存点的扁平事务能够回滚到任意正确的保存点,而链事务只能回滚当前事务。
且链事务和带保存点的扁平事务,对于锁的处理也不同:
- `链事务`:对于每个事务,commit后释放持有的锁
- `带保存点的扁平事务`:在整个事务提交前,不会释放持有的锁
### 嵌套事务
嵌套事务为一个层次结构框架,由顶层事务控制各个层次的事务。嵌套在顶层事务中的事务被称为`子事务`。
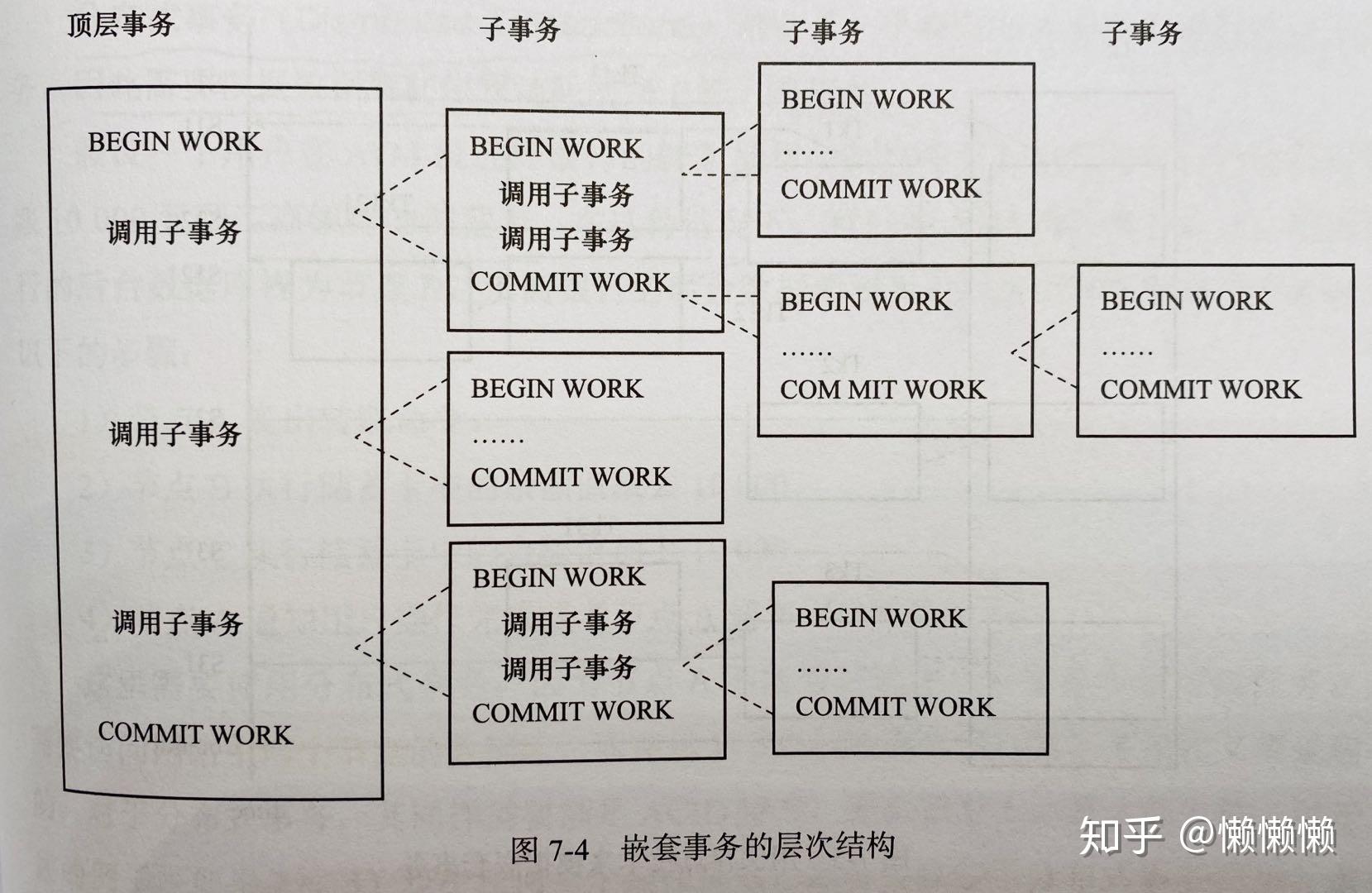 如下为Moss理论嵌套事务的定义:
- 嵌套事务是由若干事务组成的一颗树,子树既可以是嵌套事务,又可以是扁平事务
- 处在叶子节点的事务是扁平事务
- 位于根节点的事务被称为顶层事务,其他事务被称为子事务,事务的`predecessor`被称为父事务,事务的下一层事务被称为子事务
- 子事务既可以提交又可以回滚,但是子事务的提交并不会立马生效,除非其父事务已经被提交。`任何子事务都在顶层事务提交后才真正提交`
- 树中任何一个事务的回滚会引其所有子事务都一起回滚
在Moss理论中,实际工作被交由叶子节点来完成,`只有叶子节点的事务才能够访问数据库,发送消息,获取其他类型的资源`。`高层事务仅仅负责逻辑控制,即负责何时调用相关子事务`。
即使一个系统不支持嵌套事务,也可以通过保存点技术来模拟嵌套事务。
#### savepoint和嵌套事务区别
在使用保存点来模拟嵌套事务时,在锁持有方面和嵌套事务有差别。
- 嵌套事务:在使用嵌套事务时,不同子事务在数据库持有的锁不同
- 保存点:在通过保存点来模拟嵌套事务时,用户无法选择哪些锁被哪些子事务继承,无论有多少个保存点,所有的锁都可以得到访问
### 分布式事务
通常是在分布式环境运行的扁平事务,需要访问网络中的不同节点。
分布式事务同样需要满足ACID的特性,要么都发生,要么都不发生。
对于innodb存储引擎,其支持扁平事务、带有保存点的扁平事务、链事务、分布式事务。`innodb并不原生支持嵌套事务,单可以通过带保存点的事务来模拟串行的嵌套事务`。
## 事务实现
对于事务的ACID特性,其实现如下:
- `I(隔离性)`:事务隔离性通过锁来实现
- `A(原子性), D(持久性)`:事务的原子性和持久性可以通过redo log来实现
- `C(一致性)`:事务一致性通过undo log来实现
### redo
redo log(重做日志)用于实现事务的持久性,其由两部分组成:
- 内存中的重做日志缓冲(redo log buffer)
- 磁盘中的重做日志文件(redo log file)
#### redo log persists before transaction committed
innodb存储引擎支持事务,其通过`force log at commit`机制实现事务的持久性,即当事务提交时,必须先将该事务的所有日志写入到磁盘的日志文件中进行持久化,直到该过程完成后事务才提交完成。
> 上述描述中`提交时将事务所有日志写入到磁盘的日志文件中`,这句话中`日志`代表`redo log 和 undo log`。
> - redo log用于保证事务持久性
> - undo log用于帮助事务回滚,也用于mvcc功能
#### redo log和undo log比较
- redo log在mysql server运行时,只会被顺序的写入,server运行时并不会被读取
- undo log则不同,在server运行时可能需要对事务进行回滚或执行mvcc操作,此时可能需要对undo log文件进行`随机读写`
#### redo log和binlog的比较
binglog通常用于对数据库进行`point in time`形式的恢复(从某个时间点起恢复数据)以及主从复制;但是,binlog和redo log的差别如下:
- binlog针对的是mysql数据库级别,不止用于innodb,还用于其他存储引擎
- redo log属于innodb存储引擎级别
- binlog实际记录的是对应sql语句,属于逻辑日志
- redo log实际记录的格式则是物理格式,具体为针对某个页面的物理修改
redo log和 bin log日志写入磁盘的时机也有所不同:
- bin log`仅在事务提交后才进行一次写入`
- redo log`在事务执行过程中也可能发生写入`(redo log buffer满后会写入到磁盘中),故而,redo log file中同一事务写入的redo log内容可能并非是连续的,`多个事务在写入redo log时可能会交叉写入`
#### innodb_flush_log_at_trx_commit
参数`innodb_flush_log_at_trx_commit`用于控制redo log/ undo log刷新到磁盘的策略,该参数默认值为`1`,即事务提交时刷新日志到磁盘。除了默认值之外,还可以为该参数设置如下值:
- 0: 事务提交时不刷新日志到磁盘,仅在master thread中刷新日志到磁盘,master thread中刷新操作每秒触发一次
- 2:事务提交时刷新日志,但是仅将日志写入到文件系统的缓存中,`并不进行fsync操作`
将`innodb_flush_log_at_trx_commit`参数设置为`0`或`2`虽然可以在一定幅度上提高性能,但是会丧失数据库的ACID特性。
#### log block
在innodb中,redo都是以512字节的大小为单位进行存储的,即redo log buffer、redo log file都是以block的形式进行保存,block的大小为512字节。
##### block & atomic
若针对相同的页,redo log的大小大于512字节,那么其会被分割为多个block进行存储。且由于redo log block的大小和磁盘扇区相同,故而在将block时,无需使用double write机制,针对特定的block,起写入为原子的,要么写入成功要么写入失败,不会像页(page)一样存在dirty的情况。
redo log block中包含的内容除了日志本身外,还包含`log block header`和`log block tailer`内容。`log block header + log block content + log block tailer`合计占用512字节,其中,各部分大小如下:
- `log block header`: 12字节大小
- `log block content`: 492字节大小
- `log block tailer`: 8字节大小
如上所示,每个redo log block可实际存储的内容大小为492字节。
##### log block header
log block header大小为12字节,由如下部分组成:
- `LOG_BLOCK_HDR_NO`: 占用4字节
- `LOG_BLOCK_HDR_DATA_LEN`: 占用2字节
- `LOG_BLOCK_FIRST_REC_GROUP`: 占用2字节
- `LOG_BLOCK_CHECKPOINT_NO`: 占用4字节
###### `LOG_BLOCK_HDR_NO`
log buffer由log block所组成,可以将log buffer看作是log block的数组,故而,log block header中`LOG_BLOCK_HDR_NO`起代表当前block在buffer中的位置。
`LOG_BLOCK_HDR_NO`由于表示的是log buffer中的数组小标,故而可知`LOG_BLOCK_HDR_NO`其是递增的,并且可以循环使用。`LOG_BLOCK_HDR_NO`的大小为4字节,但是其首位用作`flush bit`,故而,其可表示的最大长度为`2^31 bytes = 2GiB`。
##### `LOG_BLOCK_HDR_DATA_LEN`
`LOG_BLOCK_HDR_DATA_LEN`大小为2字节,代表`log block`所占用的大小,当log block被写满时,该值为`0x200`,表示当前log block使用完`block`中所有的可用空间,即log block的大小为512字节。
##### `LOG_BLOCK_FIRST_REC_GROUP`
`LOG_BLOCK_FIRST_REC_GROUP`占用2个字节,表示log block中第一个日志所处的偏移量。
`LOG_BLOCK-FIRST_REC_GROUP`的取值可能存在如下场景:
- 该值大小和`LOG_BLOCK_HDR_DATA_LEN`相同,则代表当前block中`不包含新的日志`(即当前block中存储的存储的全是上一block中record的后续部分)
下图表示`事务T1的重做日志占用762字节`,`事务T2的重做日志占用100字节`的场景。
如下为Moss理论嵌套事务的定义:
- 嵌套事务是由若干事务组成的一颗树,子树既可以是嵌套事务,又可以是扁平事务
- 处在叶子节点的事务是扁平事务
- 位于根节点的事务被称为顶层事务,其他事务被称为子事务,事务的`predecessor`被称为父事务,事务的下一层事务被称为子事务
- 子事务既可以提交又可以回滚,但是子事务的提交并不会立马生效,除非其父事务已经被提交。`任何子事务都在顶层事务提交后才真正提交`
