diff --git a/http/http3.md b/http/http3.md
index 69ee764..4d41d65 100644
--- a/http/http3.md
+++ b/http/http3.md
@@ -1,173 +1,173 @@
-- [HTTP3 \& QUIC Protocols](#http3--quic-protocols)
- - [What is HTTP3](#what-is-http3)
- - [TCP/IP模型中HTTP3 vs QUIC](#tcpip模型中http3-vs-quic)
- - [QUIC Protocol](#quic-protocol)
- - [What is QUIC Used For](#what-is-quic-used-for)
- - [HTTP/1.1 vs HTTP/2 vs HTTP/3: Main differences](#http11-vs-http2-vs-http3-main-differences)
- - [Best Features of HTTP/3 and QUIC](#best-features-of-http3-and-quic)
- - [QUIC handshake](#quic-handshake)
- - [0-RTT on Prior Connections](#0-rtt-on-prior-connections)
- - [Head-of-Line Blocking Removal](#head-of-line-blocking-removal)
- - [HOL blocking术语](#hol-blocking术语)
- - [How does QUIC remove head-of-line blocking](#how-does-quic-remove-head-of-line-blocking)
- - [Flexible Bandwidth Management](#flexible-bandwidth-management)
- - [Pre-Stream Flow Control](#pre-stream-flow-control)
- - [拥塞控制算法](#拥塞控制算法)
-
-
-# HTTP3 & QUIC Protocols
-http3旨在通过QUIC(下一代传输层协议)来令网站更快、更安全。
-
-在协议高层,http3提供了和http2相同的功能,例如header compression和stream优先级控制。然而,在协议底层,QUIC传输层协议彻底修改了web传输数据的方式。
-
-## What is HTTP3
-HTTP是一个应用层的网络传输协议,定义了client和server之间的request-reponse机制,允许client/server发送和接收HTML文档和其他文本、meidia files。
-
-http3最初被称为`HTTP-over-QUIC`,其主要目标是令http语法及现存的http/2功能能够和QUIC传输协议兼容。
-
-故而,`HTTP/3`的所有新特性都来源于QUIC层,包括内置加密、新型加密握手、对先前的连接进行zero round-trip恢复,消除头部阻塞问题以及原生多路复用。
-
-## TCP/IP模型中HTTP3 vs QUIC
-通过internet传输信息是复杂的操作,涉及到软件和硬件层面。由于不同的设备、工具、软件都拥有不同的特性,故而单一协议无法描述完整的通信流程。
-
-故而,网络通信是已于通信的协议栈实现的,协议栈中每一层职责都不同。为了使用网络系统来通信,host必须实现构成互联网协议套件的一系列分层协议集。通常,主机至少为每层实现一个协议。
-
-而HTTP则是应用层协议,令web server和web browser之间可以相互通信。http消息(request/reponse)在互联网中则是通过传输层协议来进行传递:
-- 在http/2和http/1.1中,通过TCP协议来进行传递
-- 在`http/3`中,则是通过QUIC协议来进行传递
-
-> `QUIC`为http/3新基于的传输层协议,之前http都基于tcp协议进行传输
-
-## QUIC Protocol
-`QUIC`协议是一个通用的传输层协议,其可以和任意兼容的应用层协议来一起使用,HTTP/3是QUIC的最新用例。
-
-`QUIC`协议基于`UDP`协议构建,其负责server和client之间应用数据的物理传输。UDP协议是一个简单、轻量的协议,其传输速度高但是缺失可靠性、安全性等特性。QUIC实现了这些高层的传输特性,故而可以用于优化http数据通过网络的传输。
-
-在HTTP/3中,HTTP的连接从`TCP-based`迁移到了`UDP-based`,底层的网络通信结构都发生了变化。
-
-### What is QUIC Used For
-QUIC其创建是同于代替`TCP`协议的,QUIC作为传输层协议,相比于TCP更加灵活,性能问题更少。QUIC协议继承了安全传输的特性,并且拥有更快的adoption rate。
-
-QUIC协议底层基于UDP协议的原因是`大多数设备只支持TCP和UDP的端口号`。
-
-除此之外,`QUIC`还利用了UDP的如下特性:
-- UDP的connectionless特性可以使其将多路复用下移到传输层,并且基于UDP的QUIC实现并不会和TCP协议一样存在头部阻塞的问题
-- UDP的间接性能够令QUIC重新实现TCP的可靠性和带宽管理功能
-
-基于QUIC协议的传输和TCP相比是完全不同的方案:
-- 在底层,其是无连接的,其底层基于UDP协议
-- 在高层,其是`connection-oriented`的,其在高层重新实现了TCP协议中连接建立、loss detection等特性,从而确保了数据的可靠传输
-
-综上,QUIC协议结合了UDP和TCP两种协议的优点。
-
-除了上述优点外,QUIC还`在传输层实现了高级别的安全性`。QUIC集成了`TLS 1.3`协议中的大部分特性,令其和自身的传输机制相兼容。在`HTTP/3` stack中,encryption并非是可选的,而是内置特性。
-
-TCP, UDP, QUIC协议的相互比较如下:
-| | TCP | UDP | QUIC |
-| :-: | :-: | :-: | :-: |
-Layer in the TCP/IP model | transport | transport | transport |
-| place in the TCP/IP model | on top of ipv4/ipv6 | on top of ipv4/ipv6 | on top of UDP |
-| connection type | connection-oriented | connectionless | connection-oriented |
-| order of delivery | in-order delivery | out-of-order delivery | out-of-order delivery between streams, in order delivery within stremas |
-| guarantee of delivery | guaranteed | no guarantee of delivery | guaranteed |
-| security | unencrypted | unencrypted | encrypted |
-| data identification | knows nothing about the data it transports | knows nothing about the data it transports | use stream IDs to identify the independent streams it transports |
-
-## HTTP/1.1 vs HTTP/2 vs HTTP/3: Main differences
-H3除了在底层协议栈传输层中引入QUIC和UDP协议外,还存在其他改动,具体如图所示:
-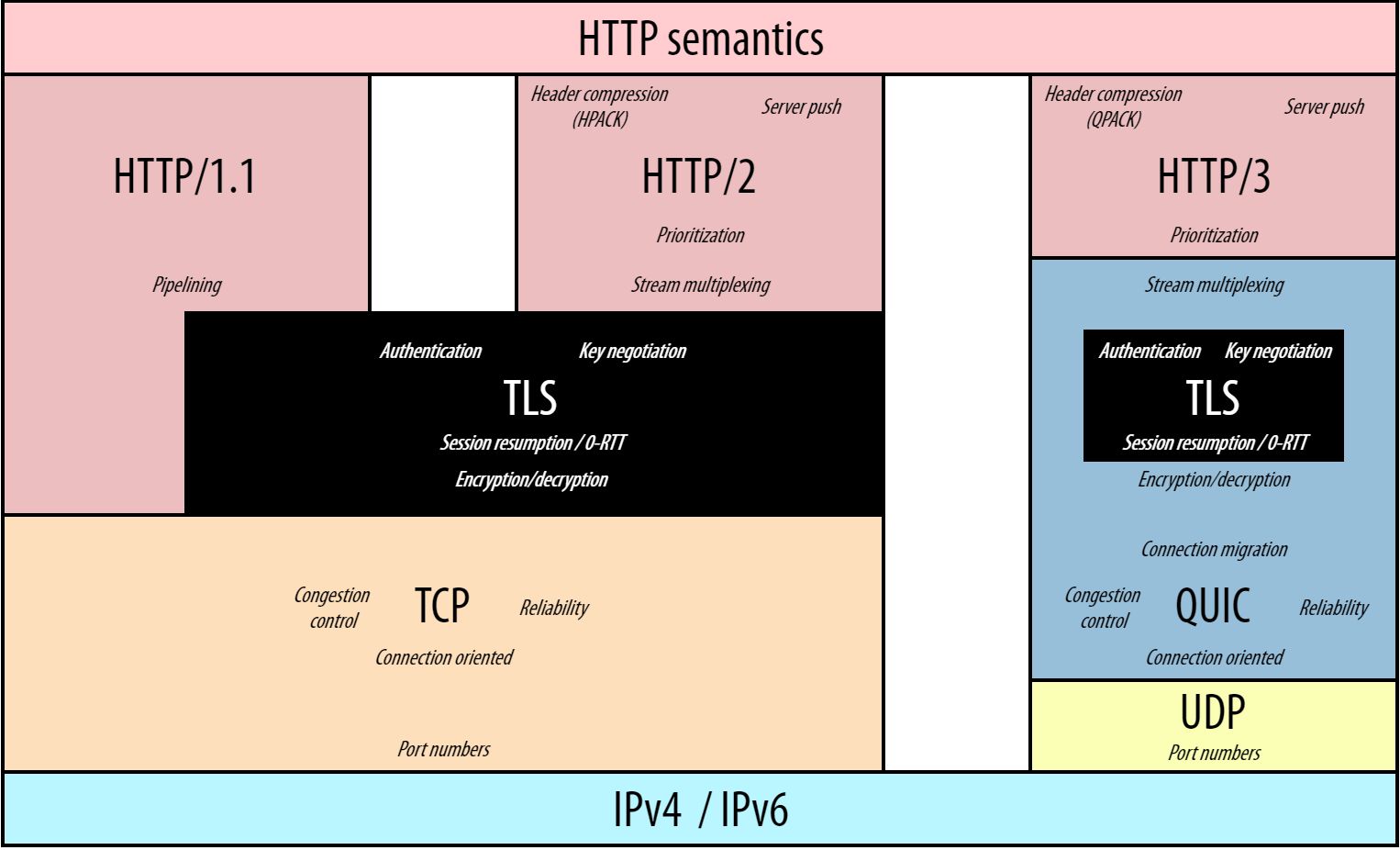 -
-HTTP/3-QUIC-UDP stack和TCP-based版本的HTTP最重要的区别如下:
-- QUIC集成了TLS 1.3协议中绝大部分特性,encryption从应用层移动到了传输层
-- HTTP/3在不同的streams间并不会对连接进行多路复用,多路复用的特性是由QUIC在传输层执行的
- - 传输层的多路复用移解决了HTTP/2中TCP中头部阻塞的问题(HTTP/1.1中并不存在头部阻塞问题,因为其会开启多个TCP连接,并且会提供pipelining选项,后来该方案被发现拥有严重实现缺陷,被替换为了HTTP/2中应用层的多路复用)
-
-## Best Features of HTTP/3 and QUIC
-HTTP/3和QUIC的新特性能够令server connections速度更快、传输更安全、可靠性更高。
-
-### QUIC handshake
-在HTTP2中,client和server在执行handshake的过程中,至少需要2次round-trips:
-- tcp handshake需要一次round-trip
-- tls handleshake至少需要一次round-trip
-
-和QUIC则将上述两次handshakes整合成了一个,HTTP3仅需一次round-trip就可以在client和server之间建立一个secure connection。`QUIC可以带来更快的连接建立和更低的延迟。`
-
-QUIC集成了`TLS1.3`中的绝大多数特性,`TLS1.3`是目前最新版本的`Transport Layer Security`协议,其代表:
-- HTTP/3中,消息的加密是强制的,并不像HTTP/1.1和HTTP/2中一样是可选的。在使用HTTP/3时,所有的消息都默认通过encrypted connection来进行发送。
-- TLS 1.3引入了一个`improved cryptographic handshake`,在client和server间仅需要一次round-trip;而TLS 1.2中则需要两次round-trips用于认证
- - 而在QUIC中,则将该`improved cryptographic handshake`和其本身用于连接创建的handshake进行了整合,并替代了TCP的handshake
-- 在HTTP/3中,消息都是在传输层加密的,故而加密的信息比HTTP/1.1和HTTP/2中都更多
- - 在HTTP/1.1和HTTP/2协议栈中,TLS都运行在应用层,故而HTTP data是加密的,但是,TCP header则是明文发送的,TCP header的明文可能会带来一些安全问题
- - 在HTTP/3 stack中,TLS运行在传输层,故而不仅http message被加密,大多数QUIC packet header也是被加密的
-
-简单来说,HTTP/3使用的传输机制相比于TCP-based HTTP版本来说要更加安全。(传输层协议本身的header也被加密)
-
-### 0-RTT on Prior Connections
-对于先前存在的connections,QUIC利用了TLS 1.3的`0-RTT`特性。
-
-`0-RTT`代表zero round-trip time resumption,是TLS 1.3中引入的一个新特性。
-
-TLS session resumption通过复用先前建立的安全参数,减少建立secure connection所花费的时间。当client和server频繁建立连接并断开时,这将带来性能改善。
-
-通过0-RTT resumption,client可以在连接的第一个round-trip中发送http请求,复用先前建立的cryptographic keys。
-
-下面展示了H2和H3 stack在建立连接时的区别:
-
-
-
-HTTP/3-QUIC-UDP stack和TCP-based版本的HTTP最重要的区别如下:
-- QUIC集成了TLS 1.3协议中绝大部分特性,encryption从应用层移动到了传输层
-- HTTP/3在不同的streams间并不会对连接进行多路复用,多路复用的特性是由QUIC在传输层执行的
- - 传输层的多路复用移解决了HTTP/2中TCP中头部阻塞的问题(HTTP/1.1中并不存在头部阻塞问题,因为其会开启多个TCP连接,并且会提供pipelining选项,后来该方案被发现拥有严重实现缺陷,被替换为了HTTP/2中应用层的多路复用)
-
-## Best Features of HTTP/3 and QUIC
-HTTP/3和QUIC的新特性能够令server connections速度更快、传输更安全、可靠性更高。
-
-### QUIC handshake
-在HTTP2中,client和server在执行handshake的过程中,至少需要2次round-trips:
-- tcp handshake需要一次round-trip
-- tls handleshake至少需要一次round-trip
-
-和QUIC则将上述两次handshakes整合成了一个,HTTP3仅需一次round-trip就可以在client和server之间建立一个secure connection。`QUIC可以带来更快的连接建立和更低的延迟。`
-
-QUIC集成了`TLS1.3`中的绝大多数特性,`TLS1.3`是目前最新版本的`Transport Layer Security`协议,其代表:
-- HTTP/3中,消息的加密是强制的,并不像HTTP/1.1和HTTP/2中一样是可选的。在使用HTTP/3时,所有的消息都默认通过encrypted connection来进行发送。
-- TLS 1.3引入了一个`improved cryptographic handshake`,在client和server间仅需要一次round-trip;而TLS 1.2中则需要两次round-trips用于认证
- - 而在QUIC中,则将该`improved cryptographic handshake`和其本身用于连接创建的handshake进行了整合,并替代了TCP的handshake
-- 在HTTP/3中,消息都是在传输层加密的,故而加密的信息比HTTP/1.1和HTTP/2中都更多
- - 在HTTP/1.1和HTTP/2协议栈中,TLS都运行在应用层,故而HTTP data是加密的,但是,TCP header则是明文发送的,TCP header的明文可能会带来一些安全问题
- - 在HTTP/3 stack中,TLS运行在传输层,故而不仅http message被加密,大多数QUIC packet header也是被加密的
-
-简单来说,HTTP/3使用的传输机制相比于TCP-based HTTP版本来说要更加安全。(传输层协议本身的header也被加密)
-
-### 0-RTT on Prior Connections
-对于先前存在的connections,QUIC利用了TLS 1.3的`0-RTT`特性。
-
-`0-RTT`代表zero round-trip time resumption,是TLS 1.3中引入的一个新特性。
-
-TLS session resumption通过复用先前建立的安全参数,减少建立secure connection所花费的时间。当client和server频繁建立连接并断开时,这将带来性能改善。
-
-通过0-RTT resumption,client可以在连接的第一个round-trip中发送http请求,复用先前建立的cryptographic keys。
-
-下面展示了H2和H3 stack在建立连接时的区别:
-
-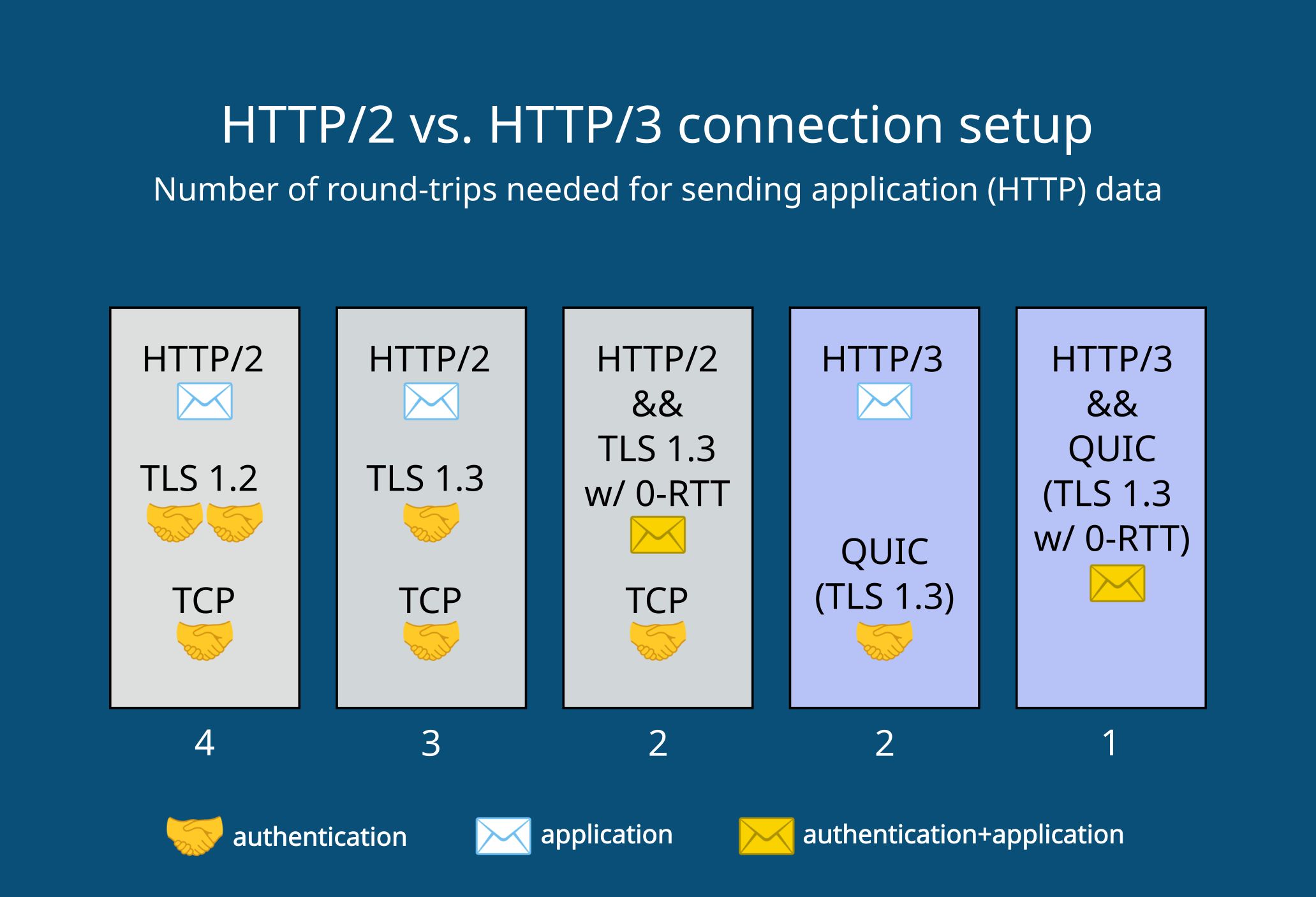 -
-- 当使用HTTP2和TLS 1.2时,client发送第一个http request需要4个round-trip
-- 在使用HTTP2和TLS 1.3时,client发送第一个http equest需要2、3个round-trip(根据是否使用0-rtt有所不同)
-- 在使用HTTP3和QUIC时,其默认包含TLS 1.3,其可以在1、2个round-trip内发送第一个http请求(根据是否复用先前连接的加密信息)
-
-### Head-of-Line Blocking Removal
-HTTP/3协议栈和HTTP/2协议栈的结构不同,其解决了HTTP/2中最大的性能问题:`head-of-line`阻塞。
-- 该问题主要发生在HTTP/2中packet丢失的场景下,直到丢失的包被重传前,整个的数据传输过程都会停止,所有packets都必须在网络上等待,这将会导致页面的加载时间延长
-
-在HTTP/3中,行首阻塞通过原生的多路复用解决了。这是QUIC最重要的特性之一。
-
-#### HOL blocking术语
-如下是HOL问题涉及到的概念:
-- byte stream:是通过网络发送的字节序列。bytes作为不同大小的packets被传输。byte stream本质上是单个资源(file)的物理表现形式,通过网络来发送
-- 复用:通过复用,可以在一个connection上传输多个byte streams,这将代表浏览器可以在同一个连接上同时加载多个文件
- - 在HTTP/1.1中,并不支持复用,其会未每个byte stream新开一个tcp连接。HTTP/2中引入了应用层的复用,其只会建立一个TCP连接,并通过其传输所有byte streams。故而,仅有HTTP/2会存在HOL问题
-- HOL blocking:这是由tcp byte stream抽象造成的性能问题。TCP并不知晓其所传输的数据,并将其所传输的所有数据都看作一个byte stream。故而,如果在网络传输过程中,任意位置的packet发生的丢失,所有在复用连接中的其他packets都会停止传输,并等待丢失的packets被重传
- - 这代表,复用的连接中,所有byte streams都会被TCP协议看作是一个byte stream,故而stream A中的packet丢失也会造成stream B的传输被阻塞,直至丢失packet被重传
- - 并且,TCP使用了in-order传输,如果发生packet丢失,那么将阻塞整个的传输过程。在高丢包率的环境下,这将极大程度上影响传输速度。即使在HTTP/2中已经引入了性能优化特性,在2%丢包率的场景下,也会比HTTP/1.1的传输速度更慢
-- native multiplexing:在HTTP/3协议栈中,复用被移动到了传输层,实现了原生复用。QUIC通过stream ID来表示每个byte stream,并不像TCP一样将所有byte streams都看作是一个。
-
-#### How does QUIC remove head-of-line blocking
-QUIC基于UDP实现,其使用了out-of-order delivery,故而每个byte stream都通过网络独立的进行传输。然而,为了可靠性,QUIC确保了在同一byte stream内packets的in-order delivery,故而相同请求中关联的数据到达的顺序是一致的。
-
-QUIC标识了所有byte stream,并且streams是独立进行传输的,如果发生packet丢失,其他byte streams并不会停止并等待重传。
-
-下图中展示了QUIC原生复用和HTTP2应用层复用的区别:
-
-
-- 当使用HTTP2和TLS 1.2时,client发送第一个http request需要4个round-trip
-- 在使用HTTP2和TLS 1.3时,client发送第一个http equest需要2、3个round-trip(根据是否使用0-rtt有所不同)
-- 在使用HTTP3和QUIC时,其默认包含TLS 1.3,其可以在1、2个round-trip内发送第一个http请求(根据是否复用先前连接的加密信息)
-
-### Head-of-Line Blocking Removal
-HTTP/3协议栈和HTTP/2协议栈的结构不同,其解决了HTTP/2中最大的性能问题:`head-of-line`阻塞。
-- 该问题主要发生在HTTP/2中packet丢失的场景下,直到丢失的包被重传前,整个的数据传输过程都会停止,所有packets都必须在网络上等待,这将会导致页面的加载时间延长
-
-在HTTP/3中,行首阻塞通过原生的多路复用解决了。这是QUIC最重要的特性之一。
-
-#### HOL blocking术语
-如下是HOL问题涉及到的概念:
-- byte stream:是通过网络发送的字节序列。bytes作为不同大小的packets被传输。byte stream本质上是单个资源(file)的物理表现形式,通过网络来发送
-- 复用:通过复用,可以在一个connection上传输多个byte streams,这将代表浏览器可以在同一个连接上同时加载多个文件
- - 在HTTP/1.1中,并不支持复用,其会未每个byte stream新开一个tcp连接。HTTP/2中引入了应用层的复用,其只会建立一个TCP连接,并通过其传输所有byte streams。故而,仅有HTTP/2会存在HOL问题
-- HOL blocking:这是由tcp byte stream抽象造成的性能问题。TCP并不知晓其所传输的数据,并将其所传输的所有数据都看作一个byte stream。故而,如果在网络传输过程中,任意位置的packet发生的丢失,所有在复用连接中的其他packets都会停止传输,并等待丢失的packets被重传
- - 这代表,复用的连接中,所有byte streams都会被TCP协议看作是一个byte stream,故而stream A中的packet丢失也会造成stream B的传输被阻塞,直至丢失packet被重传
- - 并且,TCP使用了in-order传输,如果发生packet丢失,那么将阻塞整个的传输过程。在高丢包率的环境下,这将极大程度上影响传输速度。即使在HTTP/2中已经引入了性能优化特性,在2%丢包率的场景下,也会比HTTP/1.1的传输速度更慢
-- native multiplexing:在HTTP/3协议栈中,复用被移动到了传输层,实现了原生复用。QUIC通过stream ID来表示每个byte stream,并不像TCP一样将所有byte streams都看作是一个。
-
-#### How does QUIC remove head-of-line blocking
-QUIC基于UDP实现,其使用了out-of-order delivery,故而每个byte stream都通过网络独立的进行传输。然而,为了可靠性,QUIC确保了在同一byte stream内packets的in-order delivery,故而相同请求中关联的数据到达的顺序是一致的。
-
-QUIC标识了所有byte stream,并且streams是独立进行传输的,如果发生packet丢失,其他byte streams并不会停止并等待重传。
-
-下图中展示了QUIC原生复用和HTTP2应用层复用的区别:
-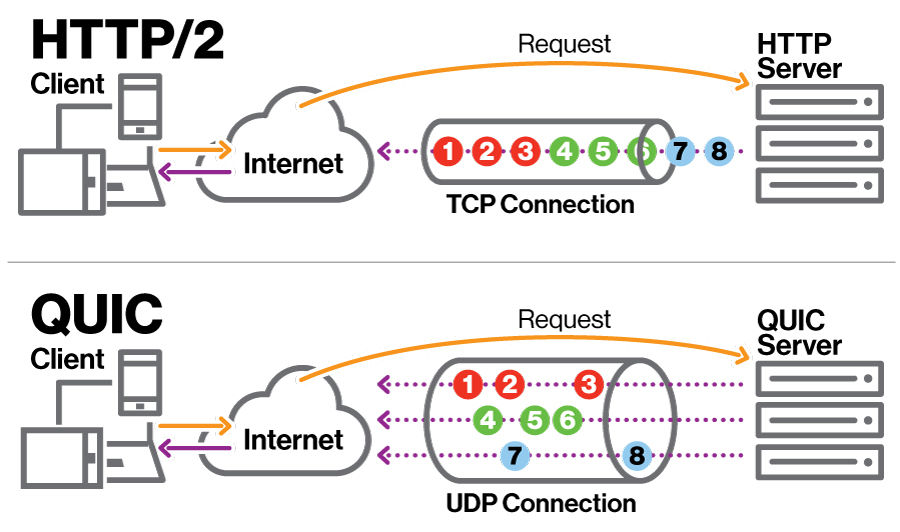 -
-如上图所示,HTTP/2和HTTP/3在传输多个资源时,都只创建了一个连接。但是,QUIC中不同byte streams是独立传输的,拥有不同的传输路径,并且不同byte streams之间不会彼此阻塞。
-
-即使QUIC解决了HTTP/2中引入的HOL问题,乱序传输也会存在弊端:byte streams并不会按照其被发送的顺序到达。例如,在使用乱序传输时,最不重要的资源可能会最先到达。
-
-#### Flexible Bandwidth Management
-带宽管理用于在packets和streams之间按照最优的方式对网络带宽进行分配。这是至关重要的功能,发送方和接收方的机器以及二者之间的网络节点处理packets的速度都有所不同,并且速度也会动态变化。
-
-带宽管理有助于避免网络中的数据溢出和拥塞,这些问题可能会导致server响应速度变慢,同时也可能会带来安全问题。
-
-UDP中并没有内置带宽控制,QUIC则是在HTTP3协议栈中负责该功能,其对TCP带宽管理中的两大部分进行了重新实现:
-- 流控制: 其在接收方限制了数据发送的速率,用于避免发送方造成接收方过载
-- 拥塞控制:其限制了发送方和接收方之间的路径中每一个节点的发送速率,用于避免网络拥塞
-
-##### Pre-Stream Flow Control
-为了支持独立的stream,QUIC采用了per-stream based flow control。其在两个级别控制了stream data的带宽消耗:
-- 对于每个独立的流,都设置了一个可分配给其的最大数据数量
-- 在整个连接范的围内,设置了active streams最大的累积数量
-
-通过per-stream flow control,QUIC限制了同时可以发送的数据数量,用于避免接收方过载,并且在多个streams间大致公平的分配网络容量。
-
-##### 拥塞控制算法
-QUIC允许实现选择不同的拥塞控制算法,使用最广泛的算法如下:
-- NewReno:TCP使用的拥塞控制算法
-- CUBIC: 和NewReno类似,但是使用了cubic function而不是linear function
-- BBR
-
-在网络状况较差的场景下,不同的拥塞控制算法性能可能存在较大差异。
-
+- [HTTP3 \& QUIC Protocols](#http3--quic-protocols)
+ - [What is HTTP3](#what-is-http3)
+ - [TCP/IP模型中HTTP3 vs QUIC](#tcpip模型中http3-vs-quic)
+ - [QUIC Protocol](#quic-protocol)
+ - [What is QUIC Used For](#what-is-quic-used-for)
+ - [HTTP/1.1 vs HTTP/2 vs HTTP/3: Main differences](#http11-vs-http2-vs-http3-main-differences)
+ - [Best Features of HTTP/3 and QUIC](#best-features-of-http3-and-quic)
+ - [QUIC handshake](#quic-handshake)
+ - [0-RTT on Prior Connections](#0-rtt-on-prior-connections)
+ - [Head-of-Line Blocking Removal](#head-of-line-blocking-removal)
+ - [HOL blocking术语](#hol-blocking术语)
+ - [How does QUIC remove head-of-line blocking](#how-does-quic-remove-head-of-line-blocking)
+ - [Flexible Bandwidth Management](#flexible-bandwidth-management)
+ - [Pre-Stream Flow Control](#pre-stream-flow-control)
+ - [拥塞控制算法](#拥塞控制算法)
+
+
+# HTTP3 & QUIC Protocols
+http3旨在通过QUIC(下一代传输层协议)来令网站更快、更安全。
+
+在协议高层,http3提供了和http2相同的功能,例如header compression和stream优先级控制。然而,在协议底层,QUIC传输层协议彻底修改了web传输数据的方式。
+
+## What is HTTP3
+HTTP是一个应用层的网络传输协议,定义了client和server之间的request-reponse机制,允许client/server发送和接收HTML文档和其他文本、meidia files。
+
+http3最初被称为`HTTP-over-QUIC`,其主要目标是令http语法及现存的http/2功能能够和QUIC传输协议兼容。
+
+故而,`HTTP/3`的所有新特性都来源于QUIC层,包括内置加密、新型加密握手、对先前的连接进行zero round-trip恢复,消除头部阻塞问题以及原生多路复用。
+
+## TCP/IP模型中HTTP3 vs QUIC
+通过internet传输信息是复杂的操作,涉及到软件和硬件层面。由于不同的设备、工具、软件都拥有不同的特性,故而单一协议无法描述完整的通信流程。
+
+故而,网络通信是已于通信的协议栈实现的,协议栈中每一层职责都不同。为了使用网络系统来通信,host必须实现构成互联网协议套件的一系列分层协议集。通常,主机至少为每层实现一个协议。
+
+而HTTP则是应用层协议,令web server和web browser之间可以相互通信。http消息(request/reponse)在互联网中则是通过传输层协议来进行传递:
+- 在http/2和http/1.1中,通过TCP协议来进行传递
+- 在`http/3`中,则是通过QUIC协议来进行传递
+
+> `QUIC`为http/3新基于的传输层协议,之前http都基于tcp协议进行传输
+
+## QUIC Protocol
+`QUIC`协议是一个通用的传输层协议,其可以和任意兼容的应用层协议来一起使用,HTTP/3是QUIC的最新用例。
+
+`QUIC`协议基于`UDP`协议构建,其负责server和client之间应用数据的物理传输。UDP协议是一个简单、轻量的协议,其传输速度高但是缺失可靠性、安全性等特性。QUIC实现了这些高层的传输特性,故而可以用于优化http数据通过网络的传输。
+
+在HTTP/3中,HTTP的连接从`TCP-based`迁移到了`UDP-based`,底层的网络通信结构都发生了变化。
+
+### What is QUIC Used For
+QUIC其创建是同于代替`TCP`协议的,QUIC作为传输层协议,相比于TCP更加灵活,性能问题更少。QUIC协议继承了安全传输的特性,并且拥有更快的adoption rate。
+
+QUIC协议底层基于UDP协议的原因是`大多数设备只支持TCP和UDP的端口号`。
+
+除此之外,`QUIC`还利用了UDP的如下特性:
+- UDP的connectionless特性可以使其将多路复用下移到传输层,并且基于UDP的QUIC实现并不会和TCP协议一样存在头部阻塞的问题
+- UDP的间接性能够令QUIC重新实现TCP的可靠性和带宽管理功能
+
+基于QUIC协议的传输和TCP相比是完全不同的方案:
+- 在底层,其是无连接的,其底层基于UDP协议
+- 在高层,其是`connection-oriented`的,其在高层重新实现了TCP协议中连接建立、loss detection等特性,从而确保了数据的可靠传输
+
+综上,QUIC协议结合了UDP和TCP两种协议的优点。
+
+除了上述优点外,QUIC还`在传输层实现了高级别的安全性`。QUIC集成了`TLS 1.3`协议中的大部分特性,令其和自身的传输机制相兼容。在`HTTP/3` stack中,encryption并非是可选的,而是内置特性。
+
+TCP, UDP, QUIC协议的相互比较如下:
+| | TCP | UDP | QUIC |
+| :-: | :-: | :-: | :-: |
+Layer in the TCP/IP model | transport | transport | transport |
+| place in the TCP/IP model | on top of ipv4/ipv6 | on top of ipv4/ipv6 | on top of UDP |
+| connection type | connection-oriented | connectionless | connection-oriented |
+| order of delivery | in-order delivery | out-of-order delivery | out-of-order delivery between streams, in order delivery within stremas |
+| guarantee of delivery | guaranteed | no guarantee of delivery | guaranteed |
+| security | unencrypted | unencrypted | encrypted |
+| data identification | knows nothing about the data it transports | knows nothing about the data it transports | use stream IDs to identify the independent streams it transports |
+
+## HTTP/1.1 vs HTTP/2 vs HTTP/3: Main differences
+H3除了在底层协议栈传输层中引入QUIC和UDP协议外,还存在其他改动,具体如图所示:
+
+
+HTTP/3-QUIC-UDP stack和TCP-based版本的HTTP最重要的区别如下:
+- QUIC集成了TLS 1.3协议中绝大部分特性,encryption从应用层移动到了传输层
+- HTTP/3在不同的streams间并不会对连接进行多路复用,多路复用的特性是由QUIC在传输层执行的
+ - 传输层的多路复用移解决了HTTP/2中TCP中头部阻塞的问题(HTTP/1.1中并不存在头部阻塞问题,因为其会开启多个TCP连接,并且会提供pipelining选项,后来该方案被发现拥有严重实现缺陷,被替换为了HTTP/2中应用层的多路复用)
+
+## Best Features of HTTP/3 and QUIC
+HTTP/3和QUIC的新特性能够令server connections速度更快、传输更安全、可靠性更高。
+
+### QUIC handshake
+在HTTP2中,client和server在执行handshake的过程中,至少需要2次round-trips:
+- tcp handshake需要一次round-trip