- 树中任何一个事务的回滚会引其所有子事务都一起回滚
在Moss理论中,实际工作被交由叶子节点来完成,`只有叶子节点的事务才能够访问数据库,发送消息,获取其他类型的资源`。`高层事务仅仅负责逻辑控制,即负责何时调用相关子事务`。
即使一个系统不支持嵌套事务,也可以通过保存点技术来模拟嵌套事务。
#### savepoint和嵌套事务区别
在使用保存点来模拟嵌套事务时,在锁持有方面和嵌套事务有差别。
- 嵌套事务:在使用嵌套事务时,不同子事务在数据库持有的锁不同
- 保存点:在通过保存点来模拟嵌套事务时,用户无法选择哪些锁被哪些子事务继承,无论有多少个保存点,所有的锁都可以得到访问
### 分布式事务
通常是在分布式环境运行的扁平事务,需要访问网络中的不同节点。
分布式事务同样需要满足ACID的特性,要么都发生,要么都不发生。
对于innodb存储引擎,其支持扁平事务、带有保存点的扁平事务、链事务、分布式事务。`innodb并不原生支持嵌套事务,单可以通过带保存点的事务来模拟串行的嵌套事务`。
## 事务实现
对于事务的ACID特性,其实现如下:
- `I(隔离性)`:事务隔离性通过锁来实现
- `A(原子性), D(持久性)`:事务的原子性和持久性可以通过redo log来实现
- `C(一致性)`:事务一致性通过undo log来实现
### redo
redo log(重做日志)用于实现事务的持久性,其由两部分组成:
- 内存中的重做日志缓冲(redo log buffer)
- 磁盘中的重做日志文件(redo log file)
#### redo log persists before transaction committed
innodb存储引擎支持事务,其通过`force log at commit`机制实现事务的持久性,即当事务提交时,必须先将该事务的所有日志写入到磁盘的日志文件中进行持久化,直到该过程完成后事务才提交完成。
> 上述描述中`提交时将事务所有日志写入到磁盘的日志文件中`,这句话中`日志`代表`redo log 和 undo log`。
> - redo log用于保证事务持久性
> - undo log用于帮助事务回滚,也用于mvcc功能
#### redo log和undo log比较
- redo log在mysql server运行时,只会被顺序的写入,server运行时并不会被读取
- undo log则不同,在server运行时可能需要对事务进行回滚或执行mvcc操作,此时可能需要对undo log文件进行`随机读写`
#### redo log和binlog的比较
binglog通常用于对数据库进行`point in time`形式的恢复(从某个时间点起恢复数据)以及主从复制;但是,binlog和redo log的差别如下:
- binlog针对的是mysql数据库级别,不止用于innodb,还用于其他存储引擎
- redo log属于innodb存储引擎级别
- binlog实际记录的是对应sql语句,属于逻辑日志
- redo log实际记录的格式则是物理格式,具体为针对某个页面的物理修改
redo log和 bin log日志写入磁盘的时机也有所不同:
- bin log`仅在事务提交后才进行一次写入`
- redo log`在事务执行过程中也可能发生写入`(redo log buffer满后会写入到磁盘中),故而,redo log file中同一事务写入的redo log内容可能并非是连续的,`多个事务在写入redo log时可能会交叉写入`
#### innodb_flush_log_at_trx_commit
参数`innodb_flush_log_at_trx_commit`用于控制redo log/ undo log刷新到磁盘的策略,该参数默认值为`1`,即事务提交时刷新日志到磁盘。除了默认值之外,还可以为该参数设置如下值:
- 0: 事务提交时不刷新日志到磁盘,仅在master thread中刷新日志到磁盘,master thread中刷新操作每秒触发一次
- 2:事务提交时刷新日志,但是仅将日志写入到文件系统的缓存中,`并不进行fsync操作`
将`innodb_flush_log_at_trx_commit`参数设置为`0`或`2`虽然可以在一定幅度上提高性能,但是会丧失数据库的ACID特性。
#### log block
在innodb中,redo都是以512字节的大小为单位进行存储的,即redo log buffer、redo log file都是以block的形式进行保存,block的大小为512字节。
##### block & atomic
若针对相同的页,redo log的大小大于512字节,那么其会被分割为多个block进行存储。且由于redo log block的大小和磁盘扇区相同,故而在将block时,无需使用double write机制,针对特定的block,起写入为原子的,要么写入成功要么写入失败,不会像页(page)一样存在dirty的情况。
redo log block中包含的内容除了日志本身外,还包含`log block header`和`log block tailer`内容。`log block header + log block content + log block tailer`合计占用512字节,其中,各部分大小如下:
- `log block header`: 12字节大小
- `log block content`: 492字节大小
- `log block tailer`: 8字节大小
如上所示,每个redo log block可实际存储的内容大小为492字节。
##### log block header
log block header大小为12字节,由如下部分组成:
- `LOG_BLOCK_HDR_NO`: 占用4字节
- `LOG_BLOCK_HDR_DATA_LEN`: 占用2字节
- `LOG_BLOCK_FIRST_REC_GROUP`: 占用2字节
- `LOG_BLOCK_CHECKPOINT_NO`: 占用4字节
###### `LOG_BLOCK_HDR_NO`
log buffer由log block所组成,可以将log buffer看作是log block的数组,故而,log block header中`LOG_BLOCK_HDR_NO`起代表当前block在buffer中的位置。
`LOG_BLOCK_HDR_NO`由于表示的是log buffer中的数组小标,故而可知`LOG_BLOCK_HDR_NO`其是递增的,并且可以循环使用。`LOG_BLOCK_HDR_NO`的大小为4字节,但是其首位用作`flush bit`,故而,其可表示的最大长度为`2^31 bytes = 2GiB`。
##### `LOG_BLOCK_HDR_DATA_LEN`
`LOG_BLOCK_HDR_DATA_LEN`大小为2字节,代表`log block`所占用的大小,当log block被写满时,该值为`0x200`,表示当前log block使用完`block`中所有的可用空间,即log block的大小为512字节。
##### `LOG_BLOCK_FIRST_REC_GROUP`
`LOG_BLOCK_FIRST_REC_GROUP`占用2个字节,表示log block中第一个日志所处的偏移量。
`LOG_BLOCK-FIRST_REC_GROUP`的取值可能存在如下场景:
- 该值大小和`LOG_BLOCK_HDR_DATA_LEN`相同,则代表当前block中`不包含新的日志`(即当前block中存储的存储的全是上一block中record的后续部分)
下图表示`事务T1的重做日志占用762字节`,`事务T2的重做日志占用100字节`的场景。
 由于每个block中最多只能保存492字节的数据,故而T1事务的762字节需要分布在两个block中,第一个block保存492字节的数据,第二个block中保存剩余270字节的数据。
- 其中,左侧的block,其`LOG_BLOCK_FIRST_REC_GROUP`值为12,代表第一个record开始的位置紧接在log block header之后
- 而右侧的block,其`LOG_BLOCK_FIRST_REC_GROUP`的值为`12 + 270 = 282 bytes`。在存放第一条record之前,不仅有log block header对应的12字节,还有之前T1剩余日志的270字节
##### `LOG_BLOCK_CHECKPOINT_NO`
`LOG_BLOCK_CHECKPOINT_NO`占用4字节大小,代表log block最后被写入时的检查点第四字节的值。
LSN(log sequence number)为一个`全局唯一且单调递增的64位数字,当发生数据修改时,redo log内容会增加,此时LSN也会增加`。
CHECKPOINT则是一个LSN值,同样为64位整数,代表位于`CHECKPOINT`之前所有的修改已经被持久化到数据库中,`位于CHECKPOINT之前的redo log内容可以被安全的覆盖`。