+- tls handleshake至少需要一次round-trip
+
+和QUIC则将上述两次handshakes整合成了一个,HTTP3仅需一次round-trip就可以在client和server之间建立一个secure connection。`QUIC可以带来更快的连接建立和更低的延迟。`
+
+QUIC集成了`TLS1.3`中的绝大多数特性,`TLS1.3`是目前最新版本的`Transport Layer Security`协议,其代表:
+- HTTP/3中,消息的加密是强制的,并不像HTTP/1.1和HTTP/2中一样是可选的。在使用HTTP/3时,所有的消息都默认通过encrypted connection来进行发送。
+- TLS 1.3引入了一个`improved cryptographic handshake`,在client和server间仅需要一次round-trip;而TLS 1.2中则需要两次round-trips用于认证
+ - 而在QUIC中,则将该`improved cryptographic handshake`和其本身用于连接创建的handshake进行了整合,并替代了TCP的handshake
+- 在HTTP/3中,消息都是在传输层加密的,故而加密的信息比HTTP/1.1和HTTP/2中都更多
+ - 在HTTP/1.1和HTTP/2协议栈中,TLS都运行在应用层,故而HTTP data是加密的,但是,TCP header则是明文发送的,TCP header的明文可能会带来一些安全问题
+ - 在HTTP/3 stack中,TLS运行在传输层,故而不仅http message被加密,大多数QUIC packet header也是被加密的
+
+简单来说,HTTP/3使用的传输机制相比于TCP-based HTTP版本来说要更加安全。(传输层协议本身的header也被加密)
+
+### 0-RTT on Prior Connections
+对于先前存在的connections,QUIC利用了TLS 1.3的`0-RTT`特性。
+
+`0-RTT`代表zero round-trip time resumption,是TLS 1.3中引入的一个新特性。
+
+TLS session resumption通过复用先前建立的安全参数,减少建立secure connection所花费的时间。当client和server频繁建立连接并断开时,这将带来性能改善。
+
+通过0-RTT resumption,client可以在连接的第一个round-trip中发送http请求,复用先前建立的cryptographic keys。
+
+下面展示了H2和H3 stack在建立连接时的区别:
+
+
+
+- 当使用HTTP2和TLS 1.2时,client发送第一个http request需要4个round-trip
+- 在使用HTTP2和TLS 1.3时,client发送第一个http equest需要2、3个round-trip(根据是否使用0-rtt有所不同)
+- 在使用HTTP3和QUIC时,其默认包含TLS 1.3,其可以在1、2个round-trip内发送第一个http请求(根据是否复用先前连接的加密信息)
+
+### Head-of-Line Blocking Removal
+HTTP/3协议栈和HTTP/2协议栈的结构不同,其解决了HTTP/2中最大的性能问题:`head-of-line`阻塞。
+- 该问题主要发生在HTTP/2中packet丢失的场景下,直到丢失的包被重传前,整个的数据传输过程都会停止,所有packets都必须在网络上等待,这将会导致页面的加载时间延长
+
+在HTTP/3中,行首阻塞通过原生的多路复用解决了。这是QUIC最重要的特性之一。
+
+#### HOL blocking术语
+如下是HOL问题涉及到的概念:
+- byte stream:是通过网络发送的字节序列。bytes作为不同大小的packets被传输。byte stream本质上是单个资源(file)的物理表现形式,通过网络来发送
+- 复用:通过复用,可以在一个connection上传输多个byte streams,这将代表浏览器可以在同一个连接上同时加载多个文件
+ - 在HTTP/1.1中,并不支持复用,其会未每个byte stream新开一个tcp连接。HTTP/2中引入了应用层的复用,其只会建立一个TCP连接,并通过其传输所有byte streams。故而,仅有HTTP/2会存在HOL问题
+- HOL blocking:这是由tcp byte stream抽象造成的性能问题。TCP并不知晓其所传输的数据,并将其所传输的所有数据都看作一个byte stream。故而,如果在网络传输过程中,任意位置的packet发生的丢失,所有在复用连接中的其他packets都会停止传输,并等待丢失的packets被重传
+ - 这代表,复用的连接中,所有byte streams都会被TCP协议看作是一个byte stream,故而stream A中的packet丢失也会造成stream B的传输被阻塞,直至丢失packet被重传
+ - 并且,TCP使用了in-order传输,如果发生packet丢失,那么将阻塞整个的传输过程。在高丢包率的环境下,这将极大程度上影响传输速度。即使在HTTP/2中已经引入了性能优化特性,在2%丢包率的场景下,也会比HTTP/1.1的传输速度更慢
+- native multiplexing:在HTTP/3协议栈中,复用被移动到了传输层,实现了原生复用。QUIC通过stream ID来表示每个byte stream,并不像TCP一样将所有byte streams都看作是一个。
+
+#### How does QUIC remove head-of-line blocking
+QUIC基于UDP实现,其使用了out-of-order delivery,故而每个byte stream都通过网络独立的进行传输。然而,为了可靠性,QUIC确保了在同一byte stream内packets的in-order delivery,故而相同请求中关联的数据到达的顺序是一致的。
+
+QUIC标识了所有byte stream,并且streams是独立进行传输的,如果发生packet丢失,其他byte streams并不会停止并等待重传。
+
+下图中展示了QUIC原生复用和HTTP2应用层复用的区别:
+
+
+如上图所示,HTTP/2和HTTP/3在传输多个资源时,都只创建了一个连接。但是,QUIC中不同byte streams是独立传输的,拥有不同的传输路径,并且不同byte streams之间不会彼此阻塞。
+
+即使QUIC解决了HTTP/2中引入的HOL问题,乱序传输也会存在弊端:byte streams并不会按照其被发送的顺序到达。例如,在使用乱序传输时,最不重要的资源可能会最先到达。
+
+#### Flexible Bandwidth Management
+带宽管理用于在packets和streams之间按照最优的方式对网络带宽进行分配。这是至关重要的功能,发送方和接收方的机器以及二者之间的网络节点处理packets的速度都有所不同,并且速度也会动态变化。
+
+带宽管理有助于避免网络中的数据溢出和拥塞,这些问题可能会导致server响应速度变慢,同时也可能会带来安全问题。
+
+UDP中并没有内置带宽控制,QUIC则是在HTTP3协议栈中负责该功能,其对TCP带宽管理中的两大部分进行了重新实现:
+- 流控制: 其在接收方限制了数据发送的速率,用于避免发送方造成接收方过载
+- 拥塞控制:其限制了发送方和接收方之间的路径中每一个节点的发送速率,用于避免网络拥塞
+
+##### Pre-Stream Flow Control
+为了支持独立的stream,QUIC采用了per-stream based flow control。其在两个级别控制了stream data的带宽消耗:
+- 对于每个独立的流,都设置了一个可分配给其的最大数据数量
+- 在整个连接范的围内,设置了active streams最大的累积数量
+
+通过per-stream flow control,QUIC限制了同时可以发送的数据数量,用于避免接收方过载,并且在多个streams间大致公平的分配网络容量。
+
+##### 拥塞控制算法
+QUIC允许实现选择不同的拥塞控制算法,使用最广泛的算法如下:
+- NewReno:TCP使用的拥塞控制算法
+- CUBIC: 和NewReno类似,但是使用了cubic function而不是linear function
+- BBR
+
+在网络状况较差的场景下,不同的拥塞控制算法性能可能存在较大差异。
+
diff --git a/java se/垃圾回收和引用.md b/java se/垃圾回收和引用.md
index 70c62c9..dd9b2a9 100644
--- a/java se/垃圾回收和引用.md
+++ b/java se/垃圾回收和引用.md
@@ -1,109 +1,109 @@
-- [垃圾回收和引用](#垃圾回收和引用)
- - [finalize](#finalize)
- - [引用](#引用)
- - [Reference](#reference)
- - [get](#get)
- - [clear](#clear)
- - [enqueue](#enqueue)
- - [isEnqueue](#isenqueue)
- - [引用的可达性](#引用的可达性)
- - [强可达(strongly reachable)](#强可达strongly-reachable)
- - [软可达(softly reachable)](#软可达softly-reachable)
- - [弱可达(weakly reachable)](#弱可达weakly-reachable)
- - [终结器可达(finalizer reachable)](#终结器可达finalizer-reachable)
- - [幽灵可达(phantom reachable)](#幽灵可达phantom-reachable)
- - [引用类型](#引用类型)
- - [软引用(SoftReference)](#软引用softreference)
- - [弱引用(WeakReference)](#弱引用weakreference)
- - [幽灵可达](#幽灵可达)
- - [Weak Hash Map](#weak-hash-map)
- - [引用队列](#引用队列)
- - [ReferenceQueue.poll](#referencequeuepoll)
- - [ReferenceQueue.remove](#referencequeueremove)
- - [弱引用和软引用的使用](#弱引用和软引用的使用)
-
-# 垃圾回收和引用
-## finalize
-finalize方法将会在对象的空间被回收之前被调用。如果一个对象被垃圾回收器判为不可达而需要被回收时,垃圾回收器将调用该对象的finalize方法,通过finalize方法可以清除对象的一些非内存资源。
-在每个对象中,finalize方法最多被调用一次。
-> finalize方法可以抛出任何异常,但是抛出的异常将被垃圾回收器忽略。
-
-在finalize方法调用时,该对象引用的其他对象可能也是垃圾对象,并且已经被回收。
-## 引用
-### Reference
-Reference是一个抽象类,是所有特定引用类的父类。
-#### get
-```java
-public Object get()
-```
-将会返回引用对象指向的被引用对象
-#### clear
-```java
-public void clear()
-```
-清空引用对象从而使其不指向任何对象
-#### enqueue
-```java
-public boolean enqueue()
-```
-如果存在引用对象,将引用对象加入到注册的引用队列中,如果加入队列成功,返回true;如果没有成功加入到队列,或者该引用对象已经在队列中,那么返回false
-#### isEnqueue
-```java
-public boolean isEnqueue()
-```
-如果该引用对象已经被加入到引用队列中,那么返回true,否则返回false
-### 引用的可达性
-#### 强可达(strongly reachable)
-至少通过一条强引用链可达
-#### 软可达(softly reachable)
-不是强可达,但是至少可以通过一条包含软引用的引用链可达
-#### 弱可达(weakly reachable)
-不是弱可达,但是至少通过一条包含弱引用的引用链可达
-#### 终结器可达(finalizer reachable)
-不是弱可达,但是该对象的finalize方法尚未执行
-#### 幽灵可达(phantom reachable)
-如果finalize方法已经执行,但是可通过至少一条包含幽灵引用的引用链可达
-### 引用类型
-#### 软引用(SoftReference)
-对于软可达的对象,垃圾回收程序会随意进行处置,如果可用内存很低,回收器会清空SoftReference对象中的引用,之后该被引用对象则能被回收
-> 在抛出OOM之前,所有的SoftReference引用将会被清空
-
-#### 弱引用(WeakReference)
-弱可达对象将会被垃圾回收器回收,如果垃圾回收器认为对象是弱可达的,所有指向其的WeakReference对象都会被清空
-
-#### 幽灵可达
-幽灵可达并不是真正的可达,虚引用并不会影响对象的生命周期,如果一个对象和虚引用关联,则该对象跟没有与该虚引用关联一样,在任何时候都有可能被垃圾回收。虚引用主要用于跟踪对象垃圾回收的活动。
-
-### Weak Hash Map
-WeakHashMap会使用WeakReference来存储key。
-如果垃圾回收器发现一个对象弱可达时,会将弱引用放入到引用队列中。WeakHashMap会定期检查引用队列中新到达的弱引用,并且新到的弱引用代表该key不再被使用,WeakHashMap会移除关联的entry。
-
-
-### 引用队列
-如果对象的可达性状态发生了改变,那么执行该对象的引用类型将会被放置到引用队列中。引用队列通常被垃圾回收器使用。
-也可以在自己的代码中对引用队列进行使用,通过引用队列,可以监听对象的可达性改变。
-> 例如当对象不再被强引用,变为弱可达时,引用将会被添加到引用队列中,再通过代码监听引用队列的变化,即可监听到对象可达性的变化
-
-> ReferenceQueue是线程安全的。
-
-#### ReferenceQueue.poll
-```java
-pulbic Reference poll()
-```
-该方法会删除并且返回队列中的下一个引用对象,若队列为空,则返回值为null
-
-#### ReferenceQueue.remove
-```java
-public Reference remove() throws InterruptedException
-```
-该方法同样会删除并返回队列中下一个引用对象,但是该方法在队列为空时会无限阻塞下去
-```java
-public Reference remove(long timeout) throws InterruptedException
-```
-
-引用对象在构造时,会和特定的引用队列相关联,当被引用对象的可达性状态发生变化时,被添加到引用队列中。在被添加到队列之前,引用对象都已经被清空。
-
-### 弱引用和软引用的使用
-弱引用和软引用都提供两种类型的构造函数,
-- 只接受被引用对象,并不将引用注册到引用队列
+- [垃圾回收和引用](#垃圾回收和引用)
+ - [finalize](#finalize)
+ - [引用](#引用)
+ - [Reference](#reference)
+ - [get](#get)
+ - [clear](#clear)
+ - [enqueue](#enqueue)
+ - [isEnqueue](#isenqueue)
+ - [引用的可达性](#引用的可达性)
+ - [强可达(strongly reachable)](#强可达strongly-reachable)
+ - [软可达(softly reachable)](#软可达softly-reachable)
+ - [弱可达(weakly reachable)](#弱可达weakly-reachable)
+ - [终结器可达(finalizer reachable)](#终结器可达finalizer-reachable)
+ - [幽灵可达(phantom reachable)](#幽灵可达phantom-reachable)
+ - [引用类型](#引用类型)
+ - [软引用(SoftReference)](#软引用softreference)
+ - [弱引用(WeakReference)](#弱引用weakreference)
+ - [幽灵可达](#幽灵可达)
+ - [Weak Hash Map](#weak-hash-map)
+ - [引用队列](#引用队列)
+ - [ReferenceQueue.poll](#referencequeuepoll)
+ - [ReferenceQueue.remove](#referencequeueremove)
+ - [弱引用和软引用的使用](#弱引用和软引用的使用)
+
+# 垃圾回收和引用
+## finalize
+finalize方法将会在对象的空间被回收之前被调用。如果一个对象被垃圾回收器判为不可达而需要被回收时,垃圾回收器将调用该对象的finalize方法,通过finalize方法可以清除对象的一些非内存资源。
+在每个对象中,finalize方法最多被调用一次。
+> finalize方法可以抛出任何异常,但是抛出的异常将被垃圾回收器忽略。
+
+在finalize方法调用时,该对象引用的其他对象可能也是垃圾对象,并且已经被回收。
+## 引用
+### Reference
+Reference是一个抽象类,是所有特定引用类的父类。
+#### get
+```java
+public Object get()
+```
+将会返回引用对象指向的被引用对象
+#### clear
+```java
+public void clear()
+```
+清空引用对象从而使其不指向任何对象
+#### enqueue
+```java
+public boolean enqueue()
+```
+如果存在引用对象,将引用对象加入到注册的引用队列中,如果加入队列成功,返回true;如果没有成功加入到队列,或者该引用对象已经在队列中,那么返回false
+#### isEnqueue
+```java
+public boolean isEnqueue()
+```
+如果该引用对象已经被加入到引用队列中,那么返回true,否则返回false
+### 引用的可达性
+#### 强可达(strongly reachable)
+至少通过一条强引用链可达
+#### 软可达(softly reachable)
+不是强可达,但是至少可以通过一条包含软引用的引用链可达
+#### 弱可达(weakly reachable)
+不是弱可达,但是至少通过一条包含弱引用的引用链可达
+#### 终结器可达(finalizer reachable)
+不是弱可达,但是该对象的finalize方法尚未执行
+#### 幽灵可达(phantom reachable)
+如果finalize方法已经执行,但是可通过至少一条包含幽灵引用的引用链可达
+### 引用类型
+#### 软引用(SoftReference)
+对于软可达的对象,垃圾回收程序会随意进行处置,如果可用内存很低,回收器会清空SoftReference对象中的引用,之后该被引用对象则能被回收
+> 在抛出OOM之前,所有的SoftReference引用将会被清空
+
+#### 弱引用(WeakReference)
+弱可达对象将会被垃圾回收器回收,如果垃圾回收器认为对象是弱可达的,所有指向其的WeakReference对象都会被清空
+
+#### 幽灵可达
+幽灵可达并不是真正的可达,虚引用并不会影响对象的生命周期,如果一个对象和虚引用关联,则该对象跟没有与该虚引用关联一样,在任何时候都有可能被垃圾回收。虚引用主要用于跟踪对象垃圾回收的活动。
+
+### Weak Hash Map
+WeakHashMap会使用WeakReference来存储key。
+如果垃圾回收器发现一个对象弱可达时,会将弱引用放入到引用队列中。WeakHashMap会定期检查引用队列中新到达的弱引用,并且新到的弱引用代表该key不再被使用,WeakHashMap会移除关联的entry。
+
+
+### 引用队列
+如果对象的可达性状态发生了改变,那么执行该对象的引用类型将会被放置到引用队列中。引用队列通常被垃圾回收器使用。
+也可以在自己的代码中对引用队列进行使用,通过引用队列,可以监听对象的可达性改变。
+> 例如当对象不再被强引用,变为弱可达时,引用将会被添加到引用队列中,再通过代码监听引用队列的变化,即可监听到对象可达性的变化
+
+> ReferenceQueue是线程安全的。
+
+#### ReferenceQueue.poll
+```java
+pulbic Reference poll()
+```
+该方法会删除并且返回队列中的下一个引用对象,若队列为空,则返回值为null
+
+#### ReferenceQueue.remove
+```java
+public Reference remove() throws InterruptedException
+```
+该方法同样会删除并返回队列中下一个引用对象,但是该方法在队列为空时会无限阻塞下去
+```java
+public Reference remove(long timeout) throws InterruptedException
+```
+
+引用对象在构造时,会和特定的引用队列相关联,当被引用对象的可达性状态发生变化时,被添加到引用队列中。在被添加到队列之前,引用对象都已经被清空。
+
+### 弱引用和软引用的使用
+弱引用和软引用都提供两种类型的构造函数,
+- 只接受被引用对象,并不将引用注册到引用队列
- 既接受被引用对象,还将引用注册到指定的引用队列,然后可以通过检查引用队列中的情况来监听被引用对象可达状态变更
\ No newline at end of file
diff --git a/mysql/mysql文档/mysql_文件.md b/mysql/mysql文档/mysql_文件.md
index 043490e..d7b5d3d 100644
--- a/mysql/mysql文档/mysql_文件.md
+++ b/mysql/mysql文档/mysql_文件.md
@@ -1,363 +1,363 @@
-- [文件](#文件)
- - [参数](#参数)
- - [参数查看](#参数查看)
- - [参数类型](#参数类型)
- - [动态参数修改](#动态参数修改)
- - [静态参数修改](#静态参数修改)
- - [日志文件](#日志文件)
- - [错误日志](#错误日志)
- - [慢查询日志](#慢查询日志)
- - [log\_queries\_not\_using\_indexes](#log_queries_not_using_indexes)
- - [查询日志](#查询日志)
- - [二进制日志](#二进制日志)
- - [max\_binlog\_size](#max_binlog_size)
- - [binlog\_cache\_size](#binlog_cache_size)
- - [binlog\_cache\_use](#binlog_cache_use)
- - [binlog\_cache\_disk\_use](#binlog_cache_disk_use)
- - [sync\_binlog](#sync_binlog)
- - [innodb\_flush\_log\_at\_trx\_commit](#innodb_flush_log_at_trx_commit)
- - [binlog\_format](#binlog_format)
- - [使用statement可能会存在的问题](#使用statement可能会存在的问题)
- - [mysqlbinlog](#mysqlbinlog)
- - [pid文件](#pid文件)
- - [表结构定义文件](#表结构定义文件)
- - [表空间文件](#表空间文件)
- - [innodb\_data\_file\_path](#innodb_data_file_path)
- - [innodb\_file\_per\_table](#innodb_file_per_table)
- - [redo log文件](#redo-log文件)
- - [循环写入](#循环写入)
- - [redo log capacity](#redo-log-capacity)
- - [redo log和binlog的区别](#redo-log和binlog的区别)
- - [记录内容](#记录内容)
- - [写入时机](#写入时机)
- - [redo log写入时机](#redo-log写入时机)
-
-
-# 文件
-## 参数
-### 参数查看
-mysql参数为键值对,可以通过`show variables`命令查看所有的数据库参数,并可以通过`like`来过滤参数名称。
-
-除了`show variables`命令之外,还能够在`performance_schema`下的`global_variables`视图来查找数据库参数,示例如下:
-```sql
--- 查看innodb_buffer_pool_size参数
-show variables like 'innodb_buffer_pool_size'
-```
-上述`show variables`命令的执行结果为
-| Variable\_name | Value |
-| :--- | :--- |
-| innodb\_buffer\_pool\_size | 4294967296 |
-
-```sql
-select * from performance_schema.global_variables where variable_name like 'innodb_buffer_pool%';
-```
-上述sql的执行结果如下:
-| VARIABLE\_NAME | VARIABLE\_VALUE |
-| :--- | :--- |
-| innodb\_buffer\_pool\_chunk\_size | 134217728 |
-| innodb\_buffer\_pool\_dump\_at\_shutdown | ON |
-| innodb\_buffer\_pool\_dump\_now | OFF |
-| innodb\_buffer\_pool\_dump\_pct | 25 |
-| innodb\_buffer\_pool\_filename | ib\_buffer\_pool |
-| innodb\_buffer\_pool\_in\_core\_file | ON |
-| innodb\_buffer\_pool\_instances | 4 |
-| innodb\_buffer\_pool\_load\_abort | OFF |
-| innodb\_buffer\_pool\_load\_at\_startup | ON |
-| innodb\_buffer\_pool\_load\_now | OFF |
-| innodb\_buffer\_pool\_size | 4294967296 |
-
-### 参数类型
-mysql中的参数可以分为`动态`和`静态`两种类型,
-- 动态:动态参数代表可以在mysql运行过程中进行修改
-- 静态:代表在整个实例的声明周期内都不得进行修改
-
-#### 动态参数修改
-对于动态参数,可以在运行时通过`SET`命令来进行修改,`SET`命令语法如下:
-```sql
-set
- | [global | session] system_var_name=expr
- | [@@global. | @@session. | @@] system_var_name = expr
-```
-在上述语法中,`global`和`session`关键字代表该动态参数的修改是针对`当前会话`还是针对`整个实例的生命周期`。
-
-- 有些动态参数只能在会话范围内进行修改,例如`autocommit`
-- 有些参数修改后,实例整个生命周期内都会生效,例如`binglog_cache_size`
-- 有些参数既可以在会话范围内进行修改,又可以在实例声明周期范围内进行修改,例如`read_buffer_size`
-
-使用示例如下:
-
-查询read_buffer_size的global和session值
-```sql
--- 查询read_buffer_size的global和session值
-select @@session.read_buffer_size,@@global.read_buffer_size;
-```
-返回结果为
-
-| @@session.read\_buffer\_size | @@global.read\_buffer\_size |
-| :--- | :--- |
-| 131072 | 131072 |
-
-设置@@session.read_buffer_size为524288
-```sql
-set @@session.read_buffer_size = 1024 * 512;
-```
-设置后,再次查询read_buffer_size的global和session值,结果为
-| @@session.read\_buffer\_size | @@global.read\_buffer\_size |
-| :--- | :--- |
-| 524288 | 131072 |
-
-在调用set命令修改session read_buffer_size参数后,session参数发生变化,但是global参数仍然为旧的值。
-
-> `set session xxx`命令并不会对global参数的值造成影响,新会话的参数值仍然为修改前的值。
-
-之后,再对global read_buffer_size值进行修改,执行如下命令
-```sql
-set @@global.read_buffer_size = 496 * 1024;
-```
-执行该命令后,sesion和global参数值为
-| @@session.read\_buffer\_size | @@global.read\_buffer\_size |
-| :--- | :--- |
-| 524288 | 507904 |
-
-> `set global xxx`命令只会修改global参数值,对session参数值不会造成影响,新的session其`session参数值, global参数值`和修改后的global参数值保持一致
-
-> 即使针对参数的global值进行了修改,其影响范围是当前实例的整个生命周期,`但是,其并不会对参数文件中的参数值进行修改,故而下次启动mysql实例时,仍然会从参数文件中取值,新实例的值仍然是修改前的值`。
->
-> 如果想要修改下次启动实例的参数值,需要修改参数文件中该参数的值。(参数文件路径通常为`/etc/my.cnf`)
-
-#### 静态参数修改
-在运行时,如果尝试对静态参数进行修改,那么会发生错误,示例如下:
-```sql
-> set global datadir='/db/mysql'
-[2025-01-30 15:05:17] [HY000][1238] Variable 'datadir' is a read only variable
-```
-## 日志文件
-mysql中常见日志文件如下
-- 错误日志(error log)
-- 二进制日志(binlog)
-- 慢查询日志(slow query log)
-- 查询日志(log)
-
-### 错误日志
-错误日志针对mysql的启动、运行、关闭过程进行了记录,用户可以通过`show variables like 'log_error';`来获取错误日志的路径:
-```sql
-show variables like 'log_error';
-```
-其输出值如下:
-| Variable\_name | Value |
-| :--- | :--- |
-| log\_error | /var/log/mysql/mysqld.log |
-
-当mysql数据库无法正常启动时,应当首先查看错误日志。
-
-### 慢查询日志
-慢查询日志存在一个阈值,通过`long_query_time`参数来进行控制,该参数默认值为`10`,代表慢查询的限制为10s。
-
-通过`slow_query_log`参数,可以控制是否日志输出慢查询日志,默认为`OFF`,如果需要开启慢查询日志,需要将该值设置为`ON`。
-
-关于慢查询日志的输出地点,可以通过`log_output`参数来进行控制。该参数默认为`FILE`,支持`FILE, TABLE, NONE`。`log_output`支持制定多个值,多个值之间可以通过`,`分隔,当值中包含`NONE`时,以`NONE`优先。
-
-#### log_queries_not_using_indexes
-当`log_queryies_not_using_indexes`开启时,如果运行的sql语句没有使用索引,那么这条sql同样会被输出到慢查询日志。该参数默认关闭。
-
-`log_throttle_queries_not_using_idnexes`用于记录`每分钟允许记录到慢查询日志并且没有使用索引`的sql语句次数,该参数值默认为0,代表每分钟输出到慢查询日志中的数量没有限制。
-
-该参数主要用于防止大量没有使用索引的sql添加到慢查询日志中,造成慢查询日志大小快速增加。
-
-当慢查询日志中的内容越来越多时,可以通过mysql提供的工具`mysqldumpslow`命令,示例如下:
-```sql
-mysqldumpslow -s at -n 10 ${slow_query_log_path}
-```
-
-### 查询日志
-查询日志记录了对mysql数据库所有的请求信息,无论请求是否正确执行。
-
-查询日志通过`general_log`参数来进行控制,默认该参数值为`OFF`.