##### log block tailer
log block tailer中仅由一个部分组成,即`LOG_BLOCK_TRL_NO`,其值和`LOG_BLOCK_HDR_NO`相同。
#### log group
log group被称为重做日志组,其中包含多个redo log文件,innodb中只有一个log group。
log group只是一个逻辑上的概念,由多个redo log file组成。log group中每个redo log file大小相同。redo log file中存储的是redo log block,`在innodb引擎运行过程中,会将redo log buffer中的log block刷新到磁盘文件中。`
##### redo log buffer刷新到磁盘中的时机
redo log buffer会在如下时机将log block刷新到磁盘中:
- 事务提交时
- log buffer中有一半的内存空间已经被使用时
- log checkpoint时(checkpoint时会导致脏页被刷新到磁盘上,而WAL要求脏页刷新前刷新redo log buffer)
##### WAL
`write-ahead logging`是一种为database系统提供`原子性`与`持久性`的技术。
`write ahead log`是`append-only`的辅助磁盘存储结构,用于crash recovery和transaction recovery。
在使用`WAL`的系统中,在所有的changes被应用到数据库之前,要求changes都被写入到log中。
所以,在innodb中,脏页被刷新到磁盘之前,脏页对应的`newest_lsn`之前的redo log都必须被刷新到磁盘中。`redo log file中最新的lsn必须大于磁盘页文件中最大的lsn`。
在redo log buffer中的log block刷新到redo log file中时,其会追加(append)到redo log file的末尾。当redo log group中的一个文件被写满时,其会接着写入下一个redo log file,其行为称为`round-robin`。
在redo log group中的每个redo log file中,其前2KB(4个log block大小)均不用于存储log block,前2KB内容如下:
- 对于log group中的第一个redo log file,前2KB用于存储如下内容,下列每个部分大小均为一个block:
- log file header
- checkpoint 1
- 空
- checkpoint2
- 对于log group中`非第一个redo log file`,其仅保留开头2KB的空间,但并不保存信息
#### redo log format
innodb中存储管理是基于页的,故而redo log format格式也基于页。
##### redo log头部格式
redo log头部格式通常包含3部分:
- `redo_log_type`: 重做日志类型
- space: 表空间id
- page_no: 页的偏移量
之后redo log body部分,根据重做日志类型的不同会存储不同内容。
#### LSN
LSN代表的是日志序列号,其大小为8字节,且单调递增。`LSN代表事务写入redo log的总字节数`。
##### 页LSN
在每个页的头部,都存在`FIL_PAGE_LSN`,其记录了该页的lsn。在页中,`LSN`代表该页最后刷新时的lsn大小。
FIL_PAGE_LSN在`buffer pool page`和`disk page`中均存在,二者记录的值不同:
- `buffer pool page` header中`FIL_PAGE_LSN`记录的是`内存页最后被修改的LSN`
- `disk page` header中`FIL_PAGE_LSN`记录的是最后被刷新到磁盘的页对应的最大修改LSN
在执行crash recovery过程中,会从CHECKPOINT开始,一直到redo log file末尾,逐条处理redo log record,对于每条redo log record关联的页,会比较`record_lsn`和`FIL_PAGE_LSN`的大小:
- `record_lsn <= FIL_PAGE_LSN`:代表当前redo record对应的修改已经包含在页中,当前redo log record直接跳过即可
- `record_lsn > FIL_PAGE_LSN`:代表当前redo record中的修改不存在于页中,需要对页应用record修改,并在修改完后更新页的`FIL_PAGE_LSN`
##### 查看LSN
可以通过`show engine innodb status`来查看LSN情况,核心数值如下:
- `log sequence number`:代表当前LSN
- `log flushed up to`: 代表已经刷新到磁盘文件中的LSN
- `last checkpoint at`: 代表页已经刷新到磁盘的LSN
#### recovery
innodb在启动时,`不管上次数据库运行是否正常关闭,都会尝试执行恢复`。
`redo log是物理日志,故而恢复速度相较逻辑日志要快得多`,恢复操作仅需从`checkpoint`开始。
例如,对于如下数据表
```sql
create table t (
a int,
b int,
primary key(a),
key(b)
);
```
若执行sql语句
```sql
insert into t select 1,2;
```
在执行时,需要修改如下内容:
- 聚簇索引页(包含数据)
- 辅助索引页
故而,其记录重做日志内容大致为
```
page(2,3), offset 32, value 1,2; # 聚簇索引页
page(2,4), offset 64, value 2; # 辅助索引页
```
由上述示例可知,redo log为物理日志,记录的是对页的物理修改,故而`redo log是幂等的`。
### undo
redo log记录了对页的物理操作,可以用于进行`redo`。而undo和redo不同,undo主要用于对事务的回滚。
undo的存放位置和redo不同:
- redo log存放在redo log file中
- undo log存放在数据库内部的segment中,该segment被称为`undo segment`。`undo段位于共享的表空间内`
#### undo log和redo log差异
- redo log为物理日志,记录的是对页的修改;而undo log则是逻辑日志,对每个insert操作,undo log会生成一个相反的delete,对update也会生成另一个逆向的update
- redo log是全局的,innodb中所有事务都会`向同一个redo log交叉写入`;而undo log则是针对事务的,每个事务都有其自己的undo log chain
#### 非锁定读
除了用于事务回滚外,undo log还可以用于MVCC。当事务A尝试读取一条记录R时,如果记录R已经被另一个事务B占用,那么事务A可以通过undo log读取行数据之前的版本。
上述实现被称为`非锁定读`。
#### undo log的产生会伴随redo log的产生
`undo log其本质仍然是数据`。undo log其存放在表空间的undo segment中,仍然可被可做是数据,而`WAL(write-ahead logging)要求变更被应用到数据库之前,需要先写入日志`。
故而,在生成undo log时,对于undo页的修改也会被记录到redo log中。
#### 存储管理
innodb通过segment来管理undo log,其管理方式如下:
- innodb包含rollback segment
- 每个rollback segment会记录1024个undo log segment
- undo log segment中会进行undo页的申请
- 共享表空间偏移量为5的页会记录所有rollback segment header所在的页
- 偏移量为5的页类型为FIL_PAGE_TYPE_SYS
##### innodb_undo_directory
该参数用于设置rollback segment文件所在的路径,默认为`./`,代表`datadir`。
如果`innodb_undo_directory`变量没有被定义,那么undo tablespace将会被创建再`datadir`下。默认情况下,undo tablespaces文件的名称为`undo_001`和`undo_002`。
##### innodb_rollback_segments
每个undo tablespace支持最大128个rollback segments,`innodb_rollback_segments`变量定义了rolback segments的数量。
每个rollback segments支持的事务数量由`rollback segment中undo slot的数量`和`每个事务需要的undo log数量`来决定。