-
-### 二进制日志
-二进制日志(binary log)记录了针对mysql数据库执行的所有更改操作(不包含select以及show这类读操作)。
-
-对于update操作等,即使没有对数据库进行修改(affected rows为0),也会被写入到binary log中。
-
-二进制日志的主要用途如下:
-- 恢复(recovery):某些数据恢复需要二进制日志,例如在数据库全备份文件恢复后,用户可以通过二进制日志进行point-in-time的恢复
-- 复制(replication):通过将一台主机(master)的binlog同步到另一台主机(slave),并且在另一台主机上执行该binlog,可以令slave与master进行实时同步
-- 审计(audit):用户可以对binlog中的信息进行审计,判断是否存在对数据库进行的注入攻击
-
-通过参数`log_bin`可以控制是否启用二进制日志。
-
-binlog通常存放在`datadir`参数所指定的目录路径下。在该路径下,还存在`binlog.index`文件,该文件为binlog的索引文件,文件内容包含所有binlog的文件名称。
-
-#### max_binlog_size
-`max_binlog_size`参数控制单个binlog文件的最大大小,如果单个文件超过该值,会产生新的二进制文件,新binlog的后缀会+1,并且新文件的文件名会被记录到`.index`文件中。
-
-`max_binlog_size`的默认值大小为`1G`。
-
-#### binlog_cache_size
-当使用innodb存储引擎时,所有未提交事务的binlog会被记录到缓存中,等到事务提交后,会将缓存中的binlog写入到文件中。缓存大小通过`binlog_cache_size`决定,该值默认为`32768`,即`32KB`。
-
-`binlog_cache_size`是基于会话的,`在每个线程开启一个事务时,mysql会自动分配一个大小为binlog_cache_size大小的缓存,因而该值不能设置过大`。
-
-当一个事务的记录大于设定的`binlog_cache_size`时,mysql会将缓冲中的日志写入到一个临时文件中,故而,该值无法设置过小。
-
-通过`show global status like 'binlog_cache%`命令可以查看`binlog_cache_use`和`binlog_cache_disk_use`的状态,可以通过上述两个状态判断binlog cache大小是否合适。
-
-##### binlog_cache_use
-`binlog_cache_use`记录了使用缓冲写binlog的次数
-
-##### binlog_cache_disk_use
-`binlog_cache_disk_use`记录了使用临时文件写二进制日志的次数
-
-#### sync_binlog
-`sync_binlog`参数控制mysql server同步binlog到磁盘的频率,该值默认为`1`
-
-- 0: 如果参数值为0,代表mysql server禁用binary log同步到磁盘。mysql会依赖操作系统将binary log刷新到磁盘中,该设置性能最佳,但是遇到操作系统崩溃时,可能会出现mysql事务提交但是还没有同步到binary log的场景
-- 1: 如果参数值设置为1,代表在事务提交之前将binary log同步到磁盘中,该设置最安全,但是会增加disk write次数,对性能会带来负面影响。在操作系统崩溃的场景下,binlog中缺失的事务还只处于prepared状态,从而确保binlog中没有事务丢失
-- N:当参数值被设置为非`0,1`的值时,每当n个binlog commit groups被收集到后,同步binlog到磁盘。在这种情况下,可能会发生事务提交但是还没有被刷新到binlog中,`当n值越大时,性能会越好,但是也会增加数据丢失的风险`
-
-为了在使用innodb事务和replciation时获得最好的一致性和持久性,请使用如下设置:
-```cnf
-sync_binlog=1
-innodb_flush_log_at_trx_commit=1
-```
-
-#### innodb_flush_log_at_trx_commit
-innodb_flush_log_at_trx_commit用于控制redo log的刷新。
-
-该参数用于平衡`commit操作ACID的合规性`以及`更高性能`。通过修改该参数值,可以实现更佳的性能,但是在崩溃时可能会丢失事务:
-- 1: 1为该参数默认值,代表完全的ACID合规性,日志在每次事务提交后被写入并刷新到磁盘中
-- 0: 日志每秒被写入和刷新到磁盘中,如果事务没有被刷新,那么日志将会在崩溃中被丢失
-- 2: 每当事务提交后,日志将会被写入,并且每秒钟都会被刷新到磁盘中。如果事务没有被刷新,崩溃同样会造成日志的丢失
-
-如果当前数据库为slave角色,那么其不会把`从master同步的binlog`写入到自己的binlog中,如果要实现`master=>slave=>slave`的同步架构,必须设置`log_slave_updates`参数。
-
-#### binlog_format
-binlog_format用于控制二进制文件的格式,可能有如下取值:
-- statement: 二进制文件记录的是日志的逻辑sql语句
-- row:记录表的行更改情况,默认值为`row`
-- mixed: 如果参数被配置为mixed,mysql默认会采用`statement`格式进行记录,但是在特定场景能够下会使用`row`格式:
- - 使用了uuid, user, current_user,found_rows, row_count等不确定函数
- - 使用了insert delay语句
- - 使用了用户自定义函数
- - 使用了临时表
-
-##### 使用statement可能会存在的问题
-在使用statement格式时,可能会存在如下问题
-- master运行rand,uuid等不确定函数时,或使用触发器操作时,会导致主从服务器上的数据不一致
-- innodb的默认事务隔离级别为`repetable_read`,如果使用`read_commited`级别时,statement格式可能会导致丢失更新的情况,从而令master和slave的数据不一致
-
-binlog为动态参数,可以在数据库运行时进行修改,并且可以针对session和global进行修改。
-
-#### mysqlbinlog
-在查看二进制日志时,可以使用`mysqlbinlog`命令,示例如下
-```bash
-mysqlbinlog --start-position=203 ${binlog_path}
-```
-
-## pid文件
-mysql实例启动时,会将进程id写入到一个文件中,该文件被称为pid文件。
-
-pid文件路径通过`pid_file`参数来进行控制,fedora中默认路径为`/run/mysqld/mysqld.pid`。
-
-## 表结构定义文件
-mysql中数据的存储是根据表进行的,每个表都有与之对应的文件。无论表采用何种存储引擎,都会存在一个以`frm`为后缀的文件,该文件中保存了该表的表结构定义。
-
-> mysql 8中,schema对应目录下不再包含frm文件。
-
-## 表空间文件
-innodb采用将存储的数据按照表空间(tablespace)进行存放的设计。在默认配置下,将会有一个初始大小为10MB,名称为ibdata1的文件,该文件为默认的表空间文件。
-
-### innodb_data_file_path
-可以通过`innodb_data_file_path`参数对默认表空间文件进行设置,示例如下:
-```sql
-innodb_data_file_path=datafile_spec1[;datafile_spec2]...
-```
-用户可以通过多个文件组成一个表空间,示例如下:
-```sql
-innodb_data_file_path=/db/ibdata1:2000M;/dr2/db/ibdata2:2000M;autoextend
-```
-在上述配置中,表空间由`/db/ibdata1`和`/dr2/db/ibdata2`两个文件组成,如果两个文件位于不同的磁盘上,那么磁盘的负载将会被平均,数据库的整体性能将会被提高。
-
-同时,在上述示例中,为两个文件都指定了后续属性,含义如下:
-- ibdata1:文件大小为2000M
-- ibdata2:文件大小为2000M,并且当文件大小被用完后,文件会自动增长
-
-当`innodb_data_file_path`被设置后,所有基于innodb存储引擎的表,其数据都会记录到该共享表空间中。
-
-### innodb_file_per_table
-如果`innodb_file_per_table`被启用后(默认启用),则每个基于innodb存储引擎的表都可以有一个独立的表空间,独立表空间的命名规则为`表名+.ibd`。
-
-通过innodb_file_per_table,用户不需要将所有的数据都放置在默认的表空间中。
-
-> `innodb_file_per_table`所产生的独立表空间文件,其仅存储该表的数据、索引和插入缓冲BITMAP信息,其余信息仍然存放在默认的表空间中。
-
-## redo log文件
-redo log是一个基于磁盘的数据结构,用于在crash recovery过程中纠正由`未完成事务写入的错误数据`。
-
-> 在一般操作中,redo log对那些`会造成表数据发生改变的请求`进行encode操作,请求通常由sql statement或地级别api发起。
-
-redo log通常代表磁盘上的redo log file。写入重做日志文件的数据通常基于受影响的记录进行编码。在数据被写入到redo log file中时,LSN值也会不断增加。
-
-### 循环写入
-innodb会按顺序写入redo log文件,例如redo log file group中存在两个文件,innodb会先写文件1,文件1写满后会切换文件2,在文件2写满后,重新切换到文件1。
-
-### redo log capacity
-从mysql 8.0.30开始,`innodb_redo_log_capacity`参数用于控制redo log file占用磁盘空间的大小。该参数可以在实例启动时进行设置,也可以通过`set global`来进行设置。
-
-`innodb_redo_log_capacity`默认值为`104857600`,即`100M`。
-
-redo log文件默认位于`datadir`路径下的`#innodb_redo`目录下。innodb会尝试维护32个redo log file,每个redo log file文件大小都相同,为`1/32 * innodb_redo_log_capacity`。
-
-redo log file将会使用`#ib_redoN`的命名方式,`N`是redo log file number。
-
-innodb redo log file分为如下两种:
-- ordinary:正在被使用的redo log file
-- spare:等待被使用的redo log file
-
-> 相比于ordinary redo log file,spare redo log file的名称中还包含了`_tmp`后缀
-
-每个oridnary redo log file都关联了一个制定的LSN范围,可以通过查询`performance_schema.innodb_redo_log_files`表里获取LSN范围。
-
-示例如下:
-```sql
-select file_name, start_lsn, end_lsn from performance_schema.innodb_redo_log_files;
-```
-查询结果示例如下:
-| file\_name | start\_lsn | end\_lsn |
-| :--- | :--- | :--- |
-| ./#innodb\_redo/#ib\_redo6 | 19656704 | 22931456 |
-
-当执行checkpoint时,innodb会将checkpoint LSN存储在文件的header中,在recovery过程中,所有的redo log文件都将被检查,并且基于最大的LSN来执行恢复操作。
-
-常用的redo log状态如下
-```bash
- # resize operation status
- Innodb_redo_log_resize_status
- # 当前redo log capacity
- Innodb_redo_log_capacity_resized
- Innodb_redo_log_checkpoint_lsn
- Innodb_redo_log_current_lsn
- Innodb_redo_log_flushed_to_disk_lsn
- Innodb_redo_log_logical_size
- Innodb_redo_log_physical_size
- Innodb_redo_log_read_only
- Innodb_redo_log_uuid
-```
-> 重做日志大小设置时,如果设置大小过大,那么在执行恢复操作时,可能需要花费很长时间;如果重做日志文件大小设置过小,可能会导致事务的日志需要多次切换重做日志文件。
->
-> 此外,重做日志太小会频繁发生async checkpoint,导致性能抖动。重做日志存在一个capacity,代表了最后的checkpoint不能够超过这个阈值,如果超过必须将缓冲区中的部分脏页刷新到磁盘中,此时可能会造成用户线程的阻塞。
-
-### redo log和binlog的区别
-#### 记录内容
-binlog记录的是一个事务的具体操作内容,该日志为逻辑日志。
-
-而innodb redo log记录的是关于某个页的修改,为物理日志。
-
-#### 写入时机
-binlog仅当事务提交前才进行提交,即只会写磁盘一次。
-
-redo log则是在事务运行过程中,不断有重做日志被写入到redo log file中。
-
-### redo log写入时机
-- master thread会每秒将redo log从buffer中刷新到redo log ile中,不露内事务是否已经提交
+- [文件](#文件)
+ - [参数](#参数)
+ - [参数查看](#参数查看)
+ - [参数类型](#参数类型)
+ - [动态参数修改](#动态参数修改)
+ - [静态参数修改](#静态参数修改)
+ - [日志文件](#日志文件)
+ - [错误日志](#错误日志)
+ - [慢查询日志](#慢查询日志)
+ - [log\_queries\_not\_using\_indexes](#log_queries_not_using_indexes)
+ - [查询日志](#查询日志)
+ - [二进制日志](#二进制日志)
+ - [max\_binlog\_size](#max_binlog_size)
+ - [binlog\_cache\_size](#binlog_cache_size)
+ - [binlog\_cache\_use](#binlog_cache_use)
+ - [binlog\_cache\_disk\_use](#binlog_cache_disk_use)
+ - [sync\_binlog](#sync_binlog)
+ - [innodb\_flush\_log\_at\_trx\_commit](#innodb_flush_log_at_trx_commit)
+ - [binlog\_format](#binlog_format)
+ - [使用statement可能会存在的问题](#使用statement可能会存在的问题)
+ - [mysqlbinlog](#mysqlbinlog)
+ - [pid文件](#pid文件)
+ - [表结构定义文件](#表结构定义文件)
+ - [表空间文件](#表空间文件)
+ - [innodb\_data\_file\_path](#innodb_data_file_path)
+ - [innodb\_file\_per\_table](#innodb_file_per_table)
+ - [redo log文件](#redo-log文件)
+ - [循环写入](#循环写入)
+ - [redo log capacity](#redo-log-capacity)
+ - [redo log和binlog的区别](#redo-log和binlog的区别)
+ - [记录内容](#记录内容)
+ - [写入时机](#写入时机)
+ - [redo log写入时机](#redo-log写入时机)
+
+
+# 文件
+## 参数
+### 参数查看
+mysql参数为键值对,可以通过`show variables`命令查看所有的数据库参数,并可以通过`like`来过滤参数名称。
+
+除了`show variables`命令之外,还能够在`performance_schema`下的`global_variables`视图来查找数据库参数,示例如下:
+```sql
+-- 查看innodb_buffer_pool_size参数
+show variables like 'innodb_buffer_pool_size'
+```
+上述`show variables`命令的执行结果为
+| Variable\_name | Value |
+| :--- | :--- |
+| innodb\_buffer\_pool\_size | 4294967296 |
+
+```sql
+select * from performance_schema.global_variables where variable_name like 'innodb_buffer_pool%';
+```
+上述sql的执行结果如下:
+| VARIABLE\_NAME | VARIABLE\_VALUE |
+| :--- | :--- |
+| innodb\_buffer\_pool\_chunk\_size | 134217728 |
+| innodb\_buffer\_pool\_dump\_at\_shutdown | ON |
+| innodb\_buffer\_pool\_dump\_now | OFF |
+| innodb\_buffer\_pool\_dump\_pct | 25 |
+| innodb\_buffer\_pool\_filename | ib\_buffer\_pool |
+| innodb\_buffer\_pool\_in\_core\_file | ON |
+| innodb\_buffer\_pool\_instances | 4 |
+| innodb\_buffer\_pool\_load\_abort | OFF |
+| innodb\_buffer\_pool\_load\_at\_startup | ON |
+| innodb\_buffer\_pool\_load\_now | OFF |
+| innodb\_buffer\_pool\_size | 4294967296 |
+
+### 参数类型
+mysql中的参数可以分为`动态`和`静态`两种类型,
+- 动态:动态参数代表可以在mysql运行过程中进行修改
+- 静态:代表在整个实例的声明周期内都不得进行修改
+
+#### 动态参数修改
+对于动态参数,可以在运行时通过`SET`命令来进行修改,`SET`命令语法如下:
+```sql
+set
+ | [global | session] system_var_name=expr
+ | [@@global. | @@session. | @@] system_var_name = expr
+```
+在上述语法中,`global`和`session`关键字代表该动态参数的修改是针对`当前会话`还是针对`整个实例的生命周期`。
+
+- 有些动态参数只能在会话范围内进行修改,例如`autocommit`
+- 有些参数修改后,实例整个生命周期内都会生效,例如`binglog_cache_size`
+- 有些参数既可以在会话范围内进行修改,又可以在实例声明周期范围内进行修改,例如`read_buffer_size`
+
+使用示例如下:
+
+查询read_buffer_size的global和session值
+```sql
+-- 查询read_buffer_size的global和session值
+select @@session.read_buffer_size,@@global.read_buffer_size;
+```
+返回结果为
+
+| @@session.read\_buffer\_size | @@global.read\_buffer\_size |
+| :--- | :--- |
+| 131072 | 131072 |
+
+设置@@session.read_buffer_size为524288
+```sql
+set @@session.read_buffer_size = 1024 * 512;
+```
+设置后,再次查询read_buffer_size的global和session值,结果为
+| @@session.read\_buffer\_size | @@global.read\_buffer\_size |
+| :--- | :--- |
+| 524288 | 131072 |
+
+在调用set命令修改session read_buffer_size参数后,session参数发生变化,但是global参数仍然为旧的值。
+
+> `set session xxx`命令并不会对global参数的值造成影响,新会话的参数值仍然为修改前的值。
+
+之后,再对global read_buffer_size值进行修改,执行如下命令
+```sql
+set @@global.read_buffer_size = 496 * 1024;
+```
+执行该命令后,sesion和global参数值为
+| @@session.read\_buffer\_size | @@global.read\_buffer\_size |
+| :--- | :--- |
+| 524288 | 507904 |
+
+> `set global xxx`命令只会修改global参数值,对session参数值不会造成影响,新的session其`session参数值, global参数值`和修改后的global参数值保持一致
+
+> 即使针对参数的global值进行了修改,其影响范围是当前实例的整个生命周期,`但是,其并不会对参数文件中的参数值进行修改,故而下次启动mysql实例时,仍然会从参数文件中取值,新实例的值仍然是修改前的值`。
+>
+> 如果想要修改下次启动实例的参数值,需要修改参数文件中该参数的值。(参数文件路径通常为`/etc/my.cnf`)
+
+#### 静态参数修改
+在运行时,如果尝试对静态参数进行修改,那么会发生错误,示例如下:
+```sql
+> set global datadir='/db/mysql'
+[2025-01-30 15:05:17] [HY000][1238] Variable 'datadir' is a read only variable
+```
+## 日志文件
+mysql中常见日志文件如下
+- 错误日志(error log)
+- 二进制日志(binlog)
+- 慢查询日志(slow query log)
+- 查询日志(log)
+
+### 错误日志
+错误日志针对mysql的启动、运行、关闭过程进行了记录,用户可以通过`show variables like 'log_error';`来获取错误日志的路径:
+```sql
+show variables like 'log_error';
+```
+其输出值如下:
+| Variable\_name | Value |
+| :--- | :--- |
+| log\_error | /var/log/mysql/mysqld.log |
+
+当mysql数据库无法正常启动时,应当首先查看错误日志。
+
+### 慢查询日志
+慢查询日志存在一个阈值,通过`long_query_time`参数来进行控制,该参数默认值为`10`,代表慢查询的限制为10s。
+
+通过`slow_query_log`参数,可以控制是否日志输出慢查询日志,默认为`OFF`,如果需要开启慢查询日志,需要将该值设置为`ON`。
+
+关于慢查询日志的输出地点,可以通过`log_output`参数来进行控制。该参数默认为`FILE`,支持`FILE, TABLE, NONE`。`log_output`支持制定多个值,多个值之间可以通过`,`分隔,当值中包含`NONE`时,以`NONE`优先。
+
+#### log_queries_not_using_indexes
+当`log_queryies_not_using_indexes`开启时,如果运行的sql语句没有使用索引,那么这条sql同样会被输出到慢查询日志。该参数默认关闭。
+
+`log_throttle_queries_not_using_idnexes`用于记录`每分钟允许记录到慢查询日志并且没有使用索引`的sql语句次数,该参数值默认为0,代表每分钟输出到慢查询日志中的数量没有限制。
+
+该参数主要用于防止大量没有使用索引的sql添加到慢查询日志中,造成慢查询日志大小快速增加。
+
+当慢查询日志中的内容越来越多时,可以通过mysql提供的工具`mysqldumpslow`命令,示例如下:
+```sql
+mysqldumpslow -s at -n 10 ${slow_query_log_path}
+```
+
+### 查询日志
+查询日志记录了对mysql数据库所有的请求信息,无论请求是否正确执行。
+
+查询日志通过`general_log`参数来进行控制,默认该参数值为`OFF`.
+
+### 二进制日志
+二进制日志(binary log)记录了针对mysql数据库执行的所有更改操作(不包含select以及show这类读操作)。
+
+对于update操作等,即使没有对数据库进行修改(affected rows为0),也会被写入到binary log中。
+
+二进制日志的主要用途如下:
+- 恢复(recovery):某些数据恢复需要二进制日志,例如在数据库全备份文件恢复后,用户可以通过二进制日志进行point-in-time的恢复
+- 复制(replication):通过将一台主机(master)的binlog同步到另一台主机(slave),并且在另一台主机上执行该binlog,可以令slave与master进行实时同步
+- 审计(audit):用户可以对binlog中的信息进行审计,判断是否存在对数据库进行的注入攻击
+
+通过参数`log_bin`可以控制是否启用二进制日志。
+
+binlog通常存放在`datadir`参数所指定的目录路径下。在该路径下,还存在`binlog.index`文件,该文件为binlog的索引文件,文件内容包含所有binlog的文件名称。
+
+#### max_binlog_size
+`max_binlog_size`参数控制单个binlog文件的最大大小,如果单个文件超过该值,会产生新的二进制文件,新binlog的后缀会+1,并且新文件的文件名会被记录到`.index`文件中。
+
+`max_binlog_size`的默认值大小为`1G`。
+
+#### binlog_cache_size
+当使用innodb存储引擎时,所有未提交事务的binlog会被记录到缓存中,等到事务提交后,会将缓存中的binlog写入到文件中。缓存大小通过`binlog_cache_size`决定,该值默认为`32768`,即`32KB`。
+
+`binlog_cache_size`是基于会话的,`在每个线程开启一个事务时,mysql会自动分配一个大小为binlog_cache_size大小的缓存,因而该值不能设置过大`。
+
+当一个事务的记录大于设定的`binlog_cache_size`时,mysql会将缓冲中的日志写入到一个临时文件中,故而,该值无法设置过小。
+
+通过`show global status like 'binlog_cache%`命令可以查看`binlog_cache_use`和`binlog_cache_disk_use`的状态,可以通过上述两个状态判断binlog cache大小是否合适。
+
+##### binlog_cache_use
+`binlog_cache_use`记录了使用缓冲写binlog的次数
+
+##### binlog_cache_disk_use
+`binlog_cache_disk_use`记录了使用临时文件写二进制日志的次数
+
+#### sync_binlog
+`sync_binlog`参数控制mysql server同步binlog到磁盘的频率,该值默认为`1`
+
+- 0: 如果参数值为0,代表mysql server禁用binary log同步到磁盘。mysql会依赖操作系统将binary log刷新到磁盘中,该设置性能最佳,但是遇到操作系统崩溃时,可能会出现mysql事务提交但是还没有同步到binary log的场景
+- 1: 如果参数值设置为1,代表在事务提交之前将binary log同步到磁盘中,该设置最安全,但是会增加disk write次数,对性能会带来负面影响。在操作系统崩溃的场景下,binlog中缺失的事务还只处于prepared状态,从而确保binlog中没有事务丢失
+- N:当参数值被设置为非`0,1`的值时,每当n个binlog commit groups被收集到后,同步binlog到磁盘。在这种情况下,可能会发生事务提交但是还没有被刷新到binlog中,`当n值越大时,性能会越好,但是也会增加数据丢失的风险`
+
+为了在使用innodb事务和replciation时获得最好的一致性和持久性,请使用如下设置:
+```cnf
+sync_binlog=1
+innodb_flush_log_at_trx_commit=1
+```
+
+#### innodb_flush_log_at_trx_commit
+innodb_flush_log_at_trx_commit用于控制redo log的刷新。
+
+该参数用于平衡`commit操作ACID的合规性`以及`更高性能`。通过修改该参数值,可以实现更佳的性能,但是在崩溃时可能会丢失事务:
+- 1: 1为该参数默认值,代表完全的ACID合规性,日志在每次事务提交后被写入并刷新到磁盘中
+- 0: 日志每秒被写入和刷新到磁盘中,如果事务没有被刷新,那么日志将会在崩溃中被丢失
+- 2: 每当事务提交后,日志将会被写入,并且每秒钟都会被刷新到磁盘中。如果事务没有被刷新,崩溃同样会造成日志的丢失
+
+如果当前数据库为slave角色,那么其不会把`从master同步的binlog`写入到自己的binlog中,如果要实现`master=>slave=>slave`的同步架构,必须设置`log_slave_updates`参数。
+
+#### binlog_format
+binlog_format用于控制二进制文件的格式,可能有如下取值:
+- statement: 二进制文件记录的是日志的逻辑sql语句
+- row:记录表的行更改情况,默认值为`row`
+- mixed: 如果参数被配置为mixed,mysql默认会采用`statement`格式进行记录,但是在特定场景能够下会使用`row`格式:
+ - 使用了uuid, user, current_user,found_rows, row_count等不确定函数
+ - 使用了insert delay语句
+ - 使用了用户自定义函数
+ - 使用了临时表
+
+##### 使用statement可能会存在的问题
+在使用statement格式时,可能会存在如下问题
+- master运行rand,uuid等不确定函数时,或使用触发器操作时,会导致主从服务器上的数据不一致
+- innodb的默认事务隔离级别为`repetable_read`,如果使用`read_commited`级别时,statement格式可能会导致丢失更新的情况,从而令master和slave的数据不一致
+
+binlog为动态参数,可以在数据库运行时进行修改,并且可以针对session和global进行修改。
+
+#### mysqlbinlog
+在查看二进制日志时,可以使用`mysqlbinlog`命令,示例如下
+```bash
+mysqlbinlog --start-position=203 ${binlog_path}
+```
+
+## pid文件
+mysql实例启动时,会将进程id写入到一个文件中,该文件被称为pid文件。
+
+pid文件路径通过`pid_file`参数来进行控制,fedora中默认路径为`/run/mysqld/mysqld.pid`。
+
+## 表结构定义文件
+mysql中数据的存储是根据表进行的,每个表都有与之对应的文件。无论表采用何种存储引擎,都会存在一个以`frm`为后缀的文件,该文件中保存了该表的表结构定义。
+
+> mysql 8中,schema对应目录下不再包含frm文件。
+
+## 表空间文件
+innodb采用将存储的数据按照表空间(tablespace)进行存放的设计。在默认配置下,将会有一个初始大小为10MB,名称为ibdata1的文件,该文件为默认的表空间文件。
+
+### innodb_data_file_path
+可以通过`innodb_data_file_path`参数对默认表空间文件进行设置,示例如下:
+```sql
+innodb_data_file_path=datafile_spec1[;datafile_spec2]...