> 当innodb页大小为16KB时,rollback segment中undo slot的数量为`innodb page size/ 16`,即1024个。
>
> 易知,每个slot占用的大小为`16bit`,即长度为2字节。
>
> 故而,`slot中存放的是指向undo segment的句柄,而不是存放undo segment本身`。
##### innodb_undo_tablespaces
该变量设置了undo tablespaces的数量。
##### purge
在事务提交之后,并不能立刻删除undo log以及undo log所在的页,`其他事务仍有可能通过undo log来还原数据行的之前版本`。故而,在事务提交时,会将undo log放入到一个链表中,交由purge线程来决定是否最终删除undo log以及undo log所在的页。
> purge代表`清空不再被需要的旧版本数据行及其对应的undo log记录。
如果为每一个事务分配一个单独的undo页,那么会非常浪费存储空间。由于事务提交时,所分配的undo页并不能立刻释放,故而,当数据库负载较大时,可能同时存在大量的undo页,会占用相当多的存储空间。
##### undo页的重用设计
在innodb对undo页的设计中,考虑了对undo页的重用。当事务提交时,首先会将undo log放在链表中,然后判断undo页的使用空间是否小于`3/4`。如果是,代表该undo页可以被重用,之后新的undo log会记录在当前undo log的后面。
> 即undo page是可被重用的,当事务提交时,如果undo log的使用空间小于3/4,那么该undo页是可以被重用的,一个undo页中可能包含多个undo log
#### 核心概念
##### rollback segment
undo tablespace由rollback segment构成,每个undo tablespace最多支持128个rollback segment,`innodb_rollback_segments`定义了rollback segments的数量。
##### undo slots
undo slot是rollback segment内的slot,由rollback segment进行管理。
undo slot主要用于关联undo segment,`当事务启动时,系统会从rollback segment中获取一个空闲的undo slot`,`成功获取undo slot后即代表关联了一个undo segment`。
每个undo log slot中会存储一个`page_no`,其指向undo log segment的起始页位置。
##### undo segment
undo segment为undo slot指向的空间,undo segment中包含多个undo pages,而undo segment中则包含了undo log。
#### undo log格式
在innodb存储引擎中,undo log分为如下两种类型:
- insert undo log:
- insert undo log是事务在insert操作中产生的undo log
- 在事务提交之前,事务插入的数据对其他事务不可见;而事务提交之后,事务插入的数据对其他读已提交的事务才可见;故而,insert undo log在事务提交之后不再被需要,因为在读已提交隔离级别下,insert undo log是可见的;在可重复读的隔离级别下,insert undo log则是不可见的,没有中间版本,只能可见/不可见
- 故而,当事务提交之后,即可删除该事务关联的insert undo log
- update undo log
##### insert undo log
在事务提交之后,insert undo log即可被删除,故而无需purge操作。
insert undo log结构如下:
- next:下一个undo log的位置,长度为2字节
- type_cmpl: 记录undo的类型,对于insert undo来说,该值为11。该字段长度为1字节
- undo_no:记录事务的id(压缩后保存)
- table_id: 记录undo log对应的表对象(压缩后保存)
- 记录所有主键的列和值(本次插入的数据,可能多条)
- start:位于undo log尾部,记录undo log的开始位置,长度为2字节
> ##### rollback
> 在执行rollback操作时,可以根据insert undo log中存储的table id,主键列、主键值来定位需要回滚的行数据,直接删除回滚数据即可。
由于每个block中最多只能保存492字节的数据,故而T1事务的762字节需要分布在两个block中,第一个block保存492字节的数据,第二个block中保存剩余270字节的数据。
- 其中,左侧的block,其`LOG_BLOCK_FIRST_REC_GROUP`值为12,代表第一个record开始的位置紧接在log block header之后
- 而右侧的block,其`LOG_BLOCK_FIRST_REC_GROUP`的值为`12 + 270 = 282 bytes`。在存放第一条record之前,不仅有log block header对应的12字节,还有之前T1剩余日志的270字节
##### `LOG_BLOCK_CHECKPOINT_NO`
`LOG_BLOCK_CHECKPOINT_NO`占用4字节大小,代表log block最后被写入时的检查点第四字节的值。
LSN(log sequence number)为一个`全局唯一且单调递增的64位数字,当发生数据修改时,redo log内容会增加,此时LSN也会增加`。
CHECKPOINT则是一个LSN值,同样为64位整数,代表位于`CHECKPOINT`之前所有的修改已经被持久化到数据库中,`位于CHECKPOINT之前的redo log内容可以被安全的覆盖`。
##### log block tailer
log block tailer中仅由一个部分组成,即`LOG_BLOCK_TRL_NO`,其值和`LOG_BLOCK_HDR_NO`相同。
#### log group
log group被称为重做日志组,其中包含多个redo log文件,innodb中只有一个log group。
log group只是一个逻辑上的概念,由多个redo log file组成。log group中每个redo log file大小相同。redo log file中存储的是redo log block,`在innodb引擎运行过程中,会将redo log buffer中的log block刷新到磁盘文件中。`
##### redo log buffer刷新到磁盘中的时机
redo log buffer会在如下时机将log block刷新到磁盘中:
- 事务提交时
- log buffer中有一半的内存空间已经被使用时
- log checkpoint时(checkpoint时会导致脏页被刷新到磁盘上,而WAL要求脏页刷新前刷新redo log buffer)
##### WAL
`write-ahead logging`是一种为database系统提供`原子性`与`持久性`的技术。
`write ahead log`是`append-only`的辅助磁盘存储结构,用于crash recovery和transaction recovery。
在使用`WAL`的系统中,在所有的changes被应用到数据库之前,要求changes都被写入到log中。
所以,在innodb中,脏页被刷新到磁盘之前,脏页对应的`newest_lsn`之前的redo log都必须被刷新到磁盘中。`redo log file中最新的lsn必须大于磁盘页文件中最大的lsn`。
在redo log buffer中的log block刷新到redo log file中时,其会追加(append)到redo log file的末尾。当redo log group中的一个文件被写满时,其会接着写入下一个redo log file,其行为称为`round-robin`。
在redo log group中的每个redo log file中,其前2KB(4个log block大小)均不用于存储log block,前2KB内容如下:
- 对于log group中的第一个redo log file,前2KB用于存储如下内容,下列每个部分大小均为一个block:
- log file header
- checkpoint 1
- 空
- checkpoint2
- 对于log group中`非第一个redo log file`,其仅保留开头2KB的空间,但并不保存信息
#### redo log format
innodb中存储管理是基于页的,故而redo log format格式也基于页。
##### redo log头部格式
redo log头部格式通常包含3部分:
- `redo_log_type`: 重做日志类型
- space: 表空间id
- page_no: 页的偏移量
之后redo log body部分,根据重做日志类型的不同会存储不同内容。
#### LSN
LSN代表的是日志序列号,其大小为8字节,且单调递增。`LSN代表事务写入redo log的总字节数`。
##### 页LSN
在每个页的头部,都存在`FIL_PAGE_LSN`,其记录了该页的lsn。在页中,`LSN`代表该页最后刷新时的lsn大小。
FIL_PAGE_LSN在`buffer pool page`和`disk page`中均存在,二者记录的值不同:
- `buffer pool page` header中`FIL_PAGE_LSN`记录的是`内存页最后被修改的LSN`
- `disk page` header中`FIL_PAGE_LSN`记录的是最后被刷新到磁盘的页对应的最大修改LSN
在执行crash recovery过程中,会从CHECKPOINT开始,一直到redo log file末尾,逐条处理redo log record,对于每条redo log record关联的页,会比较`record_lsn`和`FIL_PAGE_LSN`的大小:
- `record_lsn <= FIL_PAGE_LSN`:代表当前redo record对应的修改已经包含在页中,当前redo log record直接跳过即可
- `record_lsn > FIL_PAGE_LSN`:代表当前redo record中的修改不存在于页中,需要对页应用record修改,并在修改完后更新页的`FIL_PAGE_LSN`
##### 查看LSN
可以通过`show engine innodb status`来查看LSN情况,核心数值如下:
- `log sequence number`:代表当前LSN
- `log flushed up to`: 代表已经刷新到磁盘文件中的LSN
- `last checkpoint at`: 代表页已经刷新到磁盘的LSN
#### recovery
innodb在启动时,`不管上次数据库运行是否正常关闭,都会尝试执行恢复`。
`redo log是物理日志,故而恢复速度相较逻辑日志要快得多`,恢复操作仅需从`checkpoint`开始。
例如,对于如下数据表
```sql
create table t (
a int,
b int,
primary key(a),
key(b)
);
```
若执行sql语句
```sql
insert into t select 1,2;
```
在执行时,需要修改如下内容:
- 聚簇索引页(包含数据)
- 辅助索引页
故而,其记录重做日志内容大致为
```
page(2,3), offset 32, value 1,2; # 聚簇索引页
page(2,4), offset 64, value 2; # 辅助索引页
```
由上述示例可知,redo log为物理日志,记录的是对页的物理修改,故而`redo log是幂等的`。
### undo
redo log记录了对页的物理操作,可以用于进行`redo`。而undo和redo不同,undo主要用于对事务的回滚。
undo的存放位置和redo不同:
- redo log存放在redo log file中
- undo log存放在数据库内部的segment中,该segment被称为`undo segment`。`undo段位于共享的表空间内`
#### undo log和redo log差异
- redo log为物理日志,记录的是对页的修改;而undo log则是逻辑日志,对每个insert操作,undo log会生成一个相反的delete,对update也会生成另一个逆向的update
- redo log是全局的,innodb中所有事务都会`向同一个redo log交叉写入`;而undo log则是针对事务的,每个事务都有其自己的undo log chain
#### 非锁定读
除了用于事务回滚外,undo log还可以用于MVCC。当事务A尝试读取一条记录R时,如果记录R已经被另一个事务B占用,那么事务A可以通过undo log读取行数据之前的版本。
上述实现被称为`非锁定读`。
#### undo log的产生会伴随redo log的产生
`undo log其本质仍然是数据`。undo log其存放在表空间的undo segment中,仍然可被可做是数据,而`WAL(write-ahead logging)要求变更被应用到数据库之前,需要先写入日志`。
故而,在生成undo log时,对于undo页的修改也会被记录到redo log中。
#### 存储管理
innodb通过segment来管理undo log,其管理方式如下:
- innodb包含rollback segment
- 每个rollback segment会记录1024个undo log segment
- undo log segment中会进行undo页的申请
- 共享表空间偏移量为5的页会记录所有rollback segment header所在的页
- 偏移量为5的页类型为FIL_PAGE_TYPE_SYS
##### innodb_undo_directory
该参数用于设置rollback segment文件所在的路径,默认为`./`,代表`datadir`。
如果`innodb_undo_directory`变量没有被定义,那么undo tablespace将会被创建再`datadir`下。默认情况下,undo tablespaces文件的名称为`undo_001`和`undo_002`。
##### innodb_rollback_segments
每个undo tablespace支持最大128个rollback segments,`innodb_rollback_segments`变量定义了rolback segments的数量。
每个rollback segments支持的事务数量由`rollback segment中undo slot的数量`和`每个事务需要的undo log数量`来决定。
> 当innodb页大小为16KB时,rollback segment中undo slot的数量为`innodb page size/ 16`,即1024个。
>
> 易知,每个slot占用的大小为`16bit`,即长度为2字节。
>
> 故而,`slot中存放的是指向undo segment的句柄,而不是存放undo segment本身`。
##### innodb_undo_tablespaces
该变量设置了undo tablespaces的数量。
##### purge
在事务提交之后,并不能立刻删除undo log以及undo log所在的页,`其他事务仍有可能通过undo log来还原数据行的之前版本`。故而,在事务提交时,会将undo log放入到一个链表中,交由purge线程来决定是否最终删除undo log以及undo log所在的页。
> purge代表`清空不再被需要的旧版本数据行及其对应的undo log记录。
如果为每一个事务分配一个单独的undo页,那么会非常浪费存储空间。由于事务提交时,所分配的undo页并不能立刻释放,故而,当数据库负载较大时,可能同时存在大量的undo页,会占用相当多的存储空间。
##### undo页的重用设计
在innodb对undo页的设计中,考虑了对undo页的重用。当事务提交时,首先会将undo log放在链表中,然后判断undo页的使用空间是否小于`3/4`。如果是,代表该undo页可以被重用,之后新的undo log会记录在当前undo log的后面。
> 即undo page是可被重用的,当事务提交时,如果undo log的使用空间小于3/4,那么该undo页是可以被重用的,一个undo页中可能包含多个undo log
#### 核心概念
##### rollback segment
undo tablespace由rollback segment构成,每个undo tablespace最多支持128个rollback segment,`innodb_rollback_segments`定义了rollback segments的数量。
##### undo slots
undo slot是rollback segment内的slot,由rollback segment进行管理。
undo slot主要用于关联undo segment,`当事务启动时,系统会从rollback segment中获取一个空闲的undo slot`,`成功获取undo slot后即代表关联了一个undo segment`。
每个undo log slot中会存储一个`page_no`,其指向undo log segment的起始页位置。
##### undo segment
undo segment为undo slot指向的空间,undo segment中包含多个undo pages,而undo segment中则包含了undo log。
#### undo log格式
在innodb存储引擎中,undo log分为如下两种类型:
- insert undo log:
- insert undo log是事务在insert操作中产生的undo log