+```
+用户可以通过多个文件组成一个表空间,示例如下:
+```sql
+innodb_data_file_path=/db/ibdata1:2000M;/dr2/db/ibdata2:2000M;autoextend
+```
+在上述配置中,表空间由`/db/ibdata1`和`/dr2/db/ibdata2`两个文件组成,如果两个文件位于不同的磁盘上,那么磁盘的负载将会被平均,数据库的整体性能将会被提高。
+
+同时,在上述示例中,为两个文件都指定了后续属性,含义如下:
+- ibdata1:文件大小为2000M
+- ibdata2:文件大小为2000M,并且当文件大小被用完后,文件会自动增长
+
+当`innodb_data_file_path`被设置后,所有基于innodb存储引擎的表,其数据都会记录到该共享表空间中。
+
+### innodb_file_per_table
+如果`innodb_file_per_table`被启用后(默认启用),则每个基于innodb存储引擎的表都可以有一个独立的表空间,独立表空间的命名规则为`表名+.ibd`。
+
+通过innodb_file_per_table,用户不需要将所有的数据都放置在默认的表空间中。
+
+> `innodb_file_per_table`所产生的独立表空间文件,其仅存储该表的数据、索引和插入缓冲BITMAP信息,其余信息仍然存放在默认的表空间中。
+
+## redo log文件
+redo log是一个基于磁盘的数据结构,用于在crash recovery过程中纠正由`未完成事务写入的错误数据`。
+
+> 在一般操作中,redo log对那些`会造成表数据发生改变的请求`进行encode操作,请求通常由sql statement或地级别api发起。
+
+redo log通常代表磁盘上的redo log file。写入重做日志文件的数据通常基于受影响的记录进行编码。在数据被写入到redo log file中时,LSN值也会不断增加。
+
+### 循环写入
+innodb会按顺序写入redo log文件,例如redo log file group中存在两个文件,innodb会先写文件1,文件1写满后会切换文件2,在文件2写满后,重新切换到文件1。
+
+### redo log capacity
+从mysql 8.0.30开始,`innodb_redo_log_capacity`参数用于控制redo log file占用磁盘空间的大小。该参数可以在实例启动时进行设置,也可以通过`set global`来进行设置。
+
+`innodb_redo_log_capacity`默认值为`104857600`,即`100M`。
+
+redo log文件默认位于`datadir`路径下的`#innodb_redo`目录下。innodb会尝试维护32个redo log file,每个redo log file文件大小都相同,为`1/32 * innodb_redo_log_capacity`。
+
+redo log file将会使用`#ib_redoN`的命名方式,`N`是redo log file number。
+
+innodb redo log file分为如下两种:
+- ordinary:正在被使用的redo log file
+- spare:等待被使用的redo log file
+
+> 相比于ordinary redo log file,spare redo log file的名称中还包含了`_tmp`后缀
+
+每个oridnary redo log file都关联了一个制定的LSN范围,可以通过查询`performance_schema.innodb_redo_log_files`表里获取LSN范围。
+
+示例如下:
+```sql
+select file_name, start_lsn, end_lsn from performance_schema.innodb_redo_log_files;
+```
+查询结果示例如下:
+| file\_name | start\_lsn | end\_lsn |
+| :--- | :--- | :--- |
+| ./#innodb\_redo/#ib\_redo6 | 19656704 | 22931456 |
+
+当执行checkpoint时,innodb会将checkpoint LSN存储在文件的header中,在recovery过程中,所有的redo log文件都将被检查,并且基于最大的LSN来执行恢复操作。
+
+常用的redo log状态如下
+```bash
+ # resize operation status
+ Innodb_redo_log_resize_status
+ # 当前redo log capacity
+ Innodb_redo_log_capacity_resized
+ Innodb_redo_log_checkpoint_lsn
+ Innodb_redo_log_current_lsn
+ Innodb_redo_log_flushed_to_disk_lsn
+ Innodb_redo_log_logical_size
+ Innodb_redo_log_physical_size
+ Innodb_redo_log_read_only
+ Innodb_redo_log_uuid
+```
+> 重做日志大小设置时,如果设置大小过大,那么在执行恢复操作时,可能需要花费很长时间;如果重做日志文件大小设置过小,可能会导致事务的日志需要多次切换重做日志文件。
+>
+> 此外,重做日志太小会频繁发生async checkpoint,导致性能抖动。重做日志存在一个capacity,代表了最后的checkpoint不能够超过这个阈值,如果超过必须将缓冲区中的部分脏页刷新到磁盘中,此时可能会造成用户线程的阻塞。
+
+### redo log和binlog的区别
+#### 记录内容
+binlog记录的是一个事务的具体操作内容,该日志为逻辑日志。
+
+而innodb redo log记录的是关于某个页的修改,为物理日志。
+
+#### 写入时机
+binlog仅当事务提交前才进行提交,即只会写磁盘一次。
+
+redo log则是在事务运行过程中,不断有重做日志被写入到redo log file中。
+
+### redo log写入时机
+- master thread会每秒将redo log从buffer中刷新到redo log ile中,不露内事务是否已经提交
- innodb_flush_log_at_trx_commit控制redo log的刷新时机,默认情况下,在事务提交前会将数据从redo log buffer刷新到redo log file中
\ No newline at end of file
diff --git a/mysql/mysql文档/mysql_表.md b/mysql/mysql文档/mysql_表.md
index ea737b3..96d2e25 100644
--- a/mysql/mysql文档/mysql_表.md
+++ b/mysql/mysql文档/mysql_表.md
@@ -1,713 +1,713 @@
-- [表](#表)
- - [索引组织表](#索引组织表)
- - [innodb逻辑存储结构](#innodb逻辑存储结构)
- - [表空间](#表空间)
- - [innodb\_file\_per\_table](#innodb_file_per_table)
- - [段(segment)](#段segment)
- - [区(Extent)](#区extent)
- - [页(Page)](#页page)
- - [行](#行)
- - [innodb行记录格式](#innodb行记录格式)
- - [Compact](#compact)
- - [变长字段长度列表](#变长字段长度列表)
- - [NULL标志位](#null标志位)
- - [记录头信息](#记录头信息)
- - [行溢出数据](#行溢出数据)
- - [dynamic](#dynamic)
- - [char存储结构](#char存储结构)
- - [innodb数据页结构](#innodb数据页结构)
- - [File Header](#file-header)
- - [Infimum和Supremum record](#infimum和supremum-record)
- - [user record 和 free space](#user-record-和-free-space)
- - [page directory](#page-directory)
- - [B+树索引](#b树索引)
- - [File Trailer](#file-trailer)
- - [完整性校验](#完整性校验)
- - [分区表](#分区表)
- - [partition keys \& primary keys \& unique keys](#partition-keys--primary-keys--unique-keys)
- - [表中不存在唯一索引](#表中不存在唯一索引)
- - [后续向分区表添加唯一索引](#后续向分区表添加唯一索引)
- - [对非分区表进行分区](#对非分区表进行分区)
- - [分区类型](#分区类型)
- - [RANGE](#range)
- - [information\_schema.partitions](#information_schemapartitions)
- - [看select语句查询了哪些分区](#看select语句查询了哪些分区)
- - [插入超过分区范围的数据](#插入超过分区范围的数据)
- - [向分区表中添加分区](#向分区表中添加分区)
- - [向分区表中删除分区](#向分区表中删除分区)
- - [LIST](#list)
- - [HASH](#hash)
- - [新增HASH分区](#新增hash分区)
- - [减少HASH分区](#减少hash分区)
- - [LINEAR HASH](#linear-hash)
- - [KEY \& LINEAR KEY](#key--linear-key)
- - [COLUMNS](#columns)
- - [range columns](#range-columns)
- - [list columns](#list-columns)
- - [子分区](#子分区)
- - [分区中的NULL值](#分区中的null值)
- - [分区和性能](#分区和性能)
- - [不分区](#不分区)
- - [按id进行分区](#按id进行分区)
- - [在表和分区之间交换数据](#在表和分区之间交换数据)
-
-
-# 表
-## 索引组织表
-innodb存储引擎中,表都是根据主键顺序组织存放的,这种存储方式被称为索引组织表(index organized table)。在innodb存储引擎表中,每张表都有主键(primary key),如果在创建表时没有显式指定主键,那么innodb会按照如下方式创建主键:
-- 首先判断表中是否存在非空的唯一索引(unique not null)字段,如果有,则其为主键
-- 如果不存在非空唯一索引,那么innodb会自动创建一个6字节大小的指针作为主键
-
-如果有多个非空唯一索引,innodb存储引擎将会选择第一个定义的非空唯一索引作为主键。
-
-## innodb逻辑存储结构
-在innodb的存储逻辑结构中,所有的数据都被逻辑存放在表空间(table space)中。表空间则由`段(segement),区(extent),页(page)`组成。
-
-组成如图所示:
-
-
-
-如上图所示,HTTP/2和HTTP/3在传输多个资源时,都只创建了一个连接。但是,QUIC中不同byte streams是独立传输的,拥有不同的传输路径,并且不同byte streams之间不会彼此阻塞。
-
-即使QUIC解决了HTTP/2中引入的HOL问题,乱序传输也会存在弊端:byte streams并不会按照其被发送的顺序到达。例如,在使用乱序传输时,最不重要的资源可能会最先到达。
-
-#### Flexible Bandwidth Management
-带宽管理用于在packets和streams之间按照最优的方式对网络带宽进行分配。这是至关重要的功能,发送方和接收方的机器以及二者之间的网络节点处理packets的速度都有所不同,并且速度也会动态变化。
-
-带宽管理有助于避免网络中的数据溢出和拥塞,这些问题可能会导致server响应速度变慢,同时也可能会带来安全问题。
-
-UDP中并没有内置带宽控制,QUIC则是在HTTP3协议栈中负责该功能,其对TCP带宽管理中的两大部分进行了重新实现:
-- 流控制: 其在接收方限制了数据发送的速率,用于避免发送方造成接收方过载
-- 拥塞控制:其限制了发送方和接收方之间的路径中每一个节点的发送速率,用于避免网络拥塞
-
-##### Pre-Stream Flow Control
-为了支持独立的stream,QUIC采用了per-stream based flow control。其在两个级别控制了stream data的带宽消耗:
-- 对于每个独立的流,都设置了一个可分配给其的最大数据数量
-- 在整个连接范的围内,设置了active streams最大的累积数量
-
-通过per-stream flow control,QUIC限制了同时可以发送的数据数量,用于避免接收方过载,并且在多个streams间大致公平的分配网络容量。
-
-##### 拥塞控制算法
-QUIC允许实现选择不同的拥塞控制算法,使用最广泛的算法如下:
-- NewReno:TCP使用的拥塞控制算法
-- CUBIC: 和NewReno类似,但是使用了cubic function而不是linear function
-- BBR
-
-在网络状况较差的场景下,不同的拥塞控制算法性能可能存在较大差异。
-
+- [HTTP3 \& QUIC Protocols](#http3--quic-protocols)
+ - [What is HTTP3](#what-is-http3)
+ - [TCP/IP模型中HTTP3 vs QUIC](#tcpip模型中http3-vs-quic)
+ - [QUIC Protocol](#quic-protocol)
+ - [What is QUIC Used For](#what-is-quic-used-for)
+ - [HTTP/1.1 vs HTTP/2 vs HTTP/3: Main differences](#http11-vs-http2-vs-http3-main-differences)
+ - [Best Features of HTTP/3 and QUIC](#best-features-of-http3-and-quic)
+ - [QUIC handshake](#quic-handshake)
+ - [0-RTT on Prior Connections](#0-rtt-on-prior-connections)
+ - [Head-of-Line Blocking Removal](#head-of-line-blocking-removal)
+ - [HOL blocking术语](#hol-blocking术语)
+ - [How does QUIC remove head-of-line blocking](#how-does-quic-remove-head-of-line-blocking)
+ - [Flexible Bandwidth Management](#flexible-bandwidth-management)
+ - [Pre-Stream Flow Control](#pre-stream-flow-control)
+ - [拥塞控制算法](#拥塞控制算法)
+
+
+# HTTP3 & QUIC Protocols
+http3旨在通过QUIC(下一代传输层协议)来令网站更快、更安全。
+
+在协议高层,http3提供了和http2相同的功能,例如header compression和stream优先级控制。然而,在协议底层,QUIC传输层协议彻底修改了web传输数据的方式。
+
+## What is HTTP3
+HTTP是一个应用层的网络传输协议,定义了client和server之间的request-reponse机制,允许client/server发送和接收HTML文档和其他文本、meidia files。
+
+http3最初被称为`HTTP-over-QUIC`,其主要目标是令http语法及现存的http/2功能能够和QUIC传输协议兼容。
+
+故而,`HTTP/3`的所有新特性都来源于QUIC层,包括内置加密、新型加密握手、对先前的连接进行zero round-trip恢复,消除头部阻塞问题以及原生多路复用。
+
+## TCP/IP模型中HTTP3 vs QUIC
+通过internet传输信息是复杂的操作,涉及到软件和硬件层面。由于不同的设备、工具、软件都拥有不同的特性,故而单一协议无法描述完整的通信流程。
+
+故而,网络通信是已于通信的协议栈实现的,协议栈中每一层职责都不同。为了使用网络系统来通信,host必须实现构成互联网协议套件的一系列分层协议集。通常,主机至少为每层实现一个协议。
+
+而HTTP则是应用层协议,令web server和web browser之间可以相互通信。http消息(request/reponse)在互联网中则是通过传输层协议来进行传递:
+- 在http/2和http/1.1中,通过TCP协议来进行传递
+- 在`http/3`中,则是通过QUIC协议来进行传递
+
+> `QUIC`为http/3新基于的传输层协议,之前http都基于tcp协议进行传输
+
+## QUIC Protocol
+`QUIC`协议是一个通用的传输层协议,其可以和任意兼容的应用层协议来一起使用,HTTP/3是QUIC的最新用例。
+
+`QUIC`协议基于`UDP`协议构建,其负责server和client之间应用数据的物理传输。UDP协议是一个简单、轻量的协议,其传输速度高但是缺失可靠性、安全性等特性。QUIC实现了这些高层的传输特性,故而可以用于优化http数据通过网络的传输。
+
+在HTTP/3中,HTTP的连接从`TCP-based`迁移到了`UDP-based`,底层的网络通信结构都发生了变化。
+
+### What is QUIC Used For
+QUIC其创建是同于代替`TCP`协议的,QUIC作为传输层协议,相比于TCP更加灵活,性能问题更少。QUIC协议继承了安全传输的特性,并且拥有更快的adoption rate。
+
+QUIC协议底层基于UDP协议的原因是`大多数设备只支持TCP和UDP的端口号`。
+
+除此之外,`QUIC`还利用了UDP的如下特性:
+- UDP的connectionless特性可以使其将多路复用下移到传输层,并且基于UDP的QUIC实现并不会和TCP协议一样存在头部阻塞的问题
+- UDP的间接性能够令QUIC重新实现TCP的可靠性和带宽管理功能
+
+基于QUIC协议的传输和TCP相比是完全不同的方案:
+- 在底层,其是无连接的,其底层基于UDP协议
+- 在高层,其是`connection-oriented`的,其在高层重新实现了TCP协议中连接建立、loss detection等特性,从而确保了数据的可靠传输
+
+综上,QUIC协议结合了UDP和TCP两种协议的优点。
+
+除了上述优点外,QUIC还`在传输层实现了高级别的安全性`。QUIC集成了`TLS 1.3`协议中的大部分特性,令其和自身的传输机制相兼容。在`HTTP/3` stack中,encryption并非是可选的,而是内置特性。
+
+TCP, UDP, QUIC协议的相互比较如下:
+| | TCP | UDP | QUIC |
+| :-: | :-: | :-: | :-: |
+Layer in the TCP/IP model | transport | transport | transport |
+| place in the TCP/IP model | on top of ipv4/ipv6 | on top of ipv4/ipv6 | on top of UDP |
+| connection type | connection-oriented | connectionless | connection-oriented |
+| order of delivery | in-order delivery | out-of-order delivery | out-of-order delivery between streams, in order delivery within stremas |
+| guarantee of delivery | guaranteed | no guarantee of delivery | guaranteed |
+| security | unencrypted | unencrypted | encrypted |
+| data identification | knows nothing about the data it transports | knows nothing about the data it transports | use stream IDs to identify the independent streams it transports |
+
+## HTTP/1.1 vs HTTP/2 vs HTTP/3: Main differences
+H3除了在底层协议栈传输层中引入QUIC和UDP协议外,还存在其他改动,具体如图所示:
+
+
+HTTP/3-QUIC-UDP stack和TCP-based版本的HTTP最重要的区别如下:
+- QUIC集成了TLS 1.3协议中绝大部分特性,encryption从应用层移动到了传输层
+- HTTP/3在不同的streams间并不会对连接进行多路复用,多路复用的特性是由QUIC在传输层执行的
+ - 传输层的多路复用移解决了HTTP/2中TCP中头部阻塞的问题(HTTP/1.1中并不存在头部阻塞问题,因为其会开启多个TCP连接,并且会提供pipelining选项,后来该方案被发现拥有严重实现缺陷,被替换为了HTTP/2中应用层的多路复用)
+
+## Best Features of HTTP/3 and QUIC
+HTTP/3和QUIC的新特性能够令server connections速度更快、传输更安全、可靠性更高。
+
+### QUIC handshake
+在HTTP2中,client和server在执行handshake的过程中,至少需要2次round-trips:
+- tcp handshake需要一次round-trip
+- tls handleshake至少需要一次round-trip
+
+和QUIC则将上述两次handshakes整合成了一个,HTTP3仅需一次round-trip就可以在client和server之间建立一个secure connection。`QUIC可以带来更快的连接建立和更低的延迟。`
+
+QUIC集成了`TLS1.3`中的绝大多数特性,`TLS1.3`是目前最新版本的`Transport Layer Security`协议,其代表:
+- HTTP/3中,消息的加密是强制的,并不像HTTP/1.1和HTTP/2中一样是可选的。在使用HTTP/3时,所有的消息都默认通过encrypted connection来进行发送。
+- TLS 1.3引入了一个`improved cryptographic handshake`,在client和server间仅需要一次round-trip;而TLS 1.2中则需要两次round-trips用于认证
+ - 而在QUIC中,则将该`improved cryptographic handshake`和其本身用于连接创建的handshake进行了整合,并替代了TCP的handshake
+- 在HTTP/3中,消息都是在传输层加密的,故而加密的信息比HTTP/1.1和HTTP/2中都更多
+ - 在HTTP/1.1和HTTP/2协议栈中,TLS都运行在应用层,故而HTTP data是加密的,但是,TCP header则是明文发送的,TCP header的明文可能会带来一些安全问题
+ - 在HTTP/3 stack中,TLS运行在传输层,故而不仅http message被加密,大多数QUIC packet header也是被加密的
+
+简单来说,HTTP/3使用的传输机制相比于TCP-based HTTP版本来说要更加安全。(传输层协议本身的header也被加密)
+
+### 0-RTT on Prior Connections
+对于先前存在的connections,QUIC利用了TLS 1.3的`0-RTT`特性。
+
+`0-RTT`代表zero round-trip time resumption,是TLS 1.3中引入的一个新特性。
+
+TLS session resumption通过复用先前建立的安全参数,减少建立secure connection所花费的时间。当client和server频繁建立连接并断开时,这将带来性能改善。
+
+通过0-RTT resumption,client可以在连接的第一个round-trip中发送http请求,复用先前建立的cryptographic keys。
+
+下面展示了H2和H3 stack在建立连接时的区别:
+
+
+
+- 当使用HTTP2和TLS 1.2时,client发送第一个http request需要4个round-trip
+- 在使用HTTP2和TLS 1.3时,client发送第一个http equest需要2、3个round-trip(根据是否使用0-rtt有所不同)
+- 在使用HTTP3和QUIC时,其默认包含TLS 1.3,其可以在1、2个round-trip内发送第一个http请求(根据是否复用先前连接的加密信息)
+
+### Head-of-Line Blocking Removal
+HTTP/3协议栈和HTTP/2协议栈的结构不同,其解决了HTTP/2中最大的性能问题:`head-of-line`阻塞。
+- 该问题主要发生在HTTP/2中packet丢失的场景下,直到丢失的包被重传前,整个的数据传输过程都会停止,所有packets都必须在网络上等待,这将会导致页面的加载时间延长
+
+在HTTP/3中,行首阻塞通过原生的多路复用解决了。这是QUIC最重要的特性之一。
+
+#### HOL blocking术语
+如下是HOL问题涉及到的概念:
+- byte stream:是通过网络发送的字节序列。bytes作为不同大小的packets被传输。byte stream本质上是单个资源(file)的物理表现形式,通过网络来发送
+- 复用:通过复用,可以在一个connection上传输多个byte streams,这将代表浏览器可以在同一个连接上同时加载多个文件
+ - 在HTTP/1.1中,并不支持复用,其会未每个byte stream新开一个tcp连接。HTTP/2中引入了应用层的复用,其只会建立一个TCP连接,并通过其传输所有byte streams。故而,仅有HTTP/2会存在HOL问题
+- HOL blocking:这是由tcp byte stream抽象造成的性能问题。TCP并不知晓其所传输的数据,并将其所传输的所有数据都看作一个byte stream。故而,如果在网络传输过程中,任意位置的packet发生的丢失,所有在复用连接中的其他packets都会停止传输,并等待丢失的packets被重传
+ - 这代表,复用的连接中,所有byte streams都会被TCP协议看作是一个byte stream,故而stream A中的packet丢失也会造成stream B的传输被阻塞,直至丢失packet被重传
+ - 并且,TCP使用了in-order传输,如果发生packet丢失,那么将阻塞整个的传输过程。在高丢包率的环境下,这将极大程度上影响传输速度。即使在HTTP/2中已经引入了性能优化特性,在2%丢包率的场景下,也会比HTTP/1.1的传输速度更慢
+- native multiplexing:在HTTP/3协议栈中,复用被移动到了传输层,实现了原生复用。QUIC通过stream ID来表示每个byte stream,并不像TCP一样将所有byte streams都看作是一个。
+
+#### How does QUIC remove head-of-line blocking
+QUIC基于UDP实现,其使用了out-of-order delivery,故而每个byte stream都通过网络独立的进行传输。然而,为了可靠性,QUIC确保了在同一byte stream内packets的in-order delivery,故而相同请求中关联的数据到达的顺序是一致的。
+
+QUIC标识了所有byte stream,并且streams是独立进行传输的,如果发生packet丢失,其他byte streams并不会停止并等待重传。
+
+下图中展示了QUIC原生复用和HTTP2应用层复用的区别:
+
+
+如上图所示,HTTP/2和HTTP/3在传输多个资源时,都只创建了一个连接。但是,QUIC中不同byte streams是独立传输的,拥有不同的传输路径,并且不同byte streams之间不会彼此阻塞。
+
+即使QUIC解决了HTTP/2中引入的HOL问题,乱序传输也会存在弊端:byte streams并不会按照其被发送的顺序到达。例如,在使用乱序传输时,最不重要的资源可能会最先到达。
+
+#### Flexible Bandwidth Management
+带宽管理用于在packets和streams之间按照最优的方式对网络带宽进行分配。这是至关重要的功能,发送方和接收方的机器以及二者之间的网络节点处理packets的速度都有所不同,并且速度也会动态变化。
+
+带宽管理有助于避免网络中的数据溢出和拥塞,这些问题可能会导致server响应速度变慢,同时也可能会带来安全问题。
+
+UDP中并没有内置带宽控制,QUIC则是在HTTP3协议栈中负责该功能,其对TCP带宽管理中的两大部分进行了重新实现:
+- 流控制: 其在接收方限制了数据发送的速率,用于避免发送方造成接收方过载
+- 拥塞控制:其限制了发送方和接收方之间的路径中每一个节点的发送速率,用于避免网络拥塞
+
+##### Pre-Stream Flow Control
+为了支持独立的stream,QUIC采用了per-stream based flow control。其在两个级别控制了stream data的带宽消耗:
+- 对于每个独立的流,都设置了一个可分配给其的最大数据数量
+- 在整个连接范的围内,设置了active streams最大的累积数量
+
+通过per-stream flow control,QUIC限制了同时可以发送的数据数量,用于避免接收方过载,并且在多个streams间大致公平的分配网络容量。
+
+##### 拥塞控制算法
+QUIC允许实现选择不同的拥塞控制算法,使用最广泛的算法如下:
+- NewReno:TCP使用的拥塞控制算法
+- CUBIC: 和NewReno类似,但是使用了cubic function而不是linear function
+- BBR
+
+在网络状况较差的场景下,不同的拥塞控制算法性能可能存在较大差异。
+
diff --git a/java se/垃圾回收和引用.md b/java se/垃圾回收和引用.md
index 70c62c9..dd9b2a9 100644
--- a/java se/垃圾回收和引用.md
+++ b/java se/垃圾回收和引用.md
@@ -1,109 +1,109 @@
-- [垃圾回收和引用](#垃圾回收和引用)
- - [finalize](#finalize)
- - [引用](#引用)
- - [Reference](#reference)
- - [get](#get)
- - [clear](#clear)
- - [enqueue](#enqueue)
- - [isEnqueue](#isenqueue)
- - [引用的可达性](#引用的可达性)
- - [强可达(strongly reachable)](#强可达strongly-reachable)
- - [软可达(softly reachable)](#软可达softly-reachable)
- - [弱可达(weakly reachable)](#弱可达weakly-reachable)
- - [终结器可达(finalizer reachable)](#终结器可达finalizer-reachable)
- - [幽灵可达(phantom reachable)](#幽灵可达phantom-reachable)
- - [引用类型](#引用类型)
- - [软引用(SoftReference)](#软引用softreference)
- - [弱引用(WeakReference)](#弱引用weakreference)
- - [幽灵可达](#幽灵可达)
- - [Weak Hash Map](#weak-hash-map)
- - [引用队列](#引用队列)
- - [ReferenceQueue.poll](#referencequeuepoll)
- - [ReferenceQueue.remove](#referencequeueremove)
- - [弱引用和软引用的使用](#弱引用和软引用的使用)
-
-# 垃圾回收和引用
-## finalize
-finalize方法将会在对象的空间被回收之前被调用。如果一个对象被垃圾回收器判为不可达而需要被回收时,垃圾回收器将调用该对象的finalize方法,通过finalize方法可以清除对象的一些非内存资源。
-在每个对象中,finalize方法最多被调用一次。
-> finalize方法可以抛出任何异常,但是抛出的异常将被垃圾回收器忽略。
-
-在finalize方法调用时,该对象引用的其他对象可能也是垃圾对象,并且已经被回收。
-## 引用
-### Reference
-Reference是一个抽象类,是所有特定引用类的父类。
-#### get
-```java
-public Object get()
-```
-将会返回引用对象指向的被引用对象
-#### clear
-```java
-public void clear()
-```
-清空引用对象从而使其不指向任何对象
-#### enqueue
-```java
-public boolean enqueue()
-```
-如果存在引用对象,将引用对象加入到注册的引用队列中,如果加入队列成功,返回true;如果没有成功加入到队列,或者该引用对象已经在队列中,那么返回false
-#### isEnqueue
-```java
-public boolean isEnqueue()
-```
-如果该引用对象已经被加入到引用队列中,那么返回true,否则返回false
-### 引用的可达性
-#### 强可达(strongly reachable)
-至少通过一条强引用链可达
-#### 软可达(softly reachable)
-不是强可达,但是至少可以通过一条包含软引用的引用链可达
-#### 弱可达(weakly reachable)
-不是弱可达,但是至少通过一条包含弱引用的引用链可达
-#### 终结器可达(finalizer reachable)
-不是弱可达,但是该对象的finalize方法尚未执行
-#### 幽灵可达(phantom reachable)
-如果finalize方法已经执行,但是可通过至少一条包含幽灵引用的引用链可达
-### 引用类型
-#### 软引用(SoftReference)
-对于软可达的对象,垃圾回收程序会随意进行处置,如果可用内存很低,回收器会清空SoftReference对象中的引用,之后该被引用对象则能被回收
-> 在抛出OOM之前,所有的SoftReference引用将会被清空
-
-#### 弱引用(WeakReference)
-弱可达对象将会被垃圾回收器回收,如果垃圾回收器认为对象是弱可达的,所有指向其的WeakReference对象都会被清空
-
-#### 幽灵可达
-幽灵可达并不是真正的可达,虚引用并不会影响对象的生命周期,如果一个对象和虚引用关联,则该对象跟没有与该虚引用关联一样,在任何时候都有可能被垃圾回收。虚引用主要用于跟踪对象垃圾回收的活动。
-
-### Weak Hash Map
-WeakHashMap会使用WeakReference来存储key。
-如果垃圾回收器发现一个对象弱可达时,会将弱引用放入到引用队列中。WeakHashMap会定期检查引用队列中新到达的弱引用,并且新到的弱引用代表该key不再被使用,WeakHashMap会移除关联的entry。
-
-
-### 引用队列
-如果对象的可达性状态发生了改变,那么执行该对象的引用类型将会被放置到引用队列中。引用队列通常被垃圾回收器使用。
-也可以在自己的代码中对引用队列进行使用,通过引用队列,可以监听对象的可达性改变。
-> 例如当对象不再被强引用,变为弱可达时,引用将会被添加到引用队列中,再通过代码监听引用队列的变化,即可监听到对象可达性的变化
-
-> ReferenceQueue是线程安全的。
-
-#### ReferenceQueue.poll
-```java
-pulbic Reference poll()
-```
-该方法会删除并且返回队列中的下一个引用对象,若队列为空,则返回值为null
-
-#### ReferenceQueue.remove
-```java
-public Reference remove() throws InterruptedException
-```
-该方法同样会删除并返回队列中下一个引用对象,但是该方法在队列为空时会无限阻塞下去
-```java
-public Reference remove(long timeout) throws InterruptedException
-```
-
-引用对象在构造时,会和特定的引用队列相关联,当被引用对象的可达性状态发生变化时,被添加到引用队列中。在被添加到队列之前,引用对象都已经被清空。
-
-### 弱引用和软引用的使用
-弱引用和软引用都提供两种类型的构造函数,
-- 只接受被引用对象,并不将引用注册到引用队列
+- [垃圾回收和引用](#垃圾回收和引用)
+ - [finalize](#finalize)
+ - [引用](#引用)
+ - [Reference](#reference)
+ - [get](#get)
+ - [clear](#clear)
+ - [enqueue](#enqueue)
+ - [isEnqueue](#isenqueue)
+ - [引用的可达性](#引用的可达性)
+ - [强可达(strongly reachable)](#强可达strongly-reachable)
+ - [软可达(softly reachable)](#软可达softly-reachable)
+ - [弱可达(weakly reachable)](#弱可达weakly-reachable)
+ - [终结器可达(finalizer reachable)](#终结器可达finalizer-reachable)
+ - [幽灵可达(phantom reachable)](#幽灵可达phantom-reachable)
+ - [引用类型](#引用类型)
+ - [软引用(SoftReference)](#软引用softreference)
+ - [弱引用(WeakReference)](#弱引用weakreference)
+ - [幽灵可达](#幽灵可达)
+ - [Weak Hash Map](#weak-hash-map)
+ - [引用队列](#引用队列)
+ - [ReferenceQueue.poll](#referencequeuepoll)
+ - [ReferenceQueue.remove](#referencequeueremove)
+ - [弱引用和软引用的使用](#弱引用和软引用的使用)
+
+# 垃圾回收和引用
+## finalize
+finalize方法将会在对象的空间被回收之前被调用。如果一个对象被垃圾回收器判为不可达而需要被回收时,垃圾回收器将调用该对象的finalize方法,通过finalize方法可以清除对象的一些非内存资源。
+在每个对象中,finalize方法最多被调用一次。
+> finalize方法可以抛出任何异常,但是抛出的异常将被垃圾回收器忽略。
+
+在finalize方法调用时,该对象引用的其他对象可能也是垃圾对象,并且已经被回收。
+## 引用
+### Reference
+Reference是一个抽象类,是所有特定引用类的父类。
+#### get
+```java
+public Object get()
+```
+将会返回引用对象指向的被引用对象
+#### clear
+```java
+public void clear()
+```
+清空引用对象从而使其不指向任何对象
+#### enqueue
+```java
+public boolean enqueue()
+```
+如果存在引用对象,将引用对象加入到注册的引用队列中,如果加入队列成功,返回true;如果没有成功加入到队列,或者该引用对象已经在队列中,那么返回false
+#### isEnqueue
+```java
+public boolean isEnqueue()
+```
+如果该引用对象已经被加入到引用队列中,那么返回true,否则返回false
+### 引用的可达性
+#### 强可达(strongly reachable)
+至少通过一条强引用链可达
+#### 软可达(softly reachable)
+不是强可达,但是至少可以通过一条包含软引用的引用链可达
+#### 弱可达(weakly reachable)
+不是弱可达,但是至少通过一条包含弱引用的引用链可达
+#### 终结器可达(finalizer reachable)
+不是弱可达,但是该对象的finalize方法尚未执行
+#### 幽灵可达(phantom reachable)
+如果finalize方法已经执行,但是可通过至少一条包含幽灵引用的引用链可达
+### 引用类型
+#### 软引用(SoftReference)
+对于软可达的对象,垃圾回收程序会随意进行处置,如果可用内存很低,回收器会清空SoftReference对象中的引用,之后该被引用对象则能被回收
+> 在抛出OOM之前,所有的SoftReference引用将会被清空
+
+#### 弱引用(WeakReference)
+弱可达对象将会被垃圾回收器回收,如果垃圾回收器认为对象是弱可达的,所有指向其的WeakReference对象都会被清空
+
+#### 幽灵可达
+幽灵可达并不是真正的可达,虚引用并不会影响对象的生命周期,如果一个对象和虚引用关联,则该对象跟没有与该虚引用关联一样,在任何时候都有可能被垃圾回收。虚引用主要用于跟踪对象垃圾回收的活动。
+
+### Weak Hash Map
+WeakHashMap会使用WeakReference来存储key。
+如果垃圾回收器发现一个对象弱可达时,会将弱引用放入到引用队列中。WeakHashMap会定期检查引用队列中新到达的弱引用,并且新到的弱引用代表该key不再被使用,WeakHashMap会移除关联的entry。
+
+
+### 引用队列
+如果对象的可达性状态发生了改变,那么执行该对象的引用类型将会被放置到引用队列中。引用队列通常被垃圾回收器使用。
+也可以在自己的代码中对引用队列进行使用,通过引用队列,可以监听对象的可达性改变。
+> 例如当对象不再被强引用,变为弱可达时,引用将会被添加到引用队列中,再通过代码监听引用队列的变化,即可监听到对象可达性的变化
+
+> ReferenceQueue是线程安全的。
+
+#### ReferenceQueue.poll
+```java
+pulbic Reference poll()
+```
+该方法会删除并且返回队列中的下一个引用对象,若队列为空,则返回值为null
+
+#### ReferenceQueue.remove
+```java
+public Reference remove() throws InterruptedException
+```
+该方法同样会删除并返回队列中下一个引用对象,但是该方法在队列为空时会无限阻塞下去
+```java
+public Reference remove(long timeout) throws InterruptedException
+```
+
+引用对象在构造时,会和特定的引用队列相关联,当被引用对象的可达性状态发生变化时,被添加到引用队列中。在被添加到队列之前,引用对象都已经被清空。
+
+### 弱引用和软引用的使用
+弱引用和软引用都提供两种类型的构造函数,
+- 只接受被引用对象,并不将引用注册到引用队列
- 既接受被引用对象,还将引用注册到指定的引用队列,然后可以通过检查引用队列中的情况来监听被引用对象可达状态变更
\ No newline at end of file
diff --git a/mysql/mysql文档/mysql_文件.md b/mysql/mysql文档/mysql_文件.md
index 043490e..d7b5d3d 100644
--- a/mysql/mysql文档/mysql_文件.md
+++ b/mysql/mysql文档/mysql_文件.md
@@ -1,363 +1,363 @@
-- [文件](#文件)
- - [参数](#参数)
- - [参数查看](#参数查看)
- - [参数类型](#参数类型)
- - [动态参数修改](#动态参数修改)
- - [静态参数修改](#静态参数修改)
- - [日志文件](#日志文件)
- - [错误日志](#错误日志)
- - [慢查询日志](#慢查询日志)
- - [log\_queries\_not\_using\_indexes](#log_queries_not_using_indexes)
- - [查询日志](#查询日志)
- - [二进制日志](#二进制日志)
- - [max\_binlog\_size](#max_binlog_size)
- - [binlog\_cache\_size](#binlog_cache_size)
- - [binlog\_cache\_use](#binlog_cache_use)
- - [binlog\_cache\_disk\_use](#binlog_cache_disk_use)
- - [sync\_binlog](#sync_binlog)
- - [innodb\_flush\_log\_at\_trx\_commit](#innodb_flush_log_at_trx_commit)
- - [binlog\_format](#binlog_format)
- - [使用statement可能会存在的问题](#使用statement可能会存在的问题)
- - [mysqlbinlog](#mysqlbinlog)
- - [pid文件](#pid文件)
- - [表结构定义文件](#表结构定义文件)
- - [表空间文件](#表空间文件)
- - [innodb\_data\_file\_path](#innodb_data_file_path)
- - [innodb\_file\_per\_table](#innodb_file_per_table)
- - [redo log文件](#redo-log文件)
- - [循环写入](#循环写入)
- - [redo log capacity](#redo-log-capacity)
- - [redo log和binlog的区别](#redo-log和binlog的区别)
- - [记录内容](#记录内容)
- - [写入时机](#写入时机)
- - [redo log写入时机](#redo-log写入时机)
-
-
-# 文件
-## 参数
-### 参数查看
-mysql参数为键值对,可以通过`show variables`命令查看所有的数据库参数,并可以通过`like`来过滤参数名称。
-
-除了`show variables`命令之外,还能够在`performance_schema`下的`global_variables`视图来查找数据库参数,示例如下:
-```sql
--- 查看innodb_buffer_pool_size参数
-show variables like 'innodb_buffer_pool_size'
-```
-上述`show variables`命令的执行结果为
-| Variable\_name | Value |
-| :--- | :--- |
-| innodb\_buffer\_pool\_size | 4294967296 |
-
-```sql
-select * from performance_schema.global_variables where variable_name like 'innodb_buffer_pool%';
-```
-上述sql的执行结果如下:
-| VARIABLE\_NAME | VARIABLE\_VALUE |
-| :--- | :--- |
-| innodb\_buffer\_pool\_chunk\_size | 134217728 |
-| innodb\_buffer\_pool\_dump\_at\_shutdown | ON |
-| innodb\_buffer\_pool\_dump\_now | OFF |
-| innodb\_buffer\_pool\_dump\_pct | 25 |
-| innodb\_buffer\_pool\_filename | ib\_buffer\_pool |
-| innodb\_buffer\_pool\_in\_core\_file | ON |
-| innodb\_buffer\_pool\_instances | 4 |
-| innodb\_buffer\_pool\_load\_abort | OFF |
-| innodb\_buffer\_pool\_load\_at\_startup | ON |
-| innodb\_buffer\_pool\_load\_now | OFF |
-| innodb\_buffer\_pool\_size | 4294967296 |
-
-### 参数类型
-mysql中的参数可以分为`动态`和`静态`两种类型,
-- 动态:动态参数代表可以在mysql运行过程中进行修改
-- 静态:代表在整个实例的声明周期内都不得进行修改
-
-#### 动态参数修改
-对于动态参数,可以在运行时通过`SET`命令来进行修改,`SET`命令语法如下:
-```sql
-set
- | [global | session] system_var_name=expr
- | [@@global. | @@session. | @@] system_var_name = expr
-```
-在上述语法中,`global`和`session`关键字代表该动态参数的修改是针对`当前会话`还是针对`整个实例的生命周期`。
-
-- 有些动态参数只能在会话范围内进行修改,例如`autocommit`
-- 有些参数修改后,实例整个生命周期内都会生效,例如`binglog_cache_size`
-- 有些参数既可以在会话范围内进行修改,又可以在实例声明周期范围内进行修改,例如`read_buffer_size`
-
-使用示例如下:
-
-查询read_buffer_size的global和session值
-```sql
--- 查询read_buffer_size的global和session值
-select @@session.read_buffer_size,@@global.read_buffer_size;
-```
-返回结果为
-
-| @@session.read\_buffer\_size | @@global.read\_buffer\_size |
-| :--- | :--- |
-| 131072 | 131072 |
-
-设置@@session.read_buffer_size为524288
-```sql
-set @@session.read_buffer_size = 1024 * 512;
-```
-设置后,再次查询read_buffer_size的global和session值,结果为
-| @@session.read\_buffer\_size | @@global.read\_buffer\_size |
-| :--- | :--- |
-| 524288 | 131072 |
-
-在调用set命令修改session read_buffer_size参数后,session参数发生变化,但是global参数仍然为旧的值。
-
-> `set session xxx`命令并不会对global参数的值造成影响,新会话的参数值仍然为修改前的值。
-
-之后,再对global read_buffer_size值进行修改,执行如下命令
-```sql
-set @@global.read_buffer_size = 496 * 1024;
-```
-执行该命令后,sesion和global参数值为
-| @@session.read\_buffer\_size | @@global.read\_buffer\_size |
-| :--- | :--- |
-| 524288 | 507904 |
-
-> `set global xxx`命令只会修改global参数值,对session参数值不会造成影响,新的session其`session参数值, global参数值`和修改后的global参数值保持一致
-
-> 即使针对参数的global值进行了修改,其影响范围是当前实例的整个生命周期,`但是,其并不会对参数文件中的参数值进行修改,故而下次启动mysql实例时,仍然会从参数文件中取值,新实例的值仍然是修改前的值`。
->
-> 如果想要修改下次启动实例的参数值,需要修改参数文件中该参数的值。(参数文件路径通常为`/etc/my.cnf`)
-
-#### 静态参数修改
-在运行时,如果尝试对静态参数进行修改,那么会发生错误,示例如下:
-```sql
-> set global datadir='/db/mysql'
-[2025-01-30 15:05:17] [HY000][1238] Variable 'datadir' is a read only variable
-```
-## 日志文件
-mysql中常见日志文件如下
-- 错误日志(error log)
-- 二进制日志(binlog)
-- 慢查询日志(slow query log)
-- 查询日志(log)
-
-### 错误日志
-错误日志针对mysql的启动、运行、关闭过程进行了记录,用户可以通过`show variables like 'log_error';`来获取错误日志的路径:
-```sql
-show variables like 'log_error';
-```
-其输出值如下:
-| Variable\_name | Value |
-| :--- | :--- |
-| log\_error | /var/log/mysql/mysqld.log |
-
-当mysql数据库无法正常启动时,应当首先查看错误日志。
-
-### 慢查询日志
-慢查询日志存在一个阈值,通过`long_query_time`参数来进行控制,该参数默认值为`10`,代表慢查询的限制为10s。
-
-通过`slow_query_log`参数,可以控制是否日志输出慢查询日志,默认为`OFF`,如果需要开启慢查询日志,需要将该值设置为`ON`。
-
-关于慢查询日志的输出地点,可以通过`log_output`参数来进行控制。该参数默认为`FILE`,支持`FILE, TABLE, NONE`。`log_output`支持制定多个值,多个值之间可以通过`,`分隔,当值中包含`NONE`时,以`NONE`优先。
-
-#### log_queries_not_using_indexes
-当`log_queryies_not_using_indexes`开启时,如果运行的sql语句没有使用索引,那么这条sql同样会被输出到慢查询日志。该参数默认关闭。
-
-`log_throttle_queries_not_using_idnexes`用于记录`每分钟允许记录到慢查询日志并且没有使用索引`的sql语句次数,该参数值默认为0,代表每分钟输出到慢查询日志中的数量没有限制。
-
-该参数主要用于防止大量没有使用索引的sql添加到慢查询日志中,造成慢查询日志大小快速增加。
-
-当慢查询日志中的内容越来越多时,可以通过mysql提供的工具`mysqldumpslow`命令,示例如下:
-```sql
-mysqldumpslow -s at -n 10 ${slow_query_log_path}
-```
-
-### 查询日志
-查询日志记录了对mysql数据库所有的请求信息,无论请求是否正确执行。
-
-查询日志通过`general_log`参数来进行控制,默认该参数值为`OFF`.
-
-### 二进制日志
-二进制日志(binary log)记录了针对mysql数据库执行的所有更改操作(不包含select以及show这类读操作)。
-
-对于update操作等,即使没有对数据库进行修改(affected rows为0),也会被写入到binary log中。
-
-二进制日志的主要用途如下:
-- 恢复(recovery):某些数据恢复需要二进制日志,例如在数据库全备份文件恢复后,用户可以通过二进制日志进行point-in-time的恢复
-- 复制(replication):通过将一台主机(master)的binlog同步到另一台主机(slave),并且在另一台主机上执行该binlog,可以令slave与master进行实时同步
-- 审计(audit):用户可以对binlog中的信息进行审计,判断是否存在对数据库进行的注入攻击
-
-通过参数`log_bin`可以控制是否启用二进制日志。
-
-binlog通常存放在`datadir`参数所指定的目录路径下。在该路径下,还存在`binlog.index`文件,该文件为binlog的索引文件,文件内容包含所有binlog的文件名称。
-
-#### max_binlog_size
-`max_binlog_size`参数控制单个binlog文件的最大大小,如果单个文件超过该值,会产生新的二进制文件,新binlog的后缀会+1,并且新文件的文件名会被记录到`.index`文件中。
-
-`max_binlog_size`的默认值大小为`1G`。
-
-#### binlog_cache_size
-当使用innodb存储引擎时,所有未提交事务的binlog会被记录到缓存中,等到事务提交后,会将缓存中的binlog写入到文件中。缓存大小通过`binlog_cache_size`决定,该值默认为`32768`,即`32KB`。
-
-`binlog_cache_size`是基于会话的,`在每个线程开启一个事务时,mysql会自动分配一个大小为binlog_cache_size大小的缓存,因而该值不能设置过大`。
-
-当一个事务的记录大于设定的`binlog_cache_size`时,mysql会将缓冲中的日志写入到一个临时文件中,故而,该值无法设置过小。
-
-通过`show global status like 'binlog_cache%`命令可以查看`binlog_cache_use`和`binlog_cache_disk_use`的状态,可以通过上述两个状态判断binlog cache大小是否合适。
-
-##### binlog_cache_use
-`binlog_cache_use`记录了使用缓冲写binlog的次数
-
-##### binlog_cache_disk_use
-`binlog_cache_disk_use`记录了使用临时文件写二进制日志的次数
-
-#### sync_binlog
-`sync_binlog`参数控制mysql server同步binlog到磁盘的频率,该值默认为`1`
-
-- 0: 如果参数值为0,代表mysql server禁用binary log同步到磁盘。mysql会依赖操作系统将binary log刷新到磁盘中,该设置性能最佳,但是遇到操作系统崩溃时,可能会出现mysql事务提交但是还没有同步到binary log的场景
-- 1: 如果参数值设置为1,代表在事务提交之前将binary log同步到磁盘中,该设置最安全,但是会增加disk write次数,对性能会带来负面影响。在操作系统崩溃的场景下,binlog中缺失的事务还只处于prepared状态,从而确保binlog中没有事务丢失
-- N:当参数值被设置为非`0,1`的值时,每当n个binlog commit groups被收集到后,同步binlog到磁盘。在这种情况下,可能会发生事务提交但是还没有被刷新到binlog中,`当n值越大时,性能会越好,但是也会增加数据丢失的风险`
-
-为了在使用innodb事务和replciation时获得最好的一致性和持久性,请使用如下设置:
-```cnf
-sync_binlog=1
-innodb_flush_log_at_trx_commit=1
-```
-
-#### innodb_flush_log_at_trx_commit
-innodb_flush_log_at_trx_commit用于控制redo log的刷新。
-
-该参数用于平衡`commit操作ACID的合规性`以及`更高性能`。通过修改该参数值,可以实现更佳的性能,但是在崩溃时可能会丢失事务:
-- 1: 1为该参数默认值,代表完全的ACID合规性,日志在每次事务提交后被写入并刷新到磁盘中
-- 0: 日志每秒被写入和刷新到磁盘中,如果事务没有被刷新,那么日志将会在崩溃中被丢失
-- 2: 每当事务提交后,日志将会被写入,并且每秒钟都会被刷新到磁盘中。如果事务没有被刷新,崩溃同样会造成日志的丢失
-
-如果当前数据库为slave角色,那么其不会把`从master同步的binlog`写入到自己的binlog中,如果要实现`master=>slave=>slave`的同步架构,必须设置`log_slave_updates`参数。
-
-#### binlog_format
-binlog_format用于控制二进制文件的格式,可能有如下取值:
-- statement: 二进制文件记录的是日志的逻辑sql语句
-- row:记录表的行更改情况,默认值为`row`
-- mixed: 如果参数被配置为mixed,mysql默认会采用`statement`格式进行记录,但是在特定场景能够下会使用`row`格式:
- - 使用了uuid, user, current_user,found_rows, row_count等不确定函数
- - 使用了insert delay语句
- - 使用了用户自定义函数
- - 使用了临时表
-
-##### 使用statement可能会存在的问题
-在使用statement格式时,可能会存在如下问题
-- master运行rand,uuid等不确定函数时,或使用触发器操作时,会导致主从服务器上的数据不一致
-- innodb的默认事务隔离级别为`repetable_read`,如果使用`read_commited`级别时,statement格式可能会导致丢失更新的情况,从而令master和slave的数据不一致
-
-binlog为动态参数,可以在数据库运行时进行修改,并且可以针对session和global进行修改。
-
-#### mysqlbinlog
-在查看二进制日志时,可以使用`mysqlbinlog`命令,示例如下
-```bash
-mysqlbinlog --start-position=203 ${binlog_path}
-```
-
-## pid文件
-mysql实例启动时,会将进程id写入到一个文件中,该文件被称为pid文件。
-
-pid文件路径通过`pid_file`参数来进行控制,fedora中默认路径为`/run/mysqld/mysqld.pid`。
-
-## 表结构定义文件
-mysql中数据的存储是根据表进行的,每个表都有与之对应的文件。无论表采用何种存储引擎,都会存在一个以`frm`为后缀的文件,该文件中保存了该表的表结构定义。
-
-> mysql 8中,schema对应目录下不再包含frm文件。
-
-## 表空间文件
-innodb采用将存储的数据按照表空间(tablespace)进行存放的设计。在默认配置下,将会有一个初始大小为10MB,名称为ibdata1的文件,该文件为默认的表空间文件。
-
-### innodb_data_file_path
-可以通过`innodb_data_file_path`参数对默认表空间文件进行设置,示例如下:
-```sql
-innodb_data_file_path=datafile_spec1[;datafile_spec2]...
-```
-用户可以通过多个文件组成一个表空间,示例如下:
-```sql
-innodb_data_file_path=/db/ibdata1:2000M;/dr2/db/ibdata2:2000M;autoextend
-```
-在上述配置中,表空间由`/db/ibdata1`和`/dr2/db/ibdata2`两个文件组成,如果两个文件位于不同的磁盘上,那么磁盘的负载将会被平均,数据库的整体性能将会被提高。
-
-同时,在上述示例中,为两个文件都指定了后续属性,含义如下:
-- ibdata1:文件大小为2000M
-- ibdata2:文件大小为2000M,并且当文件大小被用完后,文件会自动增长
-
-当`innodb_data_file_path`被设置后,所有基于innodb存储引擎的表,其数据都会记录到该共享表空间中。
-
-### innodb_file_per_table
-如果`innodb_file_per_table`被启用后(默认启用),则每个基于innodb存储引擎的表都可以有一个独立的表空间,独立表空间的命名规则为`表名+.ibd`。
-
-通过innodb_file_per_table,用户不需要将所有的数据都放置在默认的表空间中。
-
-> `innodb_file_per_table`所产生的独立表空间文件,其仅存储该表的数据、索引和插入缓冲BITMAP信息,其余信息仍然存放在默认的表空间中。
-
-## redo log文件
-redo log是一个基于磁盘的数据结构,用于在crash recovery过程中纠正由`未完成事务写入的错误数据`。
-
-> 在一般操作中,redo log对那些`会造成表数据发生改变的请求`进行encode操作,请求通常由sql statement或地级别api发起。
-
-redo log通常代表磁盘上的redo log file。写入重做日志文件的数据通常基于受影响的记录进行编码。在数据被写入到redo log file中时,LSN值也会不断增加。
-
-### 循环写入
-innodb会按顺序写入redo log文件,例如redo log file group中存在两个文件,innodb会先写文件1,文件1写满后会切换文件2,在文件2写满后,重新切换到文件1。
-
-### redo log capacity
-从mysql 8.0.30开始,`innodb_redo_log_capacity`参数用于控制redo log file占用磁盘空间的大小。该参数可以在实例启动时进行设置,也可以通过`set global`来进行设置。
-
-`innodb_redo_log_capacity`默认值为`104857600`,即`100M`。
-
-redo log文件默认位于`datadir`路径下的`#innodb_redo`目录下。innodb会尝试维护32个redo log file,每个redo log file文件大小都相同,为`1/32 * innodb_redo_log_capacity`。
-
-redo log file将会使用`#ib_redoN`的命名方式,`N`是redo log file number。
-
-innodb redo log file分为如下两种:
-- ordinary:正在被使用的redo log file
-- spare:等待被使用的redo log file
-
-> 相比于ordinary redo log file,spare redo log file的名称中还包含了`_tmp`后缀
-
-每个oridnary redo log file都关联了一个制定的LSN范围,可以通过查询`performance_schema.innodb_redo_log_files`表里获取LSN范围。
-
-示例如下:
-```sql
-select file_name, start_lsn, end_lsn from performance_schema.innodb_redo_log_files;
-```
-查询结果示例如下:
-| file\_name | start\_lsn | end\_lsn |
-| :--- | :--- | :--- |
-| ./#innodb\_redo/#ib\_redo6 | 19656704 | 22931456 |
-
-当执行checkpoint时,innodb会将checkpoint LSN存储在文件的header中,在recovery过程中,所有的redo log文件都将被检查,并且基于最大的LSN来执行恢复操作。
-
-常用的redo log状态如下
-```bash
- # resize operation status
- Innodb_redo_log_resize_status
- # 当前redo log capacity
- Innodb_redo_log_capacity_resized
- Innodb_redo_log_checkpoint_lsn
- Innodb_redo_log_current_lsn
- Innodb_redo_log_flushed_to_disk_lsn
- Innodb_redo_log_logical_size
- Innodb_redo_log_physical_size
- Innodb_redo_log_read_only
- Innodb_redo_log_uuid
-```
-> 重做日志大小设置时,如果设置大小过大,那么在执行恢复操作时,可能需要花费很长时间;如果重做日志文件大小设置过小,可能会导致事务的日志需要多次切换重做日志文件。
->
-> 此外,重做日志太小会频繁发生async checkpoint,导致性能抖动。重做日志存在一个capacity,代表了最后的checkpoint不能够超过这个阈值,如果超过必须将缓冲区中的部分脏页刷新到磁盘中,此时可能会造成用户线程的阻塞。
-
-### redo log和binlog的区别
-#### 记录内容
-binlog记录的是一个事务的具体操作内容,该日志为逻辑日志。
-
-而innodb redo log记录的是关于某个页的修改,为物理日志。
-
-#### 写入时机
-binlog仅当事务提交前才进行提交,即只会写磁盘一次。
-
-redo log则是在事务运行过程中,不断有重做日志被写入到redo log file中。
-
-### redo log写入时机
-- master thread会每秒将redo log从buffer中刷新到redo log ile中,不露内事务是否已经提交
+- [文件](#文件)
+ - [参数](#参数)
+ - [参数查看](#参数查看)
+ - [参数类型](#参数类型)
+ - [动态参数修改](#动态参数修改)
+ - [静态参数修改](#静态参数修改)
+ - [日志文件](#日志文件)
+ - [错误日志](#错误日志)
+ - [慢查询日志](#慢查询日志)
+ - [log\_queries\_not\_using\_indexes](#log_queries_not_using_indexes)
+ - [查询日志](#查询日志)
+ - [二进制日志](#二进制日志)
+ - [max\_binlog\_size](#max_binlog_size)
+ - [binlog\_cache\_size](#binlog_cache_size)
+ - [binlog\_cache\_use](#binlog_cache_use)
+ - [binlog\_cache\_disk\_use](#binlog_cache_disk_use)
+ - [sync\_binlog](#sync_binlog)
+ - [innodb\_flush\_log\_at\_trx\_commit](#innodb_flush_log_at_trx_commit)
+ - [binlog\_format](#binlog_format)
+ - [使用statement可能会存在的问题](#使用statement可能会存在的问题)
+ - [mysqlbinlog](#mysqlbinlog)
+ - [pid文件](#pid文件)
+ - [表结构定义文件](#表结构定义文件)
+ - [表空间文件](#表空间文件)
+ - [innodb\_data\_file\_path](#innodb_data_file_path)
+ - [innodb\_file\_per\_table](#innodb_file_per_table)
+ - [redo log文件](#redo-log文件)
+ - [循环写入](#循环写入)
+ - [redo log capacity](#redo-log-capacity)
+ - [redo log和binlog的区别](#redo-log和binlog的区别)
+ - [记录内容](#记录内容)
+ - [写入时机](#写入时机)
+ - [redo log写入时机](#redo-log写入时机)
+
+
+# 文件
+## 参数
+### 参数查看
+mysql参数为键值对,可以通过`show variables`命令查看所有的数据库参数,并可以通过`like`来过滤参数名称。
+
+除了`show variables`命令之外,还能够在`performance_schema`下的`global_variables`视图来查找数据库参数,示例如下:
+```sql
+-- 查看innodb_buffer_pool_size参数
+show variables like 'innodb_buffer_pool_size'
+```
+上述`show variables`命令的执行结果为
+| Variable\_name | Value |
+| :--- | :--- |
+| innodb\_buffer\_pool\_size | 4294967296 |
+
+```sql
+select * from performance_schema.global_variables where variable_name like 'innodb_buffer_pool%';
+```
+上述sql的执行结果如下:
+| VARIABLE\_NAME | VARIABLE\_VALUE |
+| :--- | :--- |
+| innodb\_buffer\_pool\_chunk\_size | 134217728 |
+| innodb\_buffer\_pool\_dump\_at\_shutdown | ON |
+| innodb\_buffer\_pool\_dump\_now | OFF |
+| innodb\_buffer\_pool\_dump\_pct | 25 |
+| innodb\_buffer\_pool\_filename | ib\_buffer\_pool |
+| innodb\_buffer\_pool\_in\_core\_file | ON |
+| innodb\_buffer\_pool\_instances | 4 |
+| innodb\_buffer\_pool\_load\_abort | OFF |
+| innodb\_buffer\_pool\_load\_at\_startup | ON |
+| innodb\_buffer\_pool\_load\_now | OFF |
+| innodb\_buffer\_pool\_size | 4294967296 |
+
+### 参数类型
+mysql中的参数可以分为`动态`和`静态`两种类型,
+- 动态:动态参数代表可以在mysql运行过程中进行修改
+- 静态:代表在整个实例的声明周期内都不得进行修改
+
+#### 动态参数修改
+对于动态参数,可以在运行时通过`SET`命令来进行修改,`SET`命令语法如下:
+```sql
+set
+ | [global | session] system_var_name=expr
+ | [@@global. | @@session. | @@] system_var_name = expr
+```
+在上述语法中,`global`和`session`关键字代表该动态参数的修改是针对`当前会话`还是针对`整个实例的生命周期`。
+
+- 有些动态参数只能在会话范围内进行修改,例如`autocommit`
+- 有些参数修改后,实例整个生命周期内都会生效,例如`binglog_cache_size`
+- 有些参数既可以在会话范围内进行修改,又可以在实例声明周期范围内进行修改,例如`read_buffer_size`
+
+使用示例如下:
+
+查询read_buffer_size的global和session值
+```sql
+-- 查询read_buffer_size的global和session值
+select @@session.read_buffer_size,@@global.read_buffer_size;
+```
+返回结果为
+
+| @@session.read\_buffer\_size | @@global.read\_buffer\_size |
+| :--- | :--- |
+| 131072 | 131072 |
+
+设置@@session.read_buffer_size为524288
+```sql
+set @@session.read_buffer_size = 1024 * 512;
+```
+设置后,再次查询read_buffer_size的global和session值,结果为
+| @@session.read\_buffer\_size | @@global.read\_buffer\_size |
+| :--- | :--- |
+| 524288 | 131072 |
+
+在调用set命令修改session read_buffer_size参数后,session参数发生变化,但是global参数仍然为旧的值。
+
+> `set session xxx`命令并不会对global参数的值造成影响,新会话的参数值仍然为修改前的值。
+
+之后,再对global read_buffer_size值进行修改,执行如下命令
+```sql
+set @@global.read_buffer_size = 496 * 1024;
+```
+执行该命令后,sesion和global参数值为
+| @@session.read\_buffer\_size | @@global.read\_buffer\_size |
+| :--- | :--- |
+| 524288 | 507904 |
+
+> `set global xxx`命令只会修改global参数值,对session参数值不会造成影响,新的session其`session参数值, global参数值`和修改后的global参数值保持一致
+
+> 即使针对参数的global值进行了修改,其影响范围是当前实例的整个生命周期,`但是,其并不会对参数文件中的参数值进行修改,故而下次启动mysql实例时,仍然会从参数文件中取值,新实例的值仍然是修改前的值`。
+>
+> 如果想要修改下次启动实例的参数值,需要修改参数文件中该参数的值。(参数文件路径通常为`/etc/my.cnf`)
+
+#### 静态参数修改
+在运行时,如果尝试对静态参数进行修改,那么会发生错误,示例如下:
+```sql
+> set global datadir='/db/mysql'
+[2025-01-30 15:05:17] [HY000][1238] Variable 'datadir' is a read only variable
+```
+## 日志文件
+mysql中常见日志文件如下
+- 错误日志(error log)
+- 二进制日志(binlog)
+- 慢查询日志(slow query log)
+- 查询日志(log)
+
+### 错误日志
+错误日志针对mysql的启动、运行、关闭过程进行了记录,用户可以通过`show variables like 'log_error';`来获取错误日志的路径:
+```sql
+show variables like 'log_error';
+```
+其输出值如下:
+| Variable\_name | Value |
+| :--- | :--- |
+| log\_error | /var/log/mysql/mysqld.log |
+
+当mysql数据库无法正常启动时,应当首先查看错误日志。
+
+### 慢查询日志
+慢查询日志存在一个阈值,通过`long_query_time`参数来进行控制,该参数默认值为`10`,代表慢查询的限制为10s。
+
+通过`slow_query_log`参数,可以控制是否日志输出慢查询日志,默认为`OFF`,如果需要开启慢查询日志,需要将该值设置为`ON`。
+
+关于慢查询日志的输出地点,可以通过`log_output`参数来进行控制。该参数默认为`FILE`,支持`FILE, TABLE, NONE`。`log_output`支持制定多个值,多个值之间可以通过`,`分隔,当值中包含`NONE`时,以`NONE`优先。
+
+#### log_queries_not_using_indexes
+当`log_queryies_not_using_indexes`开启时,如果运行的sql语句没有使用索引,那么这条sql同样会被输出到慢查询日志。该参数默认关闭。
+
+`log_throttle_queries_not_using_idnexes`用于记录`每分钟允许记录到慢查询日志并且没有使用索引`的sql语句次数,该参数值默认为0,代表每分钟输出到慢查询日志中的数量没有限制。
+
+该参数主要用于防止大量没有使用索引的sql添加到慢查询日志中,造成慢查询日志大小快速增加。
+
+当慢查询日志中的内容越来越多时,可以通过mysql提供的工具`mysqldumpslow`命令,示例如下:
+```sql
+mysqldumpslow -s at -n 10 ${slow_query_log_path}
+```
+
+### 查询日志
+查询日志记录了对mysql数据库所有的请求信息,无论请求是否正确执行。
+
+查询日志通过`general_log`参数来进行控制,默认该参数值为`OFF`.
+
+### 二进制日志
+二进制日志(binary log)记录了针对mysql数据库执行的所有更改操作(不包含select以及show这类读操作)。
+
+对于update操作等,即使没有对数据库进行修改(affected rows为0),也会被写入到binary log中。
+
+二进制日志的主要用途如下:
+- 恢复(recovery):某些数据恢复需要二进制日志,例如在数据库全备份文件恢复后,用户可以通过二进制日志进行point-in-time的恢复
+- 复制(replication):通过将一台主机(master)的binlog同步到另一台主机(slave),并且在另一台主机上执行该binlog,可以令slave与master进行实时同步
+- 审计(audit):用户可以对binlog中的信息进行审计,判断是否存在对数据库进行的注入攻击
+
+通过参数`log_bin`可以控制是否启用二进制日志。
+
+binlog通常存放在`datadir`参数所指定的目录路径下。在该路径下,还存在`binlog.index`文件,该文件为binlog的索引文件,文件内容包含所有binlog的文件名称。
+
+#### max_binlog_size
+`max_binlog_size`参数控制单个binlog文件的最大大小,如果单个文件超过该值,会产生新的二进制文件,新binlog的后缀会+1,并且新文件的文件名会被记录到`.index`文件中。
+
+`max_binlog_size`的默认值大小为`1G`。
+
+#### binlog_cache_size
+当使用innodb存储引擎时,所有未提交事务的binlog会被记录到缓存中,等到事务提交后,会将缓存中的binlog写入到文件中。缓存大小通过`binlog_cache_size`决定,该值默认为`32768`,即`32KB`。
+
+`binlog_cache_size`是基于会话的,`在每个线程开启一个事务时,mysql会自动分配一个大小为binlog_cache_size大小的缓存,因而该值不能设置过大`。
+
+当一个事务的记录大于设定的`binlog_cache_size`时,mysql会将缓冲中的日志写入到一个临时文件中,故而,该值无法设置过小。
+
+通过`show global status like 'binlog_cache%`命令可以查看`binlog_cache_use`和`binlog_cache_disk_use`的状态,可以通过上述两个状态判断binlog cache大小是否合适。
+
+##### binlog_cache_use
+`binlog_cache_use`记录了使用缓冲写binlog的次数
+
+##### binlog_cache_disk_use
+`binlog_cache_disk_use`记录了使用临时文件写二进制日志的次数
+
+#### sync_binlog
+`sync_binlog`参数控制mysql server同步binlog到磁盘的频率,该值默认为`1`
+
+- 0: 如果参数值为0,代表mysql server禁用binary log同步到磁盘。mysql会依赖操作系统将binary log刷新到磁盘中,该设置性能最佳,但是遇到操作系统崩溃时,可能会出现mysql事务提交但是还没有同步到binary log的场景
+- 1: 如果参数值设置为1,代表在事务提交之前将binary log同步到磁盘中,该设置最安全,但是会增加disk write次数,对性能会带来负面影响。在操作系统崩溃的场景下,binlog中缺失的事务还只处于prepared状态,从而确保binlog中没有事务丢失
+- N:当参数值被设置为非`0,1`的值时,每当n个binlog commit groups被收集到后,同步binlog到磁盘。在这种情况下,可能会发生事务提交但是还没有被刷新到binlog中,`当n值越大时,性能会越好,但是也会增加数据丢失的风险`
+
+为了在使用innodb事务和replciation时获得最好的一致性和持久性,请使用如下设置:
+```cnf
+sync_binlog=1
+innodb_flush_log_at_trx_commit=1
+```
+
+#### innodb_flush_log_at_trx_commit
+innodb_flush_log_at_trx_commit用于控制redo log的刷新。
+
+该参数用于平衡`commit操作ACID的合规性`以及`更高性能`。通过修改该参数值,可以实现更佳的性能,但是在崩溃时可能会丢失事务:
+- 1: 1为该参数默认值,代表完全的ACID合规性,日志在每次事务提交后被写入并刷新到磁盘中
+- 0: 日志每秒被写入和刷新到磁盘中,如果事务没有被刷新,那么日志将会在崩溃中被丢失
+- 2: 每当事务提交后,日志将会被写入,并且每秒钟都会被刷新到磁盘中。如果事务没有被刷新,崩溃同样会造成日志的丢失
+
+如果当前数据库为slave角色,那么其不会把`从master同步的binlog`写入到自己的binlog中,如果要实现`master=>slave=>slave`的同步架构,必须设置`log_slave_updates`参数。
+
+#### binlog_format
+binlog_format用于控制二进制文件的格式,可能有如下取值:
+- statement: 二进制文件记录的是日志的逻辑sql语句
+- row:记录表的行更改情况,默认值为`row`
+- mixed: 如果参数被配置为mixed,mysql默认会采用`statement`格式进行记录,但是在特定场景能够下会使用`row`格式:
+ - 使用了uuid, user, current_user,found_rows, row_count等不确定函数
+ - 使用了insert delay语句
+ - 使用了用户自定义函数
+ - 使用了临时表
+
+##### 使用statement可能会存在的问题
+在使用statement格式时,可能会存在如下问题
+- master运行rand,uuid等不确定函数时,或使用触发器操作时,会导致主从服务器上的数据不一致
+- innodb的默认事务隔离级别为`repetable_read`,如果使用`read_commited`级别时,statement格式可能会导致丢失更新的情况,从而令master和slave的数据不一致
+
+binlog为动态参数,可以在数据库运行时进行修改,并且可以针对session和global进行修改。
+
+#### mysqlbinlog
+在查看二进制日志时,可以使用`mysqlbinlog`命令,示例如下
+```bash
+mysqlbinlog --start-position=203 ${binlog_path}
+```
+
+## pid文件
+mysql实例启动时,会将进程id写入到一个文件中,该文件被称为pid文件。
+
+pid文件路径通过`pid_file`参数来进行控制,fedora中默认路径为`/run/mysqld/mysqld.pid`。
+
+## 表结构定义文件
+mysql中数据的存储是根据表进行的,每个表都有与之对应的文件。无论表采用何种存储引擎,都会存在一个以`frm`为后缀的文件,该文件中保存了该表的表结构定义。
+
+> mysql 8中,schema对应目录下不再包含frm文件。
+
+## 表空间文件
+innodb采用将存储的数据按照表空间(tablespace)进行存放的设计。在默认配置下,将会有一个初始大小为10MB,名称为ibdata1的文件,该文件为默认的表空间文件。
+
+### innodb_data_file_path
+可以通过`innodb_data_file_path`参数对默认表空间文件进行设置,示例如下:
+```sql
+innodb_data_file_path=datafile_spec1[;datafile_spec2]...
+```
+用户可以通过多个文件组成一个表空间,示例如下:
+```sql
+innodb_data_file_path=/db/ibdata1:2000M;/dr2/db/ibdata2:2000M;autoextend
+```
+在上述配置中,表空间由`/db/ibdata1`和`/dr2/db/ibdata2`两个文件组成,如果两个文件位于不同的磁盘上,那么磁盘的负载将会被平均,数据库的整体性能将会被提高。
+
+同时,在上述示例中,为两个文件都指定了后续属性,含义如下:
+- ibdata1:文件大小为2000M
+- ibdata2:文件大小为2000M,并且当文件大小被用完后,文件会自动增长
+
+当`innodb_data_file_path`被设置后,所有基于innodb存储引擎的表,其数据都会记录到该共享表空间中。
+
+### innodb_file_per_table
+如果`innodb_file_per_table`被启用后(默认启用),则每个基于innodb存储引擎的表都可以有一个独立的表空间,独立表空间的命名规则为`表名+.ibd`。
+
+通过innodb_file_per_table,用户不需要将所有的数据都放置在默认的表空间中。
+
+> `innodb_file_per_table`所产生的独立表空间文件,其仅存储该表的数据、索引和插入缓冲BITMAP信息,其余信息仍然存放在默认的表空间中。
+
+## redo log文件
+redo log是一个基于磁盘的数据结构,用于在crash recovery过程中纠正由`未完成事务写入的错误数据`。
+
+> 在一般操作中,redo log对那些`会造成表数据发生改变的请求`进行encode操作,请求通常由sql statement或地级别api发起。
+
+redo log通常代表磁盘上的redo log file。写入重做日志文件的数据通常基于受影响的记录进行编码。在数据被写入到redo log file中时,LSN值也会不断增加。
+
+### 循环写入
+innodb会按顺序写入redo log文件,例如redo log file group中存在两个文件,innodb会先写文件1,文件1写满后会切换文件2,在文件2写满后,重新切换到文件1。
+
+### redo log capacity
+从mysql 8.0.30开始,`innodb_redo_log_capacity`参数用于控制redo log file占用磁盘空间的大小。该参数可以在实例启动时进行设置,也可以通过`set global`来进行设置。
+
+`innodb_redo_log_capacity`默认值为`104857600`,即`100M`。
+
+redo log文件默认位于`datadir`路径下的`#innodb_redo`目录下。innodb会尝试维护32个redo log file,每个redo log file文件大小都相同,为`1/32 * innodb_redo_log_capacity`。
+
+redo log file将会使用`#ib_redoN`的命名方式,`N`是redo log file number。
+
+innodb redo log file分为如下两种:
+- ordinary:正在被使用的redo log file
+- spare:等待被使用的redo log file
+
+> 相比于ordinary redo log file,spare redo log file的名称中还包含了`_tmp`后缀
+
+每个oridnary redo log file都关联了一个制定的LSN范围,可以通过查询`performance_schema.innodb_redo_log_files`表里获取LSN范围。
+
+示例如下:
+```sql
+select file_name, start_lsn, end_lsn from performance_schema.innodb_redo_log_files;
+```
+查询结果示例如下:
+| file\_name | start\_lsn | end\_lsn |
+| :--- | :--- | :--- |
+| ./#innodb\_redo/#ib\_redo6 | 19656704 | 22931456 |
+
+当执行checkpoint时,innodb会将checkpoint LSN存储在文件的header中,在recovery过程中,所有的redo log文件都将被检查,并且基于最大的LSN来执行恢复操作。
+
+常用的redo log状态如下
+```bash
+ # resize operation status
+ Innodb_redo_log_resize_status
+ # 当前redo log capacity
+ Innodb_redo_log_capacity_resized
+ Innodb_redo_log_checkpoint_lsn
+ Innodb_redo_log_current_lsn
+ Innodb_redo_log_flushed_to_disk_lsn
+ Innodb_redo_log_logical_size
+ Innodb_redo_log_physical_size
+ Innodb_redo_log_read_only
+ Innodb_redo_log_uuid
+```
+> 重做日志大小设置时,如果设置大小过大,那么在执行恢复操作时,可能需要花费很长时间;如果重做日志文件大小设置过小,可能会导致事务的日志需要多次切换重做日志文件。
+>
+> 此外,重做日志太小会频繁发生async checkpoint,导致性能抖动。重做日志存在一个capacity,代表了最后的checkpoint不能够超过这个阈值,如果超过必须将缓冲区中的部分脏页刷新到磁盘中,此时可能会造成用户线程的阻塞。
+
+### redo log和binlog的区别
+#### 记录内容
+binlog记录的是一个事务的具体操作内容,该日志为逻辑日志。
+
+而innodb redo log记录的是关于某个页的修改,为物理日志。
+
+#### 写入时机
+binlog仅当事务提交前才进行提交,即只会写磁盘一次。
+
+redo log则是在事务运行过程中,不断有重做日志被写入到redo log file中。
+
+### redo log写入时机
+- master thread会每秒将redo log从buffer中刷新到redo log ile中,不露内事务是否已经提交
- innodb_flush_log_at_trx_commit控制redo log的刷新时机,默认情况下,在事务提交前会将数据从redo log buffer刷新到redo log file中
\ No newline at end of file
diff --git a/mysql/mysql文档/mysql_表.md b/mysql/mysql文档/mysql_表.md
index ea737b3..96d2e25 100644
--- a/mysql/mysql文档/mysql_表.md
+++ b/mysql/mysql文档/mysql_表.md
@@ -1,713 +1,713 @@
-- [表](#表)
- - [索引组织表](#索引组织表)
- - [innodb逻辑存储结构](#innodb逻辑存储结构)
- - [表空间](#表空间)
- - [innodb\_file\_per\_table](#innodb_file_per_table)
- - [段(segment)](#段segment)
- - [区(Extent)](#区extent)
- - [页(Page)](#页page)
- - [行](#行)
- - [innodb行记录格式](#innodb行记录格式)
- - [Compact](#compact)
- - [变长字段长度列表](#变长字段长度列表)
- - [NULL标志位](#null标志位)
- - [记录头信息](#记录头信息)
- - [行溢出数据](#行溢出数据)
- - [dynamic](#dynamic)
- - [char存储结构](#char存储结构)
- - [innodb数据页结构](#innodb数据页结构)
- - [File Header](#file-header)
- - [Infimum和Supremum record](#infimum和supremum-record)
- - [user record 和 free space](#user-record-和-free-space)
- - [page directory](#page-directory)
- - [B+树索引](#b树索引)
- - [File Trailer](#file-trailer)
- - [完整性校验](#完整性校验)
- - [分区表](#分区表)
- - [partition keys \& primary keys \& unique keys](#partition-keys--primary-keys--unique-keys)
- - [表中不存在唯一索引](#表中不存在唯一索引)
- - [后续向分区表添加唯一索引](#后续向分区表添加唯一索引)
- - [对非分区表进行分区](#对非分区表进行分区)
- - [分区类型](#分区类型)
- - [RANGE](#range)
- - [information\_schema.partitions](#information_schemapartitions)
- - [看select语句查询了哪些分区](#看select语句查询了哪些分区)
- - [插入超过分区范围的数据](#插入超过分区范围的数据)
- - [向分区表中添加分区](#向分区表中添加分区)
- - [向分区表中删除分区](#向分区表中删除分区)
- - [LIST](#list)
- - [HASH](#hash)
- - [新增HASH分区](#新增hash分区)
- - [减少HASH分区](#减少hash分区)
- - [LINEAR HASH](#linear-hash)
- - [KEY \& LINEAR KEY](#key--linear-key)
- - [COLUMNS](#columns)
- - [range columns](#range-columns)
- - [list columns](#list-columns)
- - [子分区](#子分区)
- - [分区中的NULL值](#分区中的null值)
- - [分区和性能](#分区和性能)
- - [不分区](#不分区)
- - [按id进行分区](#按id进行分区)
- - [在表和分区之间交换数据](#在表和分区之间交换数据)
-
-
-# 表
-## 索引组织表
-innodb存储引擎中,表都是根据主键顺序组织存放的,这种存储方式被称为索引组织表(index organized table)。在innodb存储引擎表中,每张表都有主键(primary key),如果在创建表时没有显式指定主键,那么innodb会按照如下方式创建主键:
-- 首先判断表中是否存在非空的唯一索引(unique not null)字段,如果有,则其为主键
-- 如果不存在非空唯一索引,那么innodb会自动创建一个6字节大小的指针作为主键
-
-如果有多个非空唯一索引,innodb存储引擎将会选择第一个定义的非空唯一索引作为主键。
-
-## innodb逻辑存储结构
-在innodb的存储逻辑结构中,所有的数据都被逻辑存放在表空间(table space)中。表空间则由`段(segement),区(extent),页(page)`组成。
-
-组成如图所示:
-
-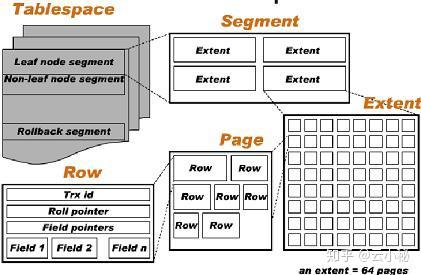 -
-### 表空间
-表空间为innodb存储引擎逻辑结构的最高层,所有数据都存放于表空间中。innodb存在一个默认的共享表空间`ibdata1`,在开启`innodb_file_per_table`参数后,每张表内的数据可以单独存放到一个表空间。
-
-#### innodb_file_per_table
-`innodb_file_per_table`参数启用会导致每张表的`数据、索引、插入缓冲bitmap页`存放到单独的文件中;但是其他数据,例如`回滚(undo)信息,插入缓冲页,系统事务信息,double write buffer`等还是存放在默认的共享表空间中。
-
-### 段(segment)
-如上图所示,表空间是由段(segment)所组成的,常见的段分为`数据段,索引段,回滚段`等。
-
-在innodb存储引擎中,数据即索引,索引即数据。`数据段即为B+树的叶子节点(Leaf node segment)`,`索引段即为B+树的非叶子节点(Non-leaf node segment)`。
-
-### 区(Extent)
-区是由连续页组成的空间,在任何情况下每个区的大小都为1MB。为了保证区中页的连续性,innodb存储引擎会一次性从磁盘申请4~5个区。在默认情况下,innodb存储引擎中页的大小为`16KB`,一个区中包含64个页。
-
-在新建表时,新建表的大小为96KB,小于一个Extent的大小1MB,因为每个段Segmenet开始时,都会有至多32个页大小的碎片页,等使用完这些页后才会申请64个连续页作为Extent。
-
-都与一些小表或是undo这样的段,可以在开始时申请较少的空间,节省磁盘容量开销。
-
-### 页(Page)
-innodb存储引擎中页的大小默认为`16KB`,默认的页大小可以通过`innodb_page_size`参数进行修改。通过该参数,可以将innodb的默认页大小设置为4K,8K。
-
-页是innodb磁盘管理的最小单位,在innodb中,常见的页有:
-- 数据页(B-tree node)
-- undo页(undo log page)
-- 系统页(system page)
-- 事务数据页(transaction system page)
-- 插入缓冲位图页(insert buffer bitmap)
-- 插入缓冲空闲列表页(insert buffer free list)
-- 未压缩的二进制大对象页(uncompressed blob page)
-- 压缩的二进制大对象页(compressed blob page)
-
-### 行
-innodb存储引擎是面向行的,数据按行进行存放。每个页中至多可以存放`16KB/2 - 200`行的记录,即7992行记录。
-
-## innodb行记录格式
-innodb存储引擎以行的形式进行存储,可以通过`show table status like '{table_name}'`的语句来查询表的行格式,示例如下:
-```sql
-show table status like 'demo_t1'
-```
-
-| Name | Engine | Version | Row\_format | Rows | Avg\_row\_length | Data\_length | Max\_data\_length | Index\_length | Data\_free | Auto\_increment | Create\_time | Update\_time | Check\_time | Collation | Checksum | Create\_options | Comment |
-| :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- |
-| demo\_t1 | InnoDB | 10 | Dynamic | 0 | 0 | 16384 | 0 | 32768 | 0 | 1 | 2025-01-30 15:18:57 | null | null | utf8mb4\_0900\_ai\_ci | null | | |
-
-上述示例中表的row_format为dynamic。
-
-### Compact
-在使用Compact行记录格式时,一个页中存放数据越多,其性能越高。
-
-Compact格式下行记录的存储格式如下:
-
-
-### 表空间
-表空间为innodb存储引擎逻辑结构的最高层,所有数据都存放于表空间中。innodb存在一个默认的共享表空间`ibdata1`,在开启`innodb_file_per_table`参数后,每张表内的数据可以单独存放到一个表空间。
-
-#### innodb_file_per_table
-`innodb_file_per_table`参数启用会导致每张表的`数据、索引、插入缓冲bitmap页`存放到单独的文件中;但是其他数据,例如`回滚(undo)信息,插入缓冲页,系统事务信息,double write buffer`等还是存放在默认的共享表空间中。
-
-### 段(segment)
-如上图所示,表空间是由段(segment)所组成的,常见的段分为`数据段,索引段,回滚段`等。
-
-在innodb存储引擎中,数据即索引,索引即数据。`数据段即为B+树的叶子节点(Leaf node segment)`,`索引段即为B+树的非叶子节点(Non-leaf node segment)`。
-
-### 区(Extent)
-区是由连续页组成的空间,在任何情况下每个区的大小都为1MB。为了保证区中页的连续性,innodb存储引擎会一次性从磁盘申请4~5个区。在默认情况下,innodb存储引擎中页的大小为`16KB`,一个区中包含64个页。
-
-在新建表时,新建表的大小为96KB,小于一个Extent的大小1MB,因为每个段Segmenet开始时,都会有至多32个页大小的碎片页,等使用完这些页后才会申请64个连续页作为Extent。
-
-都与一些小表或是undo这样的段,可以在开始时申请较少的空间,节省磁盘容量开销。
-
-### 页(Page)
-innodb存储引擎中页的大小默认为`16KB`,默认的页大小可以通过`innodb_page_size`参数进行修改。通过该参数,可以将innodb的默认页大小设置为4K,8K。
-
-页是innodb磁盘管理的最小单位,在innodb中,常见的页有:
-- 数据页(B-tree node)
-- undo页(undo log page)
-- 系统页(system page)
-- 事务数据页(transaction system page)
-- 插入缓冲位图页(insert buffer bitmap)
-- 插入缓冲空闲列表页(insert buffer free list)
-- 未压缩的二进制大对象页(uncompressed blob page)
-- 压缩的二进制大对象页(compressed blob page)
-
-### 行
-innodb存储引擎是面向行的,数据按行进行存放。每个页中至多可以存放`16KB/2 - 200`行的记录,即7992行记录。
-
-## innodb行记录格式
-innodb存储引擎以行的形式进行存储,可以通过`show table status like '{table_name}'`的语句来查询表的行格式,示例如下:
-```sql
-show table status like 'demo_t1'
-```
-
-| Name | Engine | Version | Row\_format | Rows | Avg\_row\_length | Data\_length | Max\_data\_length | Index\_length | Data\_free | Auto\_increment | Create\_time | Update\_time | Check\_time | Collation | Checksum | Create\_options | Comment |
-| :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- |
-| demo\_t1 | InnoDB | 10 | Dynamic | 0 | 0 | 16384 | 0 | 32768 | 0 | 1 | 2025-01-30 15:18:57 | null | null | utf8mb4\_0900\_ai\_ci | null | | |
-
-上述示例中表的row_format为dynamic。
-
-### Compact
-在使用Compact行记录格式时,一个页中存放数据越多,其性能越高。
-
-Compact格式下行记录的存储格式如下:
-
-
- | 变长字段长度列表 |
- NULL标志位 |
- 记录头信息 |
- 列1数据 |
- 列2数据 |
- ...... |
-
-
-
-
-#### 变长字段长度列表
-Compact行记录格式其首部是一个`非Null变长字段长度`列表,其按照列的顺序逆序放置,变长列的长度为:
-- 如果列的长度小于255字节,用1字节表示
-- 如果列的长度大于255字节,用2个字节表示
-
-变长字段的长度不能小于2字节,因为varchar类型最长长度限制为65535。
-
-#### NULL标志位
-NULL标志位为bitmap,代表每一列是否为空。如果行中存在n个字段可为空,那么NULL标志位部分的长度为ceiling(n/8)。
-
-#### 记录头信息
-record header,固定占用5字节,其中,record header的各bit含义如下所示:
-| 名称 | 大小(bit) | |
-| :-: | :-: | :-: |
-| () | 1 | 未知 |
-| () | 1 | 未知 |
-| deleted_flag | 1 | 该行是否已经被删除 |
-| min_rec_flag | 1 | 该行是否为预订被定义的最小记录行 |
-| n_owned | 4 | 该记录拥有的记录数 |
-| heap_no | 13 | 索引堆中该条记录的排序记录 |
-| record_type | 3 | 记录类型,000代表普通,001代表B+树节点指针, 010代表infimum,011代表supremum,1xx保留 |
-| next_record | 16 | 页中下一条记录相对位置 |
-
-除了上述3个部分之外,其他部分就是各个列的实际值。
-
-> 在Compact格式中,NULL除了占有NULL标志位外,不占用任何实际空间。
-
-> 每行数据中,除了有用户自定义的列外,还存在两个隐藏列,即`事务id列`和`回滚指针列`,长度分别为6字节和7字节。
->
-> 如果innodb表没有自定义主键,每行还会增加一个rowid列。
-
-### 行溢出数据
-innodb存储引擎可能将一条记录中某些数据存储在真正的存储数据页面之外。一般来说,blob、lob这类大对象的存储位于数据页面之外。
-
-当行数据的大小特别大,导致一个页无法存放2条行数据时,innodb会自动将占用空间大的`blob`字段或`varchar`字段值放到额外的uncompressed blob page中。
-
-### dynamic
-dynamic格式几乎和compact格式相同,但是对于每个blob字段,其存储只消耗20字节用于存储指针。
-
-而对于Compact格式,其会在blob格式中存储768字节的前缀字节。
-
-### char存储结构
-`char(n)`字段中n代表`字符长度`而非字节长度,故而在不同字符集下,char类型字段的内部存储可能不是定长的。
-
-例如,在utf8字符集下,`ab`和`我们`两个字符串,其字符数都是2个,但是`ab`其占用2字节,而`我们`占用4字节,即使同样是`char(2)`类型的字符串,其占用字节数量仍然有可能不同。
-
-## innodb数据页结构
-innodb中页是磁盘管理的最小结构,页类型为B-tree Node的页存放的即是表中行的实际数据。
-
-innodb数据页由如下7个部分组成:
-- File Header(文件头)
-- Page Header(页头)
-- Infimum和Supremum Records
-- user records(用户记录,即行记录)
-- free space(空闲空间)
-- page directory(页目录)
-- file trailer(文件结尾信息)
-
-file header,page header,file trailer的大小是固定的,分别为38,56,8字节,这些空间用于标记页的一些信息,例如checksum,数据页所在B+树的层数等。
-
-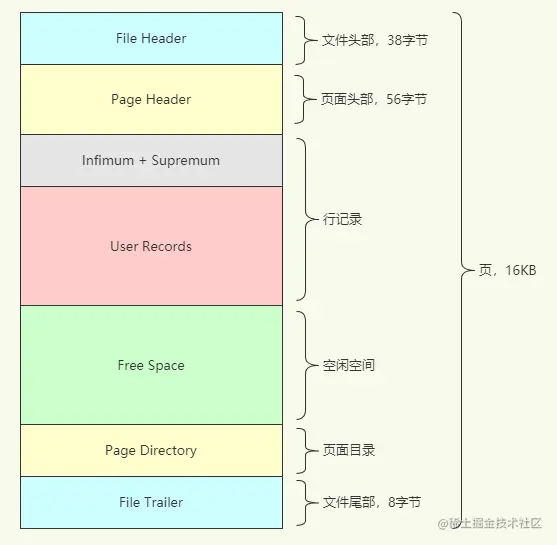 -
-### File Header
-File Header用于记录页的一些头信息,由8个部分组成,共占38字节:
-| 名称 | 大小 | 说明 |
-| :-: | :-: | :-: |
-| FIL_PAGE_SPACE_OR_CHKSUM | 4 | 代表页的checksum值 |
-| FIL_PAGE_OFFSET | 4 | 表空间中页的偏移位置 |
-| FIL_PAGE_PREV | 4 | 当前页的上一个页,B+树决定叶子节点为双向列表 |
-| FIL_PAGE_NEXT | 4 | 当前页的下一个页 |
-| FIL_PAGE_LSN | 8 | 代表该页最后被修改的日志序列位置LSN |
-| FIL_PAGE_TYPE | 2 | 存储引擎页类型 |
-| FIL_PAGE_FILE_FLUSH_LSN | 8 | 该值仅在系统表空间的一个页中定义,代表文件至少被更新到了该LSN值,对于独立的表空间,该值为0 |
-| FIL_PAGE_ARCH_LOG_NO_OR_SPACE_ID | 4 | 代表页属于哪个表空间 |
-
-### Infimum和Supremum record
-在innodb存储引擎中,每个数据页都有两行虚拟的行记录,用于限定记录边界。Infimum是比该页中所有主键值都要小的值,Supremum是比任何可能值都要大的值。`这两个值在页创建时被建立,并且在任何情况下都不会被删除。`
-
-### user record 和 free space
-user reocrd代表实际存储行记录中的内容,free space则是代表空闲空间,同样是链表数据结构,在一条记录被删除后,该空间会被加入到空闲列表中。
-
-### page directory
-page directory(页目录)中存放了记录的相对位置,这些记录指针被称为目录槽(directory slots)。`innodb中槽是一个稀疏目录,一个槽中可能包含多个记录`,记录Infimum的n_owned总为1,记录Supremum的n_owned取值范围为`[1,8]`,其他用户记录的n_owned为`[4,8]`。当记录被插入或删除时,需要对槽进行分裂或平衡的维护操作。
-
-在slots中,记录按照索引键值顺序存放,可以通过二叉查询迅速找到记录的指针。
-
-由于在innodb存储引擎中,page directory是稀疏目录,二叉查找结果只是一个粗略的结果,innodb存储引擎必须通过record header中的next_record来继续查找相关记录。
-
-#### B+树索引
-
-
-### File Header
-File Header用于记录页的一些头信息,由8个部分组成,共占38字节:
-| 名称 | 大小 | 说明 |
-| :-: | :-: | :-: |
-| FIL_PAGE_SPACE_OR_CHKSUM | 4 | 代表页的checksum值 |
-| FIL_PAGE_OFFSET | 4 | 表空间中页的偏移位置 |
-| FIL_PAGE_PREV | 4 | 当前页的上一个页,B+树决定叶子节点为双向列表 |
-| FIL_PAGE_NEXT | 4 | 当前页的下一个页 |
-| FIL_PAGE_LSN | 8 | 代表该页最后被修改的日志序列位置LSN |
-| FIL_PAGE_TYPE | 2 | 存储引擎页类型 |
-| FIL_PAGE_FILE_FLUSH_LSN | 8 | 该值仅在系统表空间的一个页中定义,代表文件至少被更新到了该LSN值,对于独立的表空间,该值为0 |
-| FIL_PAGE_ARCH_LOG_NO_OR_SPACE_ID | 4 | 代表页属于哪个表空间 |
-
-### Infimum和Supremum record
-在innodb存储引擎中,每个数据页都有两行虚拟的行记录,用于限定记录边界。Infimum是比该页中所有主键值都要小的值,Supremum是比任何可能值都要大的值。`这两个值在页创建时被建立,并且在任何情况下都不会被删除。`
-
-### user record 和 free space
-user reocrd代表实际存储行记录中的内容,free space则是代表空闲空间,同样是链表数据结构,在一条记录被删除后,该空间会被加入到空闲列表中。
-
-### page directory
-page directory(页目录)中存放了记录的相对位置,这些记录指针被称为目录槽(directory slots)。`innodb中槽是一个稀疏目录,一个槽中可能包含多个记录`,记录Infimum的n_owned总为1,记录Supremum的n_owned取值范围为`[1,8]`,其他用户记录的n_owned为`[4,8]`。当记录被插入或删除时,需要对槽进行分裂或平衡的维护操作。
-
-在slots中,记录按照索引键值顺序存放,可以通过二叉查询迅速找到记录的指针。
-
-由于在innodb存储引擎中,page directory是稀疏目录,二叉查找结果只是一个粗略的结果,innodb存储引擎必须通过record header中的next_record来继续查找相关记录。
-
-#### B+树索引
- -如上图所示,innodb中的数据是按照索引来进行组织的。但是,通过B+树索引,其无法直接查询到指定的记录,其只能查询到记录所位于的页。
-
-例如,在上图示例中,其在查询`ID=32`的时,只能查询到该记录位于page 17中。
-
-> 在B+树的叶子节点,每个页的File Header中都存有指向前一个页和后一个页的指针,`故而每个页之间是通过双向列表结构来维护的`;但是对于页中的记录,`记录与记录之间维维护的时单向列表的关系`。
->
-> 对于Compact或Dynamic行格式的页,其每条记录的record header中都包含一个next_record字段指向下一条记录。故而,位于同一个页中的记录可以单向访问。
-
-但是,在一个页内查找某条记录时,沿着单向链表进行查找其效率很低。故而,page中的数据时机被分为了多个组,被分为的组构成了一个subdirectory,故而,通过子目录能够缩小查询范围,提高查询性能。
-
-page directory是一个能够存储多个slots的部分,每个slot中存储了group中最后一条记录的相对位置。假设slot中最大一条记录为`r`,那么group中记录的条数被存储在`r`记录record header的`n_owned`字段中。
-
-group中record的数量约束如下:
-- infimum group中records数量限制为`[1,8]`
-- supremum group中records数量限制为`[1,8]`
-- 其他group中records限制为`[4,8]`
-
-page directory生成过程如下所示:
-- 最开始时,页中只有infimum和supremum两条记录,它们分别属于两个group。page directory中有两个slots指向这两条记录,两个slot的n_owned都为1
-- 后续,当新的记录被插入页时,系统会查找page directory中主键值大于待插入记录的第一个slot。slot对应最大记录的`n_owned`字段会增加1,代表group中新插入了记录,直到group中的记录数量到达8
-- 当新纪录被插入到的group中记录数大于8时,group中的记录被分为2个group,一个group包含4条记录,另一个group包含5条记录。该过程将会向page directory中新增一个新的slot
-- 当记录被删除时,slot最最大一条记录的`n_owned`将会减少1,当n_owned字段小于4时,会触发再平衡操作,平衡后的page directory满足上述要求
-
-page directory中的slots数量如page header中的`PAGE_N_DIR_SLOTS`所示。
-
-一旦innodb中页包含page directory后,其会通过二分查找快速的定位slot,并且从group中最小记录开始,通过`next_record`指针来遍历页中的记录列表。这样能够快速的定位记录位置。
-
-### File Trailer
-
-#### 完整性校验
-在innodb中,页的大小为16KB,可能和磁盘的扇区大小不同。通常磁盘的扇区大小为512字节,故而在写入一个页到磁盘中时,需要分32个扇区进行写入。
-
-在写入一个页时,可能会发生宕机场景,这时,一个页只写入了一部分,可能会发生脏写。此时,可以通过double write buffer机制对脏写的页进行恢复。
-
-在一个页被写入到磁盘中时,首先会被写入的是File Header的`FIL_PAGE_SPACE_OR_CHKSUM`,该部分是page的checksum。
-
-innodb设置了File Trailer部分来校验page是否被完全写入到磁盘中,File Trailer中只包含一个`FIL_PAGE_END_LSN`部分,占用8字节,前4字节代表该页的checksum值,后4字节和File Header中的`FIL_PAGE_LSN`相同,`代表最后一次修改该页关联的LSN位置`。将上述两个字段和File Header中的`FIL_PAGE_SPACE_OR_CHKSUM`和`FIL_PAGE_LSN`值进行比较,查看是否一致,从而保证页的完整性。
-
-默认情况下,在innodb每次从磁盘读取page时,都会检查页面的完整性。
-
-## 分区表
-innodb存储引擎支持分区功能,分区过程将一个表或索引分为多个更小、更可管理的部分。
-
-对于访问数据库的应用而言,逻辑上的一个表或索引,其物理上可能由多个物理分区组成,每个分区都是独立的对象,既可以独自进行处理,又可以作为一个更大对象的一部分进行处理。
-
-> mysql仅支持水平分区(将同一张表中的不同行记录分配到不同的物理文件中),并不支持垂直分区(将同一张表中的不同列分配到不同的物理文件中)。
-
-目前mysql支持如下几种类型的分区:
-- `RANGE`: 行数据基于一个给定连续区间的列值被放入分区
-- `LIST`: 和`RANGE`类似,但`LIST`分区面对的是更加离散的值
-- `HASH`: 根据用户自定义的表达式返回值来进行分区,返回值不能为负数
-- `KEY`:根据mysql提供的哈希函数来进行分区
-
-`不论创建何种类型的分区,如果表中存在唯一索引或主键,分区列必须是唯一索引的一个组成部分。`
-
-### partition keys & primary keys & unique keys
-对于分区表而言,`所有在partition expression中使用到的col,其必须被包含在分区表所有的唯一索引中`。
-
-> `所有唯一索引`中包含主键索引。
-
-正确建立分区表的声明示例如下:
-```sql
-CREATE TABLE t1 (
- col1 INT NOT NULL,
- col2 DATE NOT NULL,
- col3 INT NOT NULL,
- col4 INT NOT NULL,
- UNIQUE KEY (col1, col2, col3)
-)
-PARTITION BY HASH(col3)
-PARTITIONS 4;
-
-CREATE TABLE t2 (
- col1 INT NOT NULL,
- col2 DATE NOT NULL,
- col3 INT NOT NULL,
- col4 INT NOT NULL,
- UNIQUE KEY (col1, col3)
-)
-PARTITION BY HASH(col1 + col3)
-PARTITIONS 4;
-
-
-CREATE TABLE t7 (
- col1 INT NOT NULL,
- col2 DATE NOT NULL,
- col3 INT NOT NULL,
- col4 INT NOT NULL,
- PRIMARY KEY(col1, col2)
-)
-PARTITION BY HASH(col1 + YEAR(col2))
-PARTITIONS 4;
-
-CREATE TABLE t8 (
- col1 INT NOT NULL,
- col2 DATE NOT NULL,
- col3 INT NOT NULL,
- col4 INT NOT NULL,
- PRIMARY KEY(col1, col2, col4),
- UNIQUE KEY(col2, col1)
-)
-PARTITION BY HASH(col1 + YEAR(col2))
-PARTITIONS 4;
-
-
-create table t2_partition (
- col1 int ,
- col2 date,
- col3 int null,
- col4 int null,
- unique index `idx_t2_partition_cols` (col1, col2,col3),
- primary key (col2, col1)
-)
-partition by hash(col1)
-partitions 4;
-```
-#### 表中不存在唯一索引
-如果表中没有唯一索引(也未定义primary key),那么上述要求并不会生效,可以在partition expression中使用任意cols。
-
-#### 后续向分区表添加唯一索引
-如果想要向分区表中添加唯一索引,那么新增的唯一索引中必须包含partition expression中所有的列。
-
-#### 对非分区表进行分区
-可以参照如下示例对非分区表进行分区:
-```sql
-CREATE TABLE np_pk (
- id INT NOT NULL AUTO_INCREMENT,
- name VARCHAR(50),
- added DATE,
- PRIMARY KEY (id)
-);
-```
-可以按`id`进行分区
-```sql
-ALTER TABLE np_pk
- PARTITION BY HASH(id)
- PARTITIONS 4;
-```
-### 分区类型
-#### RANGE
-RANGE为较常见的分区类型,如下示例为创建RANGE类型分区表的示例:
-```sql
-create table t1 (
- id bigint auto_increment not null,
- tran_date datetime(6) not null default now(6) on update now(6),
- primary key (id, tran_date)
-) engine=innodb
-partition by range (year(tran_date)) (
- partition part_y_let_2024 values less than (2025),
- partition part_y_eq_2025 values less than (2026)
- );
-```
-上述创建了表`t1`,t1主键为`(id, tran_date)`,且按照`tran_date`字段的年部分进行分区,分区类型为RANGE。
-
-表t1的分区为两部分,分区1为`tran_date位于2024或之前年份`的分区`part_y_let_2024`,分区2是`tran_date位于2025年`的分区`part_y_eq_2025`。
-
-##### information_schema.partitions
-如果要查看表的分区情况,可以查询`information_schema.partitions`表,示例如下
-```sql
-select * from information_schema.partitions where table_schema = 'learn_innodb' and table_name = 't1';
-```
-查询结果如下所示:
-| TABLE\_CATALOG | TABLE\_SCHEMA | TABLE\_NAME | PARTITION\_NAME | SUBPARTITION\_NAME | PARTITION\_ORDINAL\_POSITION | SUBPARTITION\_ORDINAL\_POSITION | PARTITION\_METHOD | SUBPARTITION\_METHOD | PARTITION\_EXPRESSION | SUBPARTITION\_EXPRESSION | PARTITION\_DESCRIPTION | TABLE\_ROWS | AVG\_ROW\_LENGTH | DATA\_LENGTH | MAX\_DATA\_LENGTH | INDEX\_LENGTH | DATA\_FREE | CREATE\_TIME | UPDATE\_TIME | CHECK\_TIME | CHECKSUM | PARTITION\_COMMENT | NODEGROUP | TABLESPACE\_NAME |
-| :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- |
-| def | learn\_innodb | t1 | part\_y\_eq\_2025 | null | 2 | null | RANGE | null | year\(\`tran\_date\`\) | null | 2026 | 0 | 0 | 16384 | 0 | 0 | 0 | 2025-02-08 01:05:53 | null | null | null | | default | null |
-| def | learn\_innodb | t1 | part\_y\_let\_2024 | null | 1 | null | RANGE | null | year\(\`tran\_date\`\) | null | 2025 | 0 | 0 | 16384 | 0 | 0 | 0 | 2025-02-08 01:05:53 | null | null | null | | default | null |
-
-为分区表预置如下数据
-```sql
-insert into t1(tran_date) values ('2023-01-01'), ('2024-12-31'), ('2025-01-01');
-```
-可以看到分区表中数据分布如下:
-```sql
-select partition_name, table_rows from information_schema.partitions where table_schema = 'learn_innodb' and table_name = 't1';
-```
-| PARTITION\_NAME | TABLE\_ROWS |
-| :--- | :--- |
-| part\_y\_eq\_2025 | 1 |
-| part\_y\_let\_2024 | 2 |
-
-易知`('2023-01-01'), ('2024-12-31')`数据位于`part_y_let_2024`分区,故而该分区存在两条数据;而`('2025-01-01')`数据位于`part_y_let_2024`分区,该分区存在一条数据。
-
-##### 看select语句查询了哪些分区
-数据分布可以通过如下方式验证:
-```sql
-explain select * from t1 where tran_date >= '2023-01-01' and tran_date <= '2024-12-31';
-```
-| id | select\_type | table | partitions | type | possible\_keys | key | key\_len | ref | rows | filtered | Extra |
-| :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- |
-| 1 | SIMPLE | t1 | part\_y\_let\_2024 | index | PRIMARY | PRIMARY | 16 | null | 2 | 50 | Using where; Using index |
-
-```sql
-explain select * from t1 where tran_date >= '2025-01-01'
-```
-| id | select\_type | table | partitions | type | possible\_keys | key | key\_len | ref | rows | filtered | Extra |
-| :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- |
-| 1 | SIMPLE | t1 | part\_y\_eq\_2025 | index | PRIMARY | PRIMARY | 16 | null | 1 | 100 | Using where; Using index |
-
-##### 插入超过分区范围的数据
-如果尝试向分区表中插入超过所有分区范围的数据,会执行失败,示例如下:
-```sql
-insert into t1(tran_date) values ('2026-01-01');
-```
-由于分区表`t1`中现有分区最大只支持2025年的分区,故而当尝试插入2026年分区时,会抛出如下错误:
-```bash
-[2025-02-08 01:32:51] [HY000][1526] Table has no partition for value 2026
-```
-##### 向分区表中添加分区
-mysql支持向分区表中添加分区,语法如下
-```sql
-alter table t1 add partition (
- partition part_year_egt_2026 values less than maxvalue
- );
-```
-添加分区后,mysql支持`tran_date大于等于2026`的分区,执行如下语句
-```sql
-insert into t1(tran_date) values ('2026-01-01'), ('2027-12-31'), ('2028-01-01');
-```
-之后,再次分区分区中的数据分区,结果如下
-| PARTITION\_NAME | TABLE\_ROWS |
-| :--- | :--- |
-| part\_y\_eq\_2025 | 1 |
-| part\_y\_let\_2024 | 2 |
-| part\_year\_egt\_2026 | 3 |
-
-> `information.partitions`表中,`table_rows`字段可能存在不准确的情况,如果想要获取准确的值,需要执行`analyze table {schema}.{table_name}`语句
-
-##### 向分区表中删除分区
-当想要删除分区表中现存分区时,可以通过执行如下语句
-```sql
-alter table t1 drop partition part_year_egt_2026;
-```
-在删除分区后,分区中的数据也会被删除,执行查询语句后
-```sql
-select * from t1;
-
-```
-可知`part_year_egt_2026`被删除后分区中数据全部消失
-| id | tran\_date |
-| :--- | :--- |
-| 1 | 2023-01-01 00:00:00.000000 |
-| 2 | 2024-12-31 00:00:00.000000 |
-| 3 | 2025-01-01 00:00:00.000000 |
-
-#### LIST
-LIST分区类型和RANGE分区类型非常相似,但是LIST分区列的值是离散的,RANGE分区列的值是连续的。
-
-创建LIST类型分区表的示例如下:
-```sql
-create table p_list_t1 (
- id bigint not null auto_increment,
- area smallint not null,
- primary key (id, area)
-)
-partition by list (area) (
- partition p_ch_beijing values in (1),
- partition p_ch_hubei values in (2),
- partition p_ch_jilin values in (3)
- );
-```
-之后可向`p_list_t1`表中预置数据,执行语句如下:
-```sql
-insert into p_list_t1(area) values (1),(1), (2), (3), (3);
-```
-此时,数据分布如下:
-| PARTITION\_METHOD | PARTITION\_NAME | TABLE\_ROWS |
-| :--- | :--- | :--- |
-| LIST | p\_ch\_beijing | 2 |
-| LIST | p\_ch\_hubei | 1 |
-| LIST | p\_ch\_jilin | 2 |
-
-如果想要向分区表中插入不位于现存分区中的值,那么插入语句同样会执行失败,示例如下
-```sql
-insert into p_list_t1(area) values (4);
-```
-由于目前没有area为4的分区,故而插入语句执行失败,报错如下
-```bash
-[2025-02-09 20:30:03] [HY000][1526] Table has no partition for value 4
-```
-
-#### HASH
-HASH分区方式是将数据均匀分布到预先定义的各个分区中,期望各个分区中散列的数据数量大致相同。
-
-在通过hash来进行分区时,建表时需要指定一个分区表达式,该表达式返回整数。
-
-创建hash分区的示例如下:
-```sql
-create table p_hash_t1 (
- id bigint not null auto_increment,
- content varchar(256),
- primary key (id)
-)
-partition by hash (id)
-partitions 4;
-```
-上述ddl创建了一个按照`id`列进行hash分区的分区表,分区表包含4个分区。
-
-预置数据sql如下:
-```sql
-insert into p_hash_t1(content) values ('asahi'), ('maki'), ('katahara');
-```
-预置数据后数据分布如下
-| PARTITION\_METHOD | PARTITION\_NAME | TABLE\_ROWS |
-| :--- | :--- | :--- |
-| HASH | p0 | 0 |
-| HASH | p1 | 1 |
-| HASH | p2 | 1 |
-| HASH | p3 | 1 |
-
-预置的三条数据id分别为`1, 2, 3`,被hash放置到分区`p1, p2, p3`中。
-
-> 当使用hash分区方式时,例如存在`4`个分区,对于待插入数据其分区表达式的值为`2`,那么待插入数据将会被插入到`2%4 = 2`,第`3`个分区中(0,1,2分区,排第三),也就是`p2`。
->
-> 可以通过`explain select * from p_hash_t1 where id = 2;`语句来进行验证,得到如下结果。
->
-> | id | select\_type | table | partitions | type | possible\_keys | key | key\_len | ref | rows | filtered | Extra |
-> | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- |
-> | 1 | SIMPLE | p\_hash\_t1 | p2 | const | PRIMARY | PRIMARY | 8 | const | 1 | 100 | null |
-
-
-##### 新增HASH分区
-对于hash分区方式,可以通过如下方式来新增分区:
-```sql
-alter table p_hash_t1 add partition partitions 3;
-```
-其会新增3个分区,执行后分区数量为7。
-
-此时,原本分区中的数据会被重新散列到新分区中
-
-##### 减少HASH分区
-对于hash分区,在尝试减少分区数量的同时,通常不希望删除任何数据,故而无法使用`drop`。
-
-故而,可以使用`coalesce`,其只会减少分区数量,不会删除数据。
-
-示例如下:
-```sql
-alter table p_hash_t1 coalesce partition 4;
-```
-上述语句会将分区数量减少4个,故而减少后分区数量为`3`。
-
-
-#### LINEAR HASH
-创建linear hash分区表的方式和hash类似,可以通过如下方式
-```sql
-create table p_linear_hash_t1 (
- id bigint not null auto_increment,
- content varchar(256),
- primary key(id)
-)
-partition by linear hash (id)
-partitions 5;
-```
-相较于hash分区,在使用linear hash分区时,添加、删除、合并、拆分分区将会变得更加快捷,但是相比于hash分区,其数据分区可能会不太均匀。
-
-#### KEY & LINEAR KEY
-KEY分区方式和HASH分区方式类似,但是HASH分区采用用户自定义的函数进行分区,而KEY分区方式则是采用mysql提供的函数进行分区。
-
-创建key分区表的示例如下:
-```sql
-create table p_key_t1 (
- id bigint not null auto_increment,
- content varchar(256),
- primary key(id)
-)
-partition by key(id)
-partitions 5;
-```
-> key分区方式同样可以使用linear进行修饰,效果和hash分区方式类似。
-
-> 对于key分区,可以指定除了integer之外的col类型,而`range, list, hash`等分区类型只支持integer类型的col。
-
-
-#### COLUMNS
-COLUMNS分区方式为`RANGE`和`LIST`分区的变体。
-
-COLUMNS分区方式支持在分区时使用多个列,在插入新数据或查询数据决定分区时,所有的列都会被考虑。
-
-COLUMNS分区方式分为如下两种
-- RANGE COLUMNS
-- LIST COLUMNS
-
-上述两种方式都支持非整数类型的列,COLUMNS支持的数据类型如下:
-- 所有integers类型(DECIMAL, FLOAT则不受支持)
-- DATE和DATETIME类型
-- 字符串类型:CHAR, VARCHAR, BINARY, VARBINARY(TEXT, BLOB类型不受支持)
-
-##### range columns
-创建range columns分区表的示例如下:
-```sql
-create table p_range_columns_t1 (
- id bigint not null auto_increment,
- name varchar(256),
- born_ts datetime(6),
- primary key (id, born_ts)
-)
-partition by range columns (born_ts) (
- partition p0 values less than ('1900-01-01'),
- partition p1 values less than ('2000-01-01'),
- partition p2 values less than ('2999-01-01')
- );
-```
-
-##### list columns
-创建list columns分区表的示例则如下:
-```sql
-create table p_list_columns_t1 (
- id bigint not null auto_increment,
- province varchar(256),
- city varchar(256),
- primary key (id, province, city)
-)
-partition by list columns (province, city) (
- partition p_beijing values in (('china', 'beijing')),
- partition p_wuhan values in (('hubei', 'wuhan'))
- );
-```
-
-> 通过range columns和list columns,可以很好的替代range和list分区,而无需将列值都转换为整型。
-
-### 子分区
-`子分区`代表在分区的基础上再次进行分区,mysql允许`在range和list分区的基础`上再次进行`hash或key`的子分区,示例如下:
-```sql
-create table p_list_columns_t1 (
- id bigint not null auto_increment,
- province varchar(256),
- city varchar(256),
- primary key (id, province, city)
-)
-partition by list columns (province, city)
-subpartition by key(id)
-subpartitions 3
-(
- partition p_beijing values in (('china', 'beijing')),
- partition p_wuhan values in (('hubei', 'wuhan'))
-);
-```
-上述示例先按照`list columns`分区方式进行了分区,然后在为每个分区都按`key`分了三个子分区,查看分区和子分区详情可以通过如下语句:
-```sql
-select partition_name, partition_method, subpartition_name, subpartition_method from information_schema.partitions where table_name = 'p_list_columns_t1';
-```
-| PARTITION\_NAME | PARTITION\_METHOD | SUBPARTITION\_NAME | SUBPARTITION\_METHOD |
-| :--- | :--- | :--- | :--- |
-| p\_wuhan | LIST COLUMNS | p\_wuhansp0 | KEY |
-| p\_wuhan | LIST COLUMNS | p\_wuhansp1 | KEY |
-| p\_wuhan | LIST COLUMNS | p\_wuhansp2 | KEY |
-| p\_beijing | LIST COLUMNS | p\_beijingsp0 | KEY |
-| p\_beijing | LIST COLUMNS | p\_beijingsp1 | KEY |
-| p\_beijing | LIST COLUMNS | p\_beijingsp2 | KEY |
-
-### 分区中的NULL值
-mysql允许对null值做分区,但`mysql数据库中的分区总是视null值小于任何非null的值`,该逻辑`和order by处理null值的逻辑一致`。
-
-故而,在使用不同的分区类型时,对于null值的处理逻辑如下:
-- 对于range类型分区,当插入null值时,其会被放在最左侧的分区中
-- 对于list类型的分区,如果要插入null值,必须在分区的`values in (...)`表达式中指定null值,否则插入语句将会报错
-- hash和key的分区类型,将会将null值当作`0`来散列
-
-### 分区和性能
-对于OLTP类型的应用,使用分区表时应该相当小心,因为分区表可能会带来严重的性能问题。
-
-例如,对于包含1000w条数据的表`t`,如果包含主键索引`id`和非主键索引`code`,分区和不分区,其性能分析如下
-
-#### 不分区
-如果不对表t进行分区,那么根据`id`(唯一主键索引)或`code`(非unique索引)进行查询,例如`select * from t where id = xxx`或`select * from t where code = xxx`时,可能只会进行2~3次磁盘io(1000w数据构成的B+树其层高为2~3)。
-
-#### 按id进行分区
-如果对表`t`按照`id`进行`hash`分区,分为10个分区,那么:
-- 对于按`id`进行查找的语句`select * from t where id = xxx`
- - 将t按id分为10个区后,如果分区均匀,那么每个分区数据大概为100w,对分区的查询开销大概为2次磁盘io
- - 根据`id`的查询只会在一个分区内进行查找,故而磁盘io会从3次减少为2次,可以提升查询效率
-- 对于按`code`进行查找的语句`select * from t where code = xxx`
- - 对于按code进行查找的语句,需要扫描所有的10个分区,每个分区大概需要2次磁盘io,故而总共的磁盘io大约为20次
-
-> 在使用分区表时,应尽量小心,不正确的使用分区将可能会带来大量的io,造成性能瓶颈
-
-### 在表和分区之间交换数据
-mysql支持在表分区和非分区表之间交换数据:
-- 在非分区表为空的场景下,相当于将分区中的数据移动到非分区表中
-- 在表分区为空的场景下,相当于将非分区表中的数据移动到表分区中
-
-在表和分区之间交换数据,可以通过`alter table ... exchange partition`语句,且必须满足如下条件:
-- 要交换的非分区表和分区表必须要拥有相同的结构,但是,非分区表中不能够含有分区
-- 非分区表中的数据都要位于表分区的范围内
-- 被交换的表中不能含有外键,或是其他表含有被交换表的外键引用
-- 用户需要拥有`alter, insert, create, drop`权限
-- 使用`alter table ... exchange parition`语句时,不会触发交换表和被交换表上的触发器
-- `auto_increment`将会被重置
-
-`exchange partition ... with table`的示例如下:
-```sql
-alter table p_range_columns_t exchange partition p_2024 with table np_t
-```
+- [表](#表)
+ - [索引组织表](#索引组织表)
+ - [innodb逻辑存储结构](#innodb逻辑存储结构)
+ - [表空间](#表空间)
+ - [innodb\_file\_per\_table](#innodb_file_per_table)
+ - [段(segment)](#段segment)
+ - [区(Extent)](#区extent)
+ - [页(Page)](#页page)
+ - [行](#行)
+ - [innodb行记录格式](#innodb行记录格式)
+ - [Compact](#compact)
+ - [变长字段长度列表](#变长字段长度列表)
+ - [NULL标志位](#null标志位)
+ - [记录头信息](#记录头信息)
+ - [行溢出数据](#行溢出数据)
+ - [dynamic](#dynamic)
+ - [char存储结构](#char存储结构)
+ - [innodb数据页结构](#innodb数据页结构)
+ - [File Header](#file-header)
+ - [Infimum和Supremum record](#infimum和supremum-record)
+ - [user record 和 free space](#user-record-和-free-space)
+ - [page directory](#page-directory)
+ - [B+树索引](#b树索引)
+ - [File Trailer](#file-trailer)
+ - [完整性校验](#完整性校验)
+ - [分区表](#分区表)
+ - [partition keys \& primary keys \& unique keys](#partition-keys--primary-keys--unique-keys)
+ - [表中不存在唯一索引](#表中不存在唯一索引)
+ - [后续向分区表添加唯一索引](#后续向分区表添加唯一索引)
+ - [对非分区表进行分区](#对非分区表进行分区)
+ - [分区类型](#分区类型)
+ - [RANGE](#range)
+ - [information\_schema.partitions](#information_schemapartitions)
+ - [看select语句查询了哪些分区](#看select语句查询了哪些分区)
+ - [插入超过分区范围的数据](#插入超过分区范围的数据)
+ - [向分区表中添加分区](#向分区表中添加分区)
+ - [向分区表中删除分区](#向分区表中删除分区)
+ - [LIST](#list)
+ - [HASH](#hash)
+ - [新增HASH分区](#新增hash分区)
+ - [减少HASH分区](#减少hash分区)
+ - [LINEAR HASH](#linear-hash)
+ - [KEY \& LINEAR KEY](#key--linear-key)
+ - [COLUMNS](#columns)
+ - [range columns](#range-columns)
+ - [list columns](#list-columns)
+ - [子分区](#子分区)
+ - [分区中的NULL值](#分区中的null值)
+ - [分区和性能](#分区和性能)
+ - [不分区](#不分区)
+ - [按id进行分区](#按id进行分区)
+ - [在表和分区之间交换数据](#在表和分区之间交换数据)
+
+
+# 表
+## 索引组织表
+innodb存储引擎中,表都是根据主键顺序组织存放的,这种存储方式被称为索引组织表(index organized table)。在innodb存储引擎表中,每张表都有主键(primary key),如果在创建表时没有显式指定主键,那么innodb会按照如下方式创建主键:
+- 首先判断表中是否存在非空的唯一索引(unique not null)字段,如果有,则其为主键
+- 如果不存在非空唯一索引,那么innodb会自动创建一个6字节大小的指针作为主键
+
+如果有多个非空唯一索引,innodb存储引擎将会选择第一个定义的非空唯一索引作为主键。
+
+## innodb逻辑存储结构
+在innodb的存储逻辑结构中,所有的数据都被逻辑存放在表空间(table space)中。表空间则由`段(segement),区(extent),页(page)`组成。
+
+组成如图所示:
+
+
+
+### 表空间
+表空间为innodb存储引擎逻辑结构的最高层,所有数据都存放于表空间中。innodb存在一个默认的共享表空间`ibdata1`,在开启`innodb_file_per_table`参数后,每张表内的数据可以单独存放到一个表空间。
+
+#### innodb_file_per_table
+`innodb_file_per_table`参数启用会导致每张表的`数据、索引、插入缓冲bitmap页`存放到单独的文件中;但是其他数据,例如`回滚(undo)信息,插入缓冲页,系统事务信息,double write buffer`等还是存放在默认的共享表空间中。
+
+### 段(segment)
+如上图所示,表空间是由段(segment)所组成的,常见的段分为`数据段,索引段,回滚段`等。
+
+在innodb存储引擎中,数据即索引,索引即数据。`数据段即为B+树的叶子节点(Leaf node segment)`,`索引段即为B+树的非叶子节点(Non-leaf node segment)`。
+
+### 区(Extent)
+区是由连续页组成的空间,在任何情况下每个区的大小都为1MB。为了保证区中页的连续性,innodb存储引擎会一次性从磁盘申请4~5个区。在默认情况下,innodb存储引擎中页的大小为`16KB`,一个区中包含64个页。
+
+在新建表时,新建表的大小为96KB,小于一个Extent的大小1MB,因为每个段Segmenet开始时,都会有至多32个页大小的碎片页,等使用完这些页后才会申请64个连续页作为Extent。
+
+都与一些小表或是undo这样的段,可以在开始时申请较少的空间,节省磁盘容量开销。
+
+### 页(Page)
+innodb存储引擎中页的大小默认为`16KB`,默认的页大小可以通过`innodb_page_size`参数进行修改。通过该参数,可以将innodb的默认页大小设置为4K,8K。
+
+页是innodb磁盘管理的最小单位,在innodb中,常见的页有:
+- 数据页(B-tree node)
+- undo页(undo log page)
+- 系统页(system page)
+- 事务数据页(transaction system page)
+- 插入缓冲位图页(insert buffer bitmap)
+- 插入缓冲空闲列表页(insert buffer free list)
+- 未压缩的二进制大对象页(uncompressed blob page)
+- 压缩的二进制大对象页(compressed blob page)
+
+### 行
+innodb存储引擎是面向行的,数据按行进行存放。每个页中至多可以存放`16KB/2 - 200`行的记录,即7992行记录。
+
+## innodb行记录格式
+innodb存储引擎以行的形式进行存储,可以通过`show table status like '{table_name}'`的语句来查询表的行格式,示例如下:
+```sql
+show table status like 'demo_t1'
+```
+
+| Name | Engine | Version | Row\_format | Rows | Avg\_row\_length | Data\_length | Max\_data\_length | Index\_length | Data\_free | Auto\_increment | Create\_time | Update\_time | Check\_time | Collation | Checksum | Create\_options | Comment |
+| :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- |
+| demo\_t1 | InnoDB | 10 | Dynamic | 0 | 0 | 16384 | 0 | 32768 | 0 | 1 | 2025-01-30 15:18:57 | null | null | utf8mb4\_0900\_ai\_ci | null | | |
+
+上述示例中表的row_format为dynamic。
+
+### Compact
+在使用Compact行记录格式时,一个页中存放数据越多,其性能越高。
+
+Compact格式下行记录的存储格式如下:
+
-如上图所示,innodb中的数据是按照索引来进行组织的。但是,通过B+树索引,其无法直接查询到指定的记录,其只能查询到记录所位于的页。
-
-例如,在上图示例中,其在查询`ID=32`的时,只能查询到该记录位于page 17中。
-
-> 在B+树的叶子节点,每个页的File Header中都存有指向前一个页和后一个页的指针,`故而每个页之间是通过双向列表结构来维护的`;但是对于页中的记录,`记录与记录之间维维护的时单向列表的关系`。
->
-> 对于Compact或Dynamic行格式的页,其每条记录的record header中都包含一个next_record字段指向下一条记录。故而,位于同一个页中的记录可以单向访问。
-
-但是,在一个页内查找某条记录时,沿着单向链表进行查找其效率很低。故而,page中的数据时机被分为了多个组,被分为的组构成了一个subdirectory,故而,通过子目录能够缩小查询范围,提高查询性能。
-
-page directory是一个能够存储多个slots的部分,每个slot中存储了group中最后一条记录的相对位置。假设slot中最大一条记录为`r`,那么group中记录的条数被存储在`r`记录record header的`n_owned`字段中。
-
-group中record的数量约束如下:
-- infimum group中records数量限制为`[1,8]`
-- supremum group中records数量限制为`[1,8]`
-- 其他group中records限制为`[4,8]`
-
-page directory生成过程如下所示:
-- 最开始时,页中只有infimum和supremum两条记录,它们分别属于两个group。page directory中有两个slots指向这两条记录,两个slot的n_owned都为1
-- 后续,当新的记录被插入页时,系统会查找page directory中主键值大于待插入记录的第一个slot。slot对应最大记录的`n_owned`字段会增加1,代表group中新插入了记录,直到group中的记录数量到达8
-- 当新纪录被插入到的group中记录数大于8时,group中的记录被分为2个group,一个group包含4条记录,另一个group包含5条记录。该过程将会向page directory中新增一个新的slot
-- 当记录被删除时,slot最最大一条记录的`n_owned`将会减少1,当n_owned字段小于4时,会触发再平衡操作,平衡后的page directory满足上述要求
-
-page directory中的slots数量如page header中的`PAGE_N_DIR_SLOTS`所示。
-
-一旦innodb中页包含page directory后,其会通过二分查找快速的定位slot,并且从group中最小记录开始,通过`next_record`指针来遍历页中的记录列表。这样能够快速的定位记录位置。
-
-### File Trailer
-
-#### 完整性校验
-在innodb中,页的大小为16KB,可能和磁盘的扇区大小不同。通常磁盘的扇区大小为512字节,故而在写入一个页到磁盘中时,需要分32个扇区进行写入。
-
-在写入一个页时,可能会发生宕机场景,这时,一个页只写入了一部分,可能会发生脏写。此时,可以通过double write buffer机制对脏写的页进行恢复。
-
-在一个页被写入到磁盘中时,首先会被写入的是File Header的`FIL_PAGE_SPACE_OR_CHKSUM`,该部分是page的checksum。
-
-innodb设置了File Trailer部分来校验page是否被完全写入到磁盘中,File Trailer中只包含一个`FIL_PAGE_END_LSN`部分,占用8字节,前4字节代表该页的checksum值,后4字节和File Header中的`FIL_PAGE_LSN`相同,`代表最后一次修改该页关联的LSN位置`。将上述两个字段和File Header中的`FIL_PAGE_SPACE_OR_CHKSUM`和`FIL_PAGE_LSN`值进行比较,查看是否一致,从而保证页的完整性。
-
-默认情况下,在innodb每次从磁盘读取page时,都会检查页面的完整性。
-
-## 分区表
-innodb存储引擎支持分区功能,分区过程将一个表或索引分为多个更小、更可管理的部分。
-
-对于访问数据库的应用而言,逻辑上的一个表或索引,其物理上可能由多个物理分区组成,每个分区都是独立的对象,既可以独自进行处理,又可以作为一个更大对象的一部分进行处理。
-
-> mysql仅支持水平分区(将同一张表中的不同行记录分配到不同的物理文件中),并不支持垂直分区(将同一张表中的不同列分配到不同的物理文件中)。
-
-目前mysql支持如下几种类型的分区:
-- `RANGE`: 行数据基于一个给定连续区间的列值被放入分区
-- `LIST`: 和`RANGE`类似,但`LIST`分区面对的是更加离散的值
-- `HASH`: 根据用户自定义的表达式返回值来进行分区,返回值不能为负数
-- `KEY`:根据mysql提供的哈希函数来进行分区
-
-`不论创建何种类型的分区,如果表中存在唯一索引或主键,分区列必须是唯一索引的一个组成部分。`
-
-### partition keys & primary keys & unique keys
-对于分区表而言,`所有在partition expression中使用到的col,其必须被包含在分区表所有的唯一索引中`。
-
-> `所有唯一索引`中包含主键索引。
-
-正确建立分区表的声明示例如下:
-```sql
-CREATE TABLE t1 (
- col1 INT NOT NULL,
- col2 DATE NOT NULL,
- col3 INT NOT NULL,
- col4 INT NOT NULL,
- UNIQUE KEY (col1, col2, col3)
-)
-PARTITION BY HASH(col3)
-PARTITIONS 4;
-
-CREATE TABLE t2 (
- col1 INT NOT NULL,
- col2 DATE NOT NULL,
- col3 INT NOT NULL,
- col4 INT NOT NULL,
- UNIQUE KEY (col1, col3)
-)
-PARTITION BY HASH(col1 + col3)
-PARTITIONS 4;
-
-
-CREATE TABLE t7 (
- col1 INT NOT NULL,
- col2 DATE NOT NULL,
- col3 INT NOT NULL,
- col4 INT NOT NULL,
- PRIMARY KEY(col1, col2)
-)
-PARTITION BY HASH(col1 + YEAR(col2))
-PARTITIONS 4;
-
-CREATE TABLE t8 (
- col1 INT NOT NULL,
- col2 DATE NOT NULL,
- col3 INT NOT NULL,
- col4 INT NOT NULL,
- PRIMARY KEY(col1, col2, col4),
- UNIQUE KEY(col2, col1)
-)
-PARTITION BY HASH(col1 + YEAR(col2))
-PARTITIONS 4;
-
-
-create table t2_partition (
- col1 int ,
- col2 date,
- col3 int null,
- col4 int null,
- unique index `idx_t2_partition_cols` (col1, col2,col3),
- primary key (col2, col1)
-)
-partition by hash(col1)
-partitions 4;
-```
-#### 表中不存在唯一索引
-如果表中没有唯一索引(也未定义primary key),那么上述要求并不会生效,可以在partition expression中使用任意cols。
-
-#### 后续向分区表添加唯一索引
-如果想要向分区表中添加唯一索引,那么新增的唯一索引中必须包含partition expression中所有的列。
-
-#### 对非分区表进行分区
-可以参照如下示例对非分区表进行分区:
-```sql
-CREATE TABLE np_pk (
- id INT NOT NULL AUTO_INCREMENT,
- name VARCHAR(50),
- added DATE,
- PRIMARY KEY (id)
-);
-```
-可以按`id`进行分区
-```sql
-ALTER TABLE np_pk
- PARTITION BY HASH(id)
- PARTITIONS 4;
-```
-### 分区类型
-#### RANGE
-RANGE为较常见的分区类型,如下示例为创建RANGE类型分区表的示例:
-```sql
-create table t1 (
- id bigint auto_increment not null,
- tran_date datetime(6) not null default now(6) on update now(6),
- primary key (id, tran_date)
-) engine=innodb
-partition by range (year(tran_date)) (
- partition part_y_let_2024 values less than (2025),
- partition part_y_eq_2025 values less than (2026)
- );
-```
-上述创建了表`t1`,t1主键为`(id, tran_date)`,且按照`tran_date`字段的年部分进行分区,分区类型为RANGE。
-
-表t1的分区为两部分,分区1为`tran_date位于2024或之前年份`的分区`part_y_let_2024`,分区2是`tran_date位于2025年`的分区`part_y_eq_2025`。
-
-##### information_schema.partitions
-如果要查看表的分区情况,可以查询`information_schema.partitions`表,示例如下
-```sql
-select * from information_schema.partitions where table_schema = 'learn_innodb' and table_name = 't1';
-```
-查询结果如下所示:
-| TABLE\_CATALOG | TABLE\_SCHEMA | TABLE\_NAME | PARTITION\_NAME | SUBPARTITION\_NAME | PARTITION\_ORDINAL\_POSITION | SUBPARTITION\_ORDINAL\_POSITION | PARTITION\_METHOD | SUBPARTITION\_METHOD | PARTITION\_EXPRESSION | SUBPARTITION\_EXPRESSION | PARTITION\_DESCRIPTION | TABLE\_ROWS | AVG\_ROW\_LENGTH | DATA\_LENGTH | MAX\_DATA\_LENGTH | INDEX\_LENGTH | DATA\_FREE | CREATE\_TIME | UPDATE\_TIME | CHECK\_TIME | CHECKSUM | PARTITION\_COMMENT | NODEGROUP | TABLESPACE\_NAME |
-| :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- |
-| def | learn\_innodb | t1 | part\_y\_eq\_2025 | null | 2 | null | RANGE | null | year\(\`tran\_date\`\) | null | 2026 | 0 | 0 | 16384 | 0 | 0 | 0 | 2025-02-08 01:05:53 | null | null | null | | default | null |
-| def | learn\_innodb | t1 | part\_y\_let\_2024 | null | 1 | null | RANGE | null | year\(\`tran\_date\`\) | null | 2025 | 0 | 0 | 16384 | 0 | 0 | 0 | 2025-02-08 01:05:53 | null | null | null | | default | null |
-
-为分区表预置如下数据
-```sql
-insert into t1(tran_date) values ('2023-01-01'), ('2024-12-31'), ('2025-01-01');
-```
-可以看到分区表中数据分布如下:
-```sql
-select partition_name, table_rows from information_schema.partitions where table_schema = 'learn_innodb' and table_name = 't1';
-```
-| PARTITION\_NAME | TABLE\_ROWS |
-| :--- | :--- |
-| part\_y\_eq\_2025 | 1 |
-| part\_y\_let\_2024 | 2 |
-
-易知`('2023-01-01'), ('2024-12-31')`数据位于`part_y_let_2024`分区,故而该分区存在两条数据;而`('2025-01-01')`数据位于`part_y_let_2024`分区,该分区存在一条数据。
-
-##### 看select语句查询了哪些分区
-数据分布可以通过如下方式验证:
-```sql
-explain select * from t1 where tran_date >= '2023-01-01' and tran_date <= '2024-12-31';
-```
-| id | select\_type | table | partitions | type | possible\_keys | key | key\_len | ref | rows | filtered | Extra |
-| :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- |
-| 1 | SIMPLE | t1 | part\_y\_let\_2024 | index | PRIMARY | PRIMARY | 16 | null | 2 | 50 | Using where; Using index |
-
-```sql
-explain select * from t1 where tran_date >= '2025-01-01'
-```
-| id | select\_type | table | partitions | type | possible\_keys | key | key\_len | ref | rows | filtered | Extra |
-| :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- |
-| 1 | SIMPLE | t1 | part\_y\_eq\_2025 | index | PRIMARY | PRIMARY | 16 | null | 1 | 100 | Using where; Using index |
-
-##### 插入超过分区范围的数据
-如果尝试向分区表中插入超过所有分区范围的数据,会执行失败,示例如下:
-```sql
-insert into t1(tran_date) values ('2026-01-01');
-```
-由于分区表`t1`中现有分区最大只支持2025年的分区,故而当尝试插入2026年分区时,会抛出如下错误:
-```bash
-[2025-02-08 01:32:51] [HY000][1526] Table has no partition for value 2026
-```
-##### 向分区表中添加分区
-mysql支持向分区表中添加分区,语法如下
-```sql
-alter table t1 add partition (
- partition part_year_egt_2026 values less than maxvalue
- );
-```
-添加分区后,mysql支持`tran_date大于等于2026`的分区,执行如下语句
-```sql
-insert into t1(tran_date) values ('2026-01-01'), ('2027-12-31'), ('2028-01-01');
-```
-之后,再次分区分区中的数据分区,结果如下
-| PARTITION\_NAME | TABLE\_ROWS |
-| :--- | :--- |
-| part\_y\_eq\_2025 | 1 |
-| part\_y\_let\_2024 | 2 |
-| part\_year\_egt\_2026 | 3 |
-
-> `information.partitions`表中,`table_rows`字段可能存在不准确的情况,如果想要获取准确的值,需要执行`analyze table {schema}.{table_name}`语句
-
-##### 向分区表中删除分区
-当想要删除分区表中现存分区时,可以通过执行如下语句
-```sql
-alter table t1 drop partition part_year_egt_2026;
-```
-在删除分区后,分区中的数据也会被删除,执行查询语句后
-```sql
-select * from t1;
-
-```
-可知`part_year_egt_2026`被删除后分区中数据全部消失
-| id | tran\_date |
-| :--- | :--- |
-| 1 | 2023-01-01 00:00:00.000000 |
-| 2 | 2024-12-31 00:00:00.000000 |
-| 3 | 2025-01-01 00:00:00.000000 |
-
-#### LIST
-LIST分区类型和RANGE分区类型非常相似,但是LIST分区列的值是离散的,RANGE分区列的值是连续的。
-
-创建LIST类型分区表的示例如下:
-```sql
-create table p_list_t1 (
- id bigint not null auto_increment,
- area smallint not null,
- primary key (id, area)
-)
-partition by list (area) (
- partition p_ch_beijing values in (1),
- partition p_ch_hubei values in (2),
- partition p_ch_jilin values in (3)
- );
-```
-之后可向`p_list_t1`表中预置数据,执行语句如下:
-```sql
-insert into p_list_t1(area) values (1),(1), (2), (3), (3);
-```
-此时,数据分布如下:
-| PARTITION\_METHOD | PARTITION\_NAME | TABLE\_ROWS |
-| :--- | :--- | :--- |
-| LIST | p\_ch\_beijing | 2 |
-| LIST | p\_ch\_hubei | 1 |
-| LIST | p\_ch\_jilin | 2 |
-
-如果想要向分区表中插入不位于现存分区中的值,那么插入语句同样会执行失败,示例如下
-```sql
-insert into p_list_t1(area) values (4);
-```
-由于目前没有area为4的分区,故而插入语句执行失败,报错如下
-```bash
-[2025-02-09 20:30:03] [HY000][1526] Table has no partition for value 4
-```
-
-#### HASH
-HASH分区方式是将数据均匀分布到预先定义的各个分区中,期望各个分区中散列的数据数量大致相同。
-
-在通过hash来进行分区时,建表时需要指定一个分区表达式,该表达式返回整数。
-
-创建hash分区的示例如下:
-```sql
-create table p_hash_t1 (
- id bigint not null auto_increment,
- content varchar(256),
- primary key (id)
-)
-partition by hash (id)
-partitions 4;
-```
-上述ddl创建了一个按照`id`列进行hash分区的分区表,分区表包含4个分区。
-
-预置数据sql如下:
-```sql
-insert into p_hash_t1(content) values ('asahi'), ('maki'), ('katahara');
-```
-预置数据后数据分布如下
-| PARTITION\_METHOD | PARTITION\_NAME | TABLE\_ROWS |
-| :--- | :--- | :--- |
-| HASH | p0 | 0 |
-| HASH | p1 | 1 |
-| HASH | p2 | 1 |
-| HASH | p3 | 1 |
-
-预置的三条数据id分别为`1, 2, 3`,被hash放置到分区`p1, p2, p3`中。
-
-> 当使用hash分区方式时,例如存在`4`个分区,对于待插入数据其分区表达式的值为`2`,那么待插入数据将会被插入到`2%4 = 2`,第`3`个分区中(0,1,2分区,排第三),也就是`p2`。
->
-> 可以通过`explain select * from p_hash_t1 where id = 2;`语句来进行验证,得到如下结果。
->
-> | id | select\_type | table | partitions | type | possible\_keys | key | key\_len | ref | rows | filtered | Extra |
-> | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- |
-> | 1 | SIMPLE | p\_hash\_t1 | p2 | const | PRIMARY | PRIMARY | 8 | const | 1 | 100 | null |
-
-
-##### 新增HASH分区
-对于hash分区方式,可以通过如下方式来新增分区:
-```sql
-alter table p_hash_t1 add partition partitions 3;
-```
-其会新增3个分区,执行后分区数量为7。
-
-此时,原本分区中的数据会被重新散列到新分区中
-
-##### 减少HASH分区
-对于hash分区,在尝试减少分区数量的同时,通常不希望删除任何数据,故而无法使用`drop`。
-
-故而,可以使用`coalesce`,其只会减少分区数量,不会删除数据。
-
-示例如下:
-```sql
-alter table p_hash_t1 coalesce partition 4;
-```
-上述语句会将分区数量减少4个,故而减少后分区数量为`3`。
-
-
-#### LINEAR HASH
-创建linear hash分区表的方式和hash类似,可以通过如下方式
-```sql
-create table p_linear_hash_t1 (
- id bigint not null auto_increment,
- content varchar(256),
- primary key(id)
-)
-partition by linear hash (id)
-partitions 5;
-```
-相较于hash分区,在使用linear hash分区时,添加、删除、合并、拆分分区将会变得更加快捷,但是相比于hash分区,其数据分区可能会不太均匀。
-
-#### KEY & LINEAR KEY
-KEY分区方式和HASH分区方式类似,但是HASH分区采用用户自定义的函数进行分区,而KEY分区方式则是采用mysql提供的函数进行分区。
-
-创建key分区表的示例如下:
-```sql
-create table p_key_t1 (
- id bigint not null auto_increment,
- content varchar(256),
- primary key(id)
-)
-partition by key(id)
-partitions 5;
-```
-> key分区方式同样可以使用linear进行修饰,效果和hash分区方式类似。
-
-> 对于key分区,可以指定除了integer之外的col类型,而`range, list, hash`等分区类型只支持integer类型的col。
-
-
-#### COLUMNS
-COLUMNS分区方式为`RANGE`和`LIST`分区的变体。
-
-COLUMNS分区方式支持在分区时使用多个列,在插入新数据或查询数据决定分区时,所有的列都会被考虑。
-
-COLUMNS分区方式分为如下两种
-- RANGE COLUMNS
-- LIST COLUMNS
-
-上述两种方式都支持非整数类型的列,COLUMNS支持的数据类型如下:
-- 所有integers类型(DECIMAL, FLOAT则不受支持)
-- DATE和DATETIME类型
-- 字符串类型:CHAR, VARCHAR, BINARY, VARBINARY(TEXT, BLOB类型不受支持)
-
-##### range columns
-创建range columns分区表的示例如下:
-```sql
-create table p_range_columns_t1 (
- id bigint not null auto_increment,
- name varchar(256),
- born_ts datetime(6),
- primary key (id, born_ts)
-)
-partition by range columns (born_ts) (
- partition p0 values less than ('1900-01-01'),
- partition p1 values less than ('2000-01-01'),
- partition p2 values less than ('2999-01-01')
- );
-```
-
-##### list columns
-创建list columns分区表的示例则如下:
-```sql
-create table p_list_columns_t1 (
- id bigint not null auto_increment,
- province varchar(256),
- city varchar(256),
- primary key (id, province, city)
-)
-partition by list columns (province, city) (
- partition p_beijing values in (('china', 'beijing')),
- partition p_wuhan values in (('hubei', 'wuhan'))
- );
-```
-
-> 通过range columns和list columns,可以很好的替代range和list分区,而无需将列值都转换为整型。
-
-### 子分区
-`子分区`代表在分区的基础上再次进行分区,mysql允许`在range和list分区的基础`上再次进行`hash或key`的子分区,示例如下:
-```sql
-create table p_list_columns_t1 (
- id bigint not null auto_increment,
- province varchar(256),
- city varchar(256),
- primary key (id, province, city)
-)
-partition by list columns (province, city)
-subpartition by key(id)
-subpartitions 3
-(
- partition p_beijing values in (('china', 'beijing')),
- partition p_wuhan values in (('hubei', 'wuhan'))
-);
-```
-上述示例先按照`list columns`分区方式进行了分区,然后在为每个分区都按`key`分了三个子分区,查看分区和子分区详情可以通过如下语句:
-```sql
-select partition_name, partition_method, subpartition_name, subpartition_method from information_schema.partitions where table_name = 'p_list_columns_t1';
-```
-| PARTITION\_NAME | PARTITION\_METHOD | SUBPARTITION\_NAME | SUBPARTITION\_METHOD |
-| :--- | :--- | :--- | :--- |
-| p\_wuhan | LIST COLUMNS | p\_wuhansp0 | KEY |
-| p\_wuhan | LIST COLUMNS | p\_wuhansp1 | KEY |
-| p\_wuhan | LIST COLUMNS | p\_wuhansp2 | KEY |
-| p\_beijing | LIST COLUMNS | p\_beijingsp0 | KEY |
-| p\_beijing | LIST COLUMNS | p\_beijingsp1 | KEY |
-| p\_beijing | LIST COLUMNS | p\_beijingsp2 | KEY |
-
-### 分区中的NULL值
-mysql允许对null值做分区,但`mysql数据库中的分区总是视null值小于任何非null的值`,该逻辑`和order by处理null值的逻辑一致`。
-
-故而,在使用不同的分区类型时,对于null值的处理逻辑如下:
-- 对于range类型分区,当插入null值时,其会被放在最左侧的分区中
-- 对于list类型的分区,如果要插入null值,必须在分区的`values in (...)`表达式中指定null值,否则插入语句将会报错
-- hash和key的分区类型,将会将null值当作`0`来散列
-
-### 分区和性能
-对于OLTP类型的应用,使用分区表时应该相当小心,因为分区表可能会带来严重的性能问题。
-
-例如,对于包含1000w条数据的表`t`,如果包含主键索引`id`和非主键索引`code`,分区和不分区,其性能分析如下
-
-#### 不分区
-如果不对表t进行分区,那么根据`id`(唯一主键索引)或`code`(非unique索引)进行查询,例如`select * from t where id = xxx`或`select * from t where code = xxx`时,可能只会进行2~3次磁盘io(1000w数据构成的B+树其层高为2~3)。
-
-#### 按id进行分区
-如果对表`t`按照`id`进行`hash`分区,分为10个分区,那么:
-- 对于按`id`进行查找的语句`select * from t where id = xxx`
- - 将t按id分为10个区后,如果分区均匀,那么每个分区数据大概为100w,对分区的查询开销大概为2次磁盘io
- - 根据`id`的查询只会在一个分区内进行查找,故而磁盘io会从3次减少为2次,可以提升查询效率
-- 对于按`code`进行查找的语句`select * from t where code = xxx`
- - 对于按code进行查找的语句,需要扫描所有的10个分区,每个分区大概需要2次磁盘io,故而总共的磁盘io大约为20次
-
-> 在使用分区表时,应尽量小心,不正确的使用分区将可能会带来大量的io,造成性能瓶颈
-
-### 在表和分区之间交换数据
-mysql支持在表分区和非分区表之间交换数据:
-- 在非分区表为空的场景下,相当于将分区中的数据移动到非分区表中
-- 在表分区为空的场景下,相当于将非分区表中的数据移动到表分区中
-
-在表和分区之间交换数据,可以通过`alter table ... exchange partition`语句,且必须满足如下条件:
-- 要交换的非分区表和分区表必须要拥有相同的结构,但是,非分区表中不能够含有分区
-- 非分区表中的数据都要位于表分区的范围内
-- 被交换的表中不能含有外键,或是其他表含有被交换表的外键引用
-- 用户需要拥有`alter, insert, create, drop`权限
-- 使用`alter table ... exchange parition`语句时,不会触发交换表和被交换表上的触发器
-- `auto_increment`将会被重置
-
-`exchange partition ... with table`的示例如下:
-```sql
-alter table p_range_columns_t exchange partition p_2024 with table np_t
-```
+- [表](#表)
+ - [索引组织表](#索引组织表)
+ - [innodb逻辑存储结构](#innodb逻辑存储结构)
+ - [表空间](#表空间)
+ - [innodb\_file\_per\_table](#innodb_file_per_table)
+ - [段(segment)](#段segment)
+ - [区(Extent)](#区extent)
+ - [页(Page)](#页page)
+ - [行](#行)
+ - [innodb行记录格式](#innodb行记录格式)
+ - [Compact](#compact)
+ - [变长字段长度列表](#变长字段长度列表)
+ - [NULL标志位](#null标志位)
+ - [记录头信息](#记录头信息)
+ - [行溢出数据](#行溢出数据)
+ - [dynamic](#dynamic)
+ - [char存储结构](#char存储结构)
+ - [innodb数据页结构](#innodb数据页结构)
+ - [File Header](#file-header)
+ - [Infimum和Supremum record](#infimum和supremum-record)
+ - [user record 和 free space](#user-record-和-free-space)
+ - [page directory](#page-directory)
+ - [B+树索引](#b树索引)
+ - [File Trailer](#file-trailer)
+ - [完整性校验](#完整性校验)
+ - [分区表](#分区表)
+ - [partition keys \& primary keys \& unique keys](#partition-keys--primary-keys--unique-keys)
+ - [表中不存在唯一索引](#表中不存在唯一索引)
+ - [后续向分区表添加唯一索引](#后续向分区表添加唯一索引)
+ - [对非分区表进行分区](#对非分区表进行分区)
+ - [分区类型](#分区类型)
+ - [RANGE](#range)
+ - [information\_schema.partitions](#information_schemapartitions)
+ - [看select语句查询了哪些分区](#看select语句查询了哪些分区)
+ - [插入超过分区范围的数据](#插入超过分区范围的数据)
+ - [向分区表中添加分区](#向分区表中添加分区)
+ - [向分区表中删除分区](#向分区表中删除分区)
+ - [LIST](#list)
+ - [HASH](#hash)
+ - [新增HASH分区](#新增hash分区)
+ - [减少HASH分区](#减少hash分区)
+ - [LINEAR HASH](#linear-hash)
+ - [KEY \& LINEAR KEY](#key--linear-key)
+ - [COLUMNS](#columns)
+ - [range columns](#range-columns)
+ - [list columns](#list-columns)
+ - [子分区](#子分区)
+ - [分区中的NULL值](#分区中的null值)
+ - [分区和性能](#分区和性能)
+ - [不分区](#不分区)
+ - [按id进行分区](#按id进行分区)
+ - [在表和分区之间交换数据](#在表和分区之间交换数据)
+
+
+# 表
+## 索引组织表
+innodb存储引擎中,表都是根据主键顺序组织存放的,这种存储方式被称为索引组织表(index organized table)。在innodb存储引擎表中,每张表都有主键(primary key),如果在创建表时没有显式指定主键,那么innodb会按照如下方式创建主键:
+- 首先判断表中是否存在非空的唯一索引(unique not null)字段,如果有,则其为主键
+- 如果不存在非空唯一索引,那么innodb会自动创建一个6字节大小的指针作为主键
+
+如果有多个非空唯一索引,innodb存储引擎将会选择第一个定义的非空唯一索引作为主键。
+
+## innodb逻辑存储结构
+在innodb的存储逻辑结构中,所有的数据都被逻辑存放在表空间(table space)中。表空间则由`段(segement),区(extent),页(page)`组成。
+
+组成如图所示:
+
+
+
+### 表空间
+表空间为innodb存储引擎逻辑结构的最高层,所有数据都存放于表空间中。innodb存在一个默认的共享表空间`ibdata1`,在开启`innodb_file_per_table`参数后,每张表内的数据可以单独存放到一个表空间。
+
+#### innodb_file_per_table
+`innodb_file_per_table`参数启用会导致每张表的`数据、索引、插入缓冲bitmap页`存放到单独的文件中;但是其他数据,例如`回滚(undo)信息,插入缓冲页,系统事务信息,double write buffer`等还是存放在默认的共享表空间中。
+
+### 段(segment)
+如上图所示,表空间是由段(segment)所组成的,常见的段分为`数据段,索引段,回滚段`等。
+
+在innodb存储引擎中,数据即索引,索引即数据。`数据段即为B+树的叶子节点(Leaf node segment)`,`索引段即为B+树的非叶子节点(Non-leaf node segment)`。
+
+### 区(Extent)
+区是由连续页组成的空间,在任何情况下每个区的大小都为1MB。为了保证区中页的连续性,innodb存储引擎会一次性从磁盘申请4~5个区。在默认情况下,innodb存储引擎中页的大小为`16KB`,一个区中包含64个页。
+
+在新建表时,新建表的大小为96KB,小于一个Extent的大小1MB,因为每个段Segmenet开始时,都会有至多32个页大小的碎片页,等使用完这些页后才会申请64个连续页作为Extent。
+
+都与一些小表或是undo这样的段,可以在开始时申请较少的空间,节省磁盘容量开销。
+
+### 页(Page)
+innodb存储引擎中页的大小默认为`16KB`,默认的页大小可以通过`innodb_page_size`参数进行修改。通过该参数,可以将innodb的默认页大小设置为4K,8K。
+
+页是innodb磁盘管理的最小单位,在innodb中,常见的页有:
+- 数据页(B-tree node)
+- undo页(undo log page)
+- 系统页(system page)
+- 事务数据页(transaction system page)
+- 插入缓冲位图页(insert buffer bitmap)
+- 插入缓冲空闲列表页(insert buffer free list)
+- 未压缩的二进制大对象页(uncompressed blob page)
+- 压缩的二进制大对象页(compressed blob page)
+
+### 行
+innodb存储引擎是面向行的,数据按行进行存放。每个页中至多可以存放`16KB/2 - 200`行的记录,即7992行记录。
+
+## innodb行记录格式
+innodb存储引擎以行的形式进行存储,可以通过`show table status like '{table_name}'`的语句来查询表的行格式,示例如下:
+```sql
+show table status like 'demo_t1'
+```
+
+| Name | Engine | Version | Row\_format | Rows | Avg\_row\_length | Data\_length | Max\_data\_length | Index\_length | Data\_free | Auto\_increment | Create\_time | Update\_time | Check\_time | Collation | Checksum | Create\_options | Comment |
+| :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- |
+| demo\_t1 | InnoDB | 10 | Dynamic | 0 | 0 | 16384 | 0 | 32768 | 0 | 1 | 2025-01-30 15:18:57 | null | null | utf8mb4\_0900\_ai\_ci | null | | |
+
+上述示例中表的row_format为dynamic。
+
+### Compact
+在使用Compact行记录格式时,一个页中存放数据越多,其性能越高。
+
+Compact格式下行记录的存储格式如下:
+
+
+ | 变长字段长度列表 |
+ NULL标志位 |
+ 记录头信息 |
+ 列1数据 |
+ 列2数据 |
+ ...... |
+
+
+
+
+#### 变长字段长度列表
+Compact行记录格式其首部是一个`非Null变长字段长度`列表,其按照列的顺序逆序放置,变长列的长度为:
+- 如果列的长度小于255字节,用1字节表示
+- 如果列的长度大于255字节,用2个字节表示
+
+变长字段的长度不能小于2字节,因为varchar类型最长长度限制为65535。
+
+#### NULL标志位
+NULL标志位为bitmap,代表每一列是否为空。如果行中存在n个字段可为空,那么NULL标志位部分的长度为ceiling(n/8)。
+
+#### 记录头信息
+record header,固定占用5字节,其中,record header的各bit含义如下所示:
+| 名称 | 大小(bit) | |
+| :-: | :-: | :-: |
+| () | 1 | 未知 |
+| () | 1 | 未知 |
+| deleted_flag | 1 | 该行是否已经被删除 |
+| min_rec_flag | 1 | 该行是否为预订被定义的最小记录行 |
+| n_owned | 4 | 该记录拥有的记录数 |
+| heap_no | 13 | 索引堆中该条记录的排序记录 |
+| record_type | 3 | 记录类型,000代表普通,001代表B+树节点指针, 010代表infimum,011代表supremum,1xx保留 |
+| next_record | 16 | 页中下一条记录相对位置 |
+
+除了上述3个部分之外,其他部分就是各个列的实际值。
+
+> 在Compact格式中,NULL除了占有NULL标志位外,不占用任何实际空间。
+
+> 每行数据中,除了有用户自定义的列外,还存在两个隐藏列,即`事务id列`和`回滚指针列`,长度分别为6字节和7字节。
+>
+> 如果innodb表没有自定义主键,每行还会增加一个rowid列。
+
+### 行溢出数据
+innodb存储引擎可能将一条记录中某些数据存储在真正的存储数据页面之外。一般来说,blob、lob这类大对象的存储位于数据页面之外。
+
+当行数据的大小特别大,导致一个页无法存放2条行数据时,innodb会自动将占用空间大的`blob`字段或`varchar`字段值放到额外的uncompressed blob page中。
+
+### dynamic
+dynamic格式几乎和compact格式相同,但是对于每个blob字段,其存储只消耗20字节用于存储指针。
+
+而对于Compact格式,其会在blob格式中存储768字节的前缀字节。
+
+### char存储结构
+`char(n)`字段中n代表`字符长度`而非字节长度,故而在不同字符集下,char类型字段的内部存储可能不是定长的。
+
+例如,在utf8字符集下,`ab`和`我们`两个字符串,其字符数都是2个,但是`ab`其占用2字节,而`我们`占用4字节,即使同样是`char(2)`类型的字符串,其占用字节数量仍然有可能不同。
+
+## innodb数据页结构
+innodb中页是磁盘管理的最小结构,页类型为B-tree Node的页存放的即是表中行的实际数据。
+
+innodb数据页由如下7个部分组成:
+- File Header(文件头)
+- Page Header(页头)
+- Infimum和Supremum Records
+- user records(用户记录,即行记录)
+- free space(空闲空间)
+- page directory(页目录)
+- file trailer(文件结尾信息)
+
+file header,page header,file trailer的大小是固定的,分别为38,56,8字节,这些空间用于标记页的一些信息,例如checksum,数据页所在B+树的层数等。
+
+
+
+### File Header
+File Header用于记录页的一些头信息,由8个部分组成,共占38字节:
+| 名称 | 大小 | 说明 |
+| :-: | :-: | :-: |
+| FIL_PAGE_SPACE_OR_CHKSUM | 4 | 代表页的checksum值 |
+| FIL_PAGE_OFFSET | 4 | 表空间中页的偏移位置 |
+| FIL_PAGE_PREV | 4 | 当前页的上一个页,B+树决定叶子节点为双向列表 |
+| FIL_PAGE_NEXT | 4 | 当前页的下一个页 |
+| FIL_PAGE_LSN | 8 | 代表该页最后被修改的日志序列位置LSN |
+| FIL_PAGE_TYPE | 2 | 存储引擎页类型 |
+| FIL_PAGE_FILE_FLUSH_LSN | 8 | 该值仅在系统表空间的一个页中定义,代表文件至少被更新到了该LSN值,对于独立的表空间,该值为0 |
+| FIL_PAGE_ARCH_LOG_NO_OR_SPACE_ID | 4 | 代表页属于哪个表空间 |
+
+### Infimum和Supremum record
+在innodb存储引擎中,每个数据页都有两行虚拟的行记录,用于限定记录边界。Infimum是比该页中所有主键值都要小的值,Supremum是比任何可能值都要大的值。`这两个值在页创建时被建立,并且在任何情况下都不会被删除。`
+
+### user record 和 free space
+user reocrd代表实际存储行记录中的内容,free space则是代表空闲空间,同样是链表数据结构,在一条记录被删除后,该空间会被加入到空闲列表中。
+
+### page directory
+page directory(页目录)中存放了记录的相对位置,这些记录指针被称为目录槽(directory slots)。`innodb中槽是一个稀疏目录,一个槽中可能包含多个记录`,记录Infimum的n_owned总为1,记录Supremum的n_owned取值范围为`[1,8]`,其他用户记录的n_owned为`[4,8]`。当记录被插入或删除时,需要对槽进行分裂或平衡的维护操作。
+
+在slots中,记录按照索引键值顺序存放,可以通过二叉查询迅速找到记录的指针。
+
+由于在innodb存储引擎中,page directory是稀疏目录,二叉查找结果只是一个粗略的结果,innodb存储引擎必须通过record header中的next_record来继续查找相关记录。
+
+#### B+树索引
+
+如上图所示,innodb中的数据是按照索引来进行组织的。但是,通过B+树索引,其无法直接查询到指定的记录,其只能查询到记录所位于的页。
+
+例如,在上图示例中,其在查询`ID=32`的时,只能查询到该记录位于page 17中。
+
+> 在B+树的叶子节点,每个页的File Header中都存有指向前一个页和后一个页的指针,`故而每个页之间是通过双向列表结构来维护的`;但是对于页中的记录,`记录与记录之间维维护的时单向列表的关系`。
+>
+> 对于Compact或Dynamic行格式的页,其每条记录的record header中都包含一个next_record字段指向下一条记录。故而,位于同一个页中的记录可以单向访问。
+
+但是,在一个页内查找某条记录时,沿着单向链表进行查找其效率很低。故而,page中的数据时机被分为了多个组,被分为的组构成了一个subdirectory,故而,通过子目录能够缩小查询范围,提高查询性能。
+
+page directory是一个能够存储多个slots的部分,每个slot中存储了group中最后一条记录的相对位置。假设slot中最大一条记录为`r`,那么group中记录的条数被存储在`r`记录record header的`n_owned`字段中。
+
+group中record的数量约束如下:
+- infimum group中records数量限制为`[1,8]`
+- supremum group中records数量限制为`[1,8]`
+- 其他group中records限制为`[4,8]`
+
+page directory生成过程如下所示:
+- 最开始时,页中只有infimum和supremum两条记录,它们分别属于两个group。page directory中有两个slots指向这两条记录,两个slot的n_owned都为1
+- 后续,当新的记录被插入页时,系统会查找page directory中主键值大于待插入记录的第一个slot。slot对应最大记录的`n_owned`字段会增加1,代表group中新插入了记录,直到group中的记录数量到达8
+- 当新纪录被插入到的group中记录数大于8时,group中的记录被分为2个group,一个group包含4条记录,另一个group包含5条记录。该过程将会向page directory中新增一个新的slot
+- 当记录被删除时,slot最最大一条记录的`n_owned`将会减少1,当n_owned字段小于4时,会触发再平衡操作,平衡后的page directory满足上述要求
+
+page directory中的slots数量如page header中的`PAGE_N_DIR_SLOTS`所示。
+
+一旦innodb中页包含page directory后,其会通过二分查找快速的定位slot,并且从group中最小记录开始,通过`next_record`指针来遍历页中的记录列表。这样能够快速的定位记录位置。
+
+### File Trailer
+
+#### 完整性校验
+在innodb中,页的大小为16KB,可能和磁盘的扇区大小不同。通常磁盘的扇区大小为512字节,故而在写入一个页到磁盘中时,需要分32个扇区进行写入。
+
+在写入一个页时,可能会发生宕机场景,这时,一个页只写入了一部分,可能会发生脏写。此时,可以通过double write buffer机制对脏写的页进行恢复。
+
+在一个页被写入到磁盘中时,首先会被写入的是File Header的`FIL_PAGE_SPACE_OR_CHKSUM`,该部分是page的checksum。
+
+innodb设置了File Trailer部分来校验page是否被完全写入到磁盘中,File Trailer中只包含一个`FIL_PAGE_END_LSN`部分,占用8字节,前4字节代表该页的checksum值,后4字节和File Header中的`FIL_PAGE_LSN`相同,`代表最后一次修改该页关联的LSN位置`。将上述两个字段和File Header中的`FIL_PAGE_SPACE_OR_CHKSUM`和`FIL_PAGE_LSN`值进行比较,查看是否一致,从而保证页的完整性。
+
+默认情况下,在innodb每次从磁盘读取page时,都会检查页面的完整性。
+
+## 分区表
+innodb存储引擎支持分区功能,分区过程将一个表或索引分为多个更小、更可管理的部分。
+
+对于访问数据库的应用而言,逻辑上的一个表或索引,其物理上可能由多个物理分区组成,每个分区都是独立的对象,既可以独自进行处理,又可以作为一个更大对象的一部分进行处理。
+
+> mysql仅支持水平分区(将同一张表中的不同行记录分配到不同的物理文件中),并不支持垂直分区(将同一张表中的不同列分配到不同的物理文件中)。
+
+目前mysql支持如下几种类型的分区:
+- `RANGE`: 行数据基于一个给定连续区间的列值被放入分区
+- `LIST`: 和`RANGE`类似,但`LIST`分区面对的是更加离散的值
+- `HASH`: 根据用户自定义的表达式返回值来进行分区,返回值不能为负数
+- `KEY`:根据mysql提供的哈希函数来进行分区
+
+`不论创建何种类型的分区,如果表中存在唯一索引或主键,分区列必须是唯一索引的一个组成部分。`
+
+### partition keys & primary keys & unique keys
+对于分区表而言,`所有在partition expression中使用到的col,其必须被包含在分区表所有的唯一索引中`。
+
+> `所有唯一索引`中包含主键索引。
+
+正确建立分区表的声明示例如下:
+```sql
+CREATE TABLE t1 (
+ col1 INT NOT NULL,
+ col2 DATE NOT NULL,
+ col3 INT NOT NULL,
+ col4 INT NOT NULL,
+ UNIQUE KEY (col1, col2, col3)
+)
+PARTITION BY HASH(col3)
+PARTITIONS 4;
+
+CREATE TABLE t2 (
+ col1 INT NOT NULL,
+ col2 DATE NOT NULL,
+ col3 INT NOT NULL,
+ col4 INT NOT NULL,
+ UNIQUE KEY (col1, col3)
+)
+PARTITION BY HASH