- 在事务提交之前,事务插入的数据对其他事务不可见;而事务提交之后,事务插入的数据对其他读已提交的事务才可见;故而,insert undo log在事务提交之后不再被需要,因为在读已提交隔离级别下,insert undo log是可见的;在可重复读的隔离级别下,insert undo log则是不可见的,没有中间版本,只能可见/不可见
- 故而,当事务提交之后,即可删除该事务关联的insert undo log
- update undo log
##### insert undo log
在事务提交之后,insert undo log即可被删除,故而无需purge操作。
insert undo log结构如下:
- next:下一个undo log的位置,长度为2字节
- type_cmpl: 记录undo的类型,对于insert undo来说,该值为11。该字段长度为1字节
- undo_no:记录事务的id(压缩后保存)
- table_id: 记录undo log对应的表对象(压缩后保存)
- 记录所有主键的列和值(本次插入的数据,可能多条)
- start:位于undo log尾部,记录undo log的开始位置,长度为2字节
> ##### rollback
> 在执行rollback操作时,可以根据insert undo log中存储的table id,主键列、主键值来定位需要回滚的行数据,直接删除回滚数据即可。
 ##### update undo log
update undo log针对的是`delete`和`update`操作。在mvcc机制的实现中,需要用到该undo log,故而`update undo log在事务提交后不能立刻删除`。
update undo log的格式如下图所示。
##### update undo log
update undo log针对的是`delete`和`update`操作。在mvcc机制的实现中,需要用到该undo log,故而`update undo log在事务提交后不能立刻删除`。
update undo log的格式如下图所示。
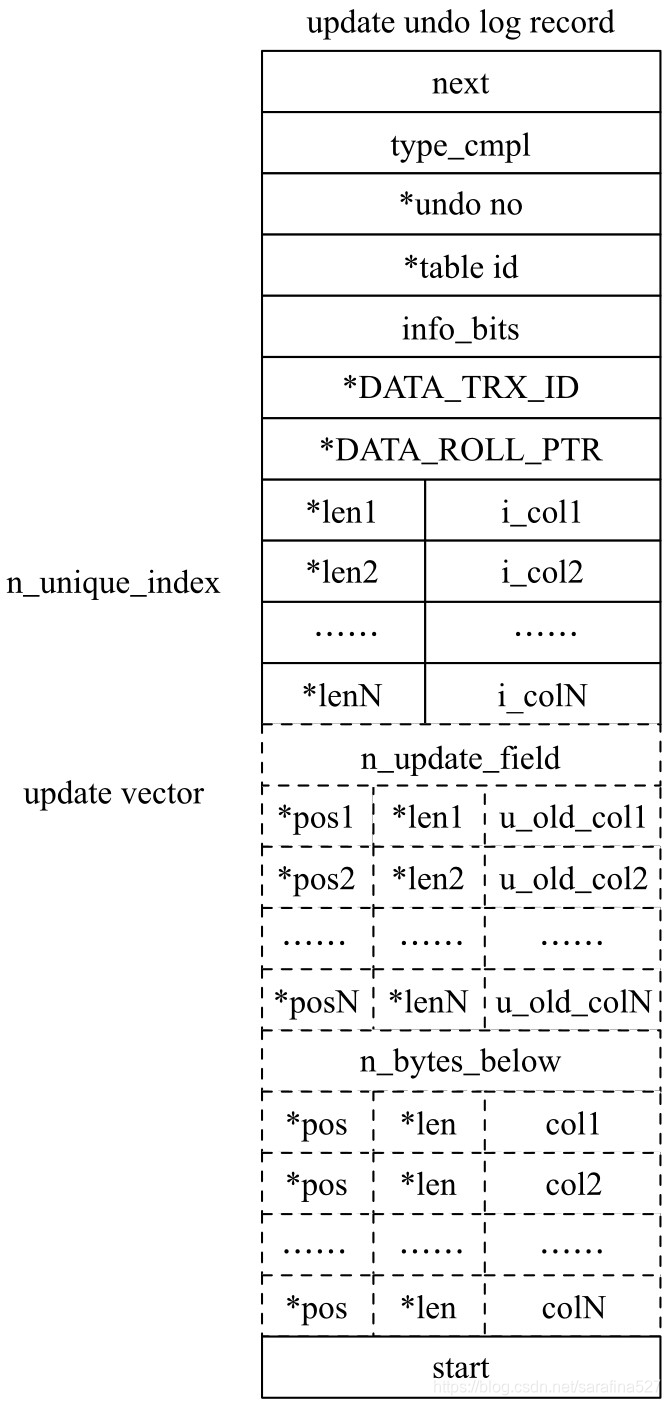 对于update undo log,其哥字段含义如下:
- type_cmpl: 对update undo log,其`type_cmpl`可能的取值如下:
- 12:TRX_UNDO_UPD_EXIST_REC,更新未被标记为delete的记录
- 13:TRX_UNDO_UPD_DEL_REC,更新`已经被标记为delete的记录`
- 14:TRX_UNDO_DEL_MARK_REC,将记录标记为delete
- update vector: update vector中记录了update操作导致发生改变的列,每个被修改的列信息都记录在undo log中。
> 在执行delete操作时,并不会直接对行数据进行物理删除操作,而是`将行数据标记为delete`,待后续purge操作中才会实际对数据进行物理删除。
undo log中主要存储旧的col值,用于在回滚或mvcc时为undo操作提供信息,还原数据先前的版本。
在实际生成insert/update undo log时,对于插入、更新、删除等操作,其实际生成undo log的方式如下:
- insert操作:
- 对于insert操作,其实际生成一条insert undo log,`type_cmpl`的值为`TRX_UNDO_INSERT_REC`
- delete操作:
- 对于delete操作,其实际生成一条`type_cmpl`值为`TRX_UNDO_DEL_MARK_REC`的undo log
- delete操作并不会直接对记录进行物理删除,而是将记录标记为delete,后续进行purge操作时才会实际删除
- update记录的非主键值:
- 在对记录的非主键值进行update时,会生成一条`type_cmpl`值为`TRX_UNDO_UPD_EXIST_REC`的记录,用于对更新操作进行回滚
- update记录的主键值
- 当对记录主键列进行修改时,会生成两条undo log:
- `TRX_UNDO_DEL_MARK_REC`类型的记录,对应`将原记录标记为删除`的回滚
- `TRX_UNDO_INSERT_REC`类型的记录,标记对`新纪录`的插入回滚
> 对于insert/update undo log record,每条undo record均只针对一条记录。故而,当一条sql语句对多行记录进行删除/更改时,会生成多条insert/update undo record。
### undo log组织形式
上述内容介绍了undo log record的格式,为了对undo log records进行高效率的访问和管理,undo log record应当以适当的形式被组织。
#### undo log的逻辑组织方式
每个事务都会修改一系列的records,并产生相应的undo log records,事务对应的undo log由这些undo log records组成。
undo log除了由undo log record组成外,其还包含了一个undo log header,结构如下:
对于update undo log,其哥字段含义如下:
- type_cmpl: 对update undo log,其`type_cmpl`可能的取值如下:
- 12:TRX_UNDO_UPD_EXIST_REC,更新未被标记为delete的记录
- 13:TRX_UNDO_UPD_DEL_REC,更新`已经被标记为delete的记录`
- 14:TRX_UNDO_DEL_MARK_REC,将记录标记为delete
- update vector: update vector中记录了update操作导致发生改变的列,每个被修改的列信息都记录在undo log中。
> 在执行delete操作时,并不会直接对行数据进行物理删除操作,而是`将行数据标记为delete`,待后续purge操作中才会实际对数据进行物理删除。
undo log中主要存储旧的col值,用于在回滚或mvcc时为undo操作提供信息,还原数据先前的版本。
在实际生成insert/update undo log时,对于插入、更新、删除等操作,其实际生成undo log的方式如下:
- insert操作:
- 对于insert操作,其实际生成一条insert undo log,`type_cmpl`的值为`TRX_UNDO_INSERT_REC`
- delete操作:
- 对于delete操作,其实际生成一条`type_cmpl`值为`TRX_UNDO_DEL_MARK_REC`的undo log
- delete操作并不会直接对记录进行物理删除,而是将记录标记为delete,后续进行purge操作时才会实际删除
- update记录的非主键值:
- 在对记录的非主键值进行update时,会生成一条`type_cmpl`值为`TRX_UNDO_UPD_EXIST_REC`的记录,用于对更新操作进行回滚
- update记录的主键值
- 当对记录主键列进行修改时,会生成两条undo log:
- `TRX_UNDO_DEL_MARK_REC`类型的记录,对应`将原记录标记为删除`的回滚
- `TRX_UNDO_INSERT_REC`类型的记录,标记对`新纪录`的插入回滚
> 对于insert/update undo log record,每条undo record均只针对一条记录。故而,当一条sql语句对多行记录进行删除/更改时,会生成多条insert/update undo record。
### undo log组织形式
上述内容介绍了undo log record的格式,为了对undo log records进行高效率的访问和管理,undo log record应当以适当的形式被组织。
#### undo log的逻辑组织方式
每个事务都会修改一系列的records,并产生相应的undo log records,事务对应的undo log由这些undo log records组成。
undo log除了由undo log record组成外,其还包含了一个undo log header,结构如下:
 如上述结构所示,undo log header中包含如下部分:
- trx id: 事务id,用于标识产生该undo log的事务
- trx no: trx no用于表示事务的提交顺序(header中trx no并非一定有值,在事务提交前,该field未定义,当事务提交后,该field会被填充)
- `trx no`用于判断`是否purge应当被执行`
- delete mark: 判断是否undo log中存在`TRX_UNDO_DEL_MARK_REC`类型的undo record,从而在purge时避免扫描
- log start offset: 该field记录了undo log header结尾的位置,便于后续对undo log header进行拓展
- History List Node:undo log通过该结构挂载到History List中
> 故而,undo log就粒度存在两种结构
> - undo record: 记录每行数据的历史版本,行数据通过维护undo record chain来还原历史版本
> - undo log: 针对事务级别,每个undo log由undo log header和多个undo records组成,并且undo log会根据事务的提交顺序被挂载到history list中
##### record versions
如果多个事务针对同一条record进行了修改(串行),那么,每个事务对record造成的修改都会生成不同的版本(version),不同的版本之间通过链表进行链接,用于后续的mvcc,示例如下:
如上述结构所示,undo log header中包含如下部分:
- trx id: 事务id,用于标识产生该undo log的事务
- trx no: trx no用于表示事务的提交顺序(header中trx no并非一定有值,在事务提交前,该field未定义,当事务提交后,该field会被填充)
- `trx no`用于判断`是否purge应当被执行`
- delete mark: 判断是否undo log中存在`TRX_UNDO_DEL_MARK_REC`类型的undo record,从而在purge时避免扫描
- log start offset: 该field记录了undo log header结尾的位置,便于后续对undo log header进行拓展
- History List Node:undo log通过该结构挂载到History List中
> 故而,undo log就粒度存在两种结构
> - undo record: 记录每行数据的历史版本,行数据通过维护undo record chain来还原历史版本
> - undo log: 针对事务级别,每个undo log由undo log header和多个undo records组成,并且undo log会根据事务的提交顺序被挂载到history list中
##### record versions
如果多个事务针对同一条record进行了修改(串行),那么,每个事务对record造成的修改都会生成不同的版本(version),不同的版本之间通过链表进行链接,用于后续的mvcc,示例如下:
 如上所示,事务`I, J, K`都对`id=1`的记录进行了操作,其操作顺序如下:
1. 事务I插入了id为1的记录,并且将`a`的值设置为A
2. 事务J将id为1记录的`a`修改为了B
3. 事务K将id为1记录的`a`修改为了C
事务I, J, K都有其事务对应的undo log,并且每个undo log都拥有对应的undo log header和undo log records。
通过index中的记录及其rollptr引用的链表,可以对记录关联的`I, J, K`三个版本进行还原。
#### 物理组织方式
undo log的结构如上述所示,我们无法控制事务生成undo log的大小(当事务操作大量的数据时,其undo log对应的undo records数量也会变多,undo log大小更大)。但是,`最终生成undo log写入磁盘时,会基于固定的大小进行写入(16KB)`。
由于事务关联`undo log`的大小是无法控制的,其大小可能需要多个页来进行存储。故而,`对占用空间较大的undo log,undo page会按照需要进行分配`;`而对于大小较小的undo log,会将多个undo log放置在同一个undo page中`。
> undo log和undo page的对应关系是灵活的,既可能一个undo log占用多个undo pages,也可能多个undo log共用相同的undo page
关于undo log的物理组织方式,如下图所示:
如上所示,事务`I, J, K`都对`id=1`的记录进行了操作,其操作顺序如下:
1. 事务I插入了id为1的记录,并且将`a`的值设置为A
2. 事务J将id为1记录的`a`修改为了B
3. 事务K将id为1记录的`a`修改为了C
事务I, J, K都有其事务对应的undo log,并且每个undo log都拥有对应的undo log header和undo log records。
通过index中的记录及其rollptr引用的链表,可以对记录关联的`I, J, K`三个版本进行还原。
#### 物理组织方式
undo log的结构如上述所示,我们无法控制事务生成undo log的大小(当事务操作大量的数据时,其undo log对应的undo records数量也会变多,undo log大小更大)。但是,`最终生成undo log写入磁盘时,会基于固定的大小进行写入(16KB)`。
由于事务关联`undo log`的大小是无法控制的,其大小可能需要多个页来进行存储。故而,`对占用空间较大的undo log,undo page会按照需要进行分配`;`而对于大小较小的undo log,会将多个undo log放置在同一个undo page中`。
> undo log和undo page的对应关系是灵活的,既可能一个undo log占用多个undo pages,也可能多个undo log共用相同的undo page
关于undo log的物理组织方式,如下图所示:
 ##### undo segment
每当一个事务开启时,都需要持有一个undo segment,对于undo segment中磁盘空间的释放和占用(对16KB页的释放和占用)都由FSP segment进行管理。
undo segment中会至少持有一个undo page,并且,`每个undo page都会记录undo page header`。
##### undo page header
undo page header中包含如下内容:
- undo page type:undo page的类型
- last log record offset:最后一条记录的offset
- free space offset:page中空闲空间的offset
- undo page list node:指向List中的下一个undo page
undo segment中的第一个undo page除了undo page header外,`还会记录undo segment header`。
##### undo segment header
undo segment header中包含如下内容:
- state:该field记录了udno segment的状态(TRX_UNDO_CACHED/TRX_UNDO_PURGE)
- undo segment中最后一条undo record的位置
- 当前segment被分配的undo page组成的链表
##### undo log storing
undo page中的空间用于存储undo log,对于`大小较小的undo log`innodb会对undo page进行reuse,在undo page中存储多个undo logs避免浪费空间。而对于大小较大的undo log,会使用多个undo page来对该undo log进行存储。(undo page reuse只会发生在segment的第一个page)。
#### 文件组织方式
在同一时刻,一个undo segment只属于一个事务,一个undo segment无法同时被多个事务共享。每当事务开启时,都会获取一个undo segment,故而,在多个事务并行的运行时,需要多个undo segment。
##### rollback segment
在innodb中,每个rollback segment中包含了1024个undo slot,而每个undo tablespace最多包含128个rollback segment。
rollback segment header中包含了128个slot,每个slot包含4字节,并且都指向`某个undo segment的第一页`。
undo slot的数量会影响innodb数据库中的事务并行程度,
#### 内存组织方式
innodb中针对undo log的内存数据奇结构如下:
##### undo segment
每当一个事务开启时,都需要持有一个undo segment,对于undo segment中磁盘空间的释放和占用(对16KB页的释放和占用)都由FSP segment进行管理。
undo segment中会至少持有一个undo page,并且,`每个undo page都会记录undo page header`。
##### undo page header
undo page header中包含如下内容:
- undo page type:undo page的类型
- last log record offset:最后一条记录的offset
- free space offset:page中空闲空间的offset
- undo page list node:指向List中的下一个undo page
undo segment中的第一个undo page除了undo page header外,`还会记录undo segment header`。
##### undo segment header
undo segment header中包含如下内容:
- state:该field记录了udno segment的状态(TRX_UNDO_CACHED/TRX_UNDO_PURGE)
- undo segment中最后一条undo record的位置
- 当前segment被分配的undo page组成的链表
##### undo log storing
undo page中的空间用于存储undo log,对于`大小较小的undo log`innodb会对undo page进行reuse,在undo page中存储多个undo logs避免浪费空间。而对于大小较大的undo log,会使用多个undo page来对该undo log进行存储。(undo page reuse只会发生在segment的第一个page)。
#### 文件组织方式
在同一时刻,一个undo segment只属于一个事务,一个undo segment无法同时被多个事务共享。每当事务开启时,都会获取一个undo segment,故而,在多个事务并行的运行时,需要多个undo segment。
##### rollback segment
在innodb中,每个rollback segment中包含了1024个undo slot,而每个undo tablespace最多包含128个rollback segment。
rollback segment header中包含了128个slot,每个slot包含4字节,并且都指向`某个undo segment的第一页`。
undo slot的数量会影响innodb数据库中的事务并行程度,
#### 内存组织方式
innodb中针对undo log的内存数据奇结构如下:
 ##### undo::Tablespace
对于磁盘中的每个undo tablespace,都会在内存中维护一个`undo::Tablespace`结构,`undo::Tablespace`结构中,最重要的部分是`trx_rseg_t`。
##### trx_rseg_t
`trx_rseg_t`关联了rollback segment header。除了基础元数据之外,其还包含了四个`trx_undo_t`类型的链表:
- Update List: update list中包含`用于记录update undo record的undo segments`
- Update Cached:update cached list中包含可以被重用的update undo segments
- Insert List:insert list中包含了正在使用的insert undo segments
- Insert Cached:isnert cached list中包含了后续可以被重用的insert undo segments
##### trx_undo_t
trx_undo_t关联的则是上面描述的undo segment。
#### undo writing
当一个写事务开启时,将会通过`trx_assign_rseg_durable`分配Rollback Segment,内存中的trx_t也会指向对应的trx_rseg_t内存结构。
rollback segment的分配策略很简单,会依次尝试下一个活跃的rollback segment。在此之后,如果事务内的第一条修改命令需要写undo record,将会调用`trx_undo_assign_undo`来获取undo segment。在获取undo segment时,`trx_rseg_t`中包含的cached list中节点将会被优先使用。sa
### purge
表`t`中,`a`为聚簇索引,`b`为辅助索引,若执行如下sql
```sql
delete from t where a=1;
```
上述语句造成的修改如下:
- 将主键`a`为1的记录标记为delete,将记录`delete flag`设置为1(聚簇索引中的数据并没有被实际物理删除),`且会生成针对聚簇索引的undo log`。当事务发生回滚时,仅需将`delete flag`重新设置为0即可完成对删除的回滚。
- 对于辅助索引中满足`a=1`的记录,同样不会做任何处理,`也不会产生针对辅助索引的undo log`
> undo log只针对聚簇索引生成,对于辅助索引的变化并不会生成对应的undo log。
>
> 从上文的undo log内容来看,update undo log和insert undo log都记录了唯一索引(聚簇索引)的值,并且update undo log记录了各修改列的oldValue,二者均不涉及辅助索引内容。
可知在delete语句执行时,并不会马上就对记录进行物理删除,而是将记录标记为delete,记录实际的删除在purge操作时才被执行。
对于记录的`delete`操作和`update`操作(update主键列时,会先将原记录标记为删除,后插入一条新的记录),会在purge操作中完成。purge确保了innodb存储引擎对于MVCC机制的支持,记录不能再事务提交时立刻进行处理,仍会有其他事务会访问该记录的旧版本。
是否可以对记录进行物理删除由purge来决定,若某行记录不被其他任何事务引用,可以执行物理delete操作。
#### history
innodb存储引擎中维护了一个history列表,其`根据事务的提交顺序`对undo log进行链接,`在history list中,先提交的事务其undo log位于history list的尾端`。
##### undo::Tablespace
对于磁盘中的每个undo tablespace,都会在内存中维护一个`undo::Tablespace`结构,`undo::Tablespace`结构中,最重要的部分是`trx_rseg_t`。
##### trx_rseg_t
`trx_rseg_t`关联了rollback segment header。除了基础元数据之外,其还包含了四个`trx_undo_t`类型的链表:
- Update List: update list中包含`用于记录update undo record的undo segments`
- Update Cached:update cached list中包含可以被重用的update undo segments
- Insert List:insert list中包含了正在使用的insert undo segments
- Insert Cached:isnert cached list中包含了后续可以被重用的insert undo segments
##### trx_undo_t
trx_undo_t关联的则是上面描述的undo segment。
#### undo writing
当一个写事务开启时,将会通过`trx_assign_rseg_durable`分配Rollback Segment,内存中的trx_t也会指向对应的trx_rseg_t内存结构。
rollback segment的分配策略很简单,会依次尝试下一个活跃的rollback segment。在此之后,如果事务内的第一条修改命令需要写undo record,将会调用`trx_undo_assign_undo`来获取undo segment。在获取undo segment时,`trx_rseg_t`中包含的cached list中节点将会被优先使用。sa
### purge
表`t`中,`a`为聚簇索引,`b`为辅助索引,若执行如下sql
```sql
delete from t where a=1;
```
上述语句造成的修改如下:
- 将主键`a`为1的记录标记为delete,将记录`delete flag`设置为1(聚簇索引中的数据并没有被实际物理删除),`且会生成针对聚簇索引的undo log`。当事务发生回滚时,仅需将`delete flag`重新设置为0即可完成对删除的回滚。
- 对于辅助索引中满足`a=1`的记录,同样不会做任何处理,`也不会产生针对辅助索引的undo log`
> undo log只针对聚簇索引生成,对于辅助索引的变化并不会生成对应的undo log。
>
> 从上文的undo log内容来看,update undo log和insert undo log都记录了唯一索引(聚簇索引)的值,并且update undo log记录了各修改列的oldValue,二者均不涉及辅助索引内容。
可知在delete语句执行时,并不会马上就对记录进行物理删除,而是将记录标记为delete,记录实际的删除在purge操作时才被执行。
对于记录的`delete`操作和`update`操作(update主键列时,会先将原记录标记为删除,后插入一条新的记录),会在purge操作中完成。purge确保了innodb存储引擎对于MVCC机制的支持,记录不能再事务提交时立刻进行处理,仍会有其他事务会访问该记录的旧版本。
是否可以对记录进行物理删除由purge来决定,若某行记录不被其他任何事务引用,可以执行物理delete操作。
#### history
innodb存储引擎中维护了一个history列表,其`根据事务的提交顺序`对undo log进行链接,`在history list中,先提交的事务其undo log位于history list的尾端`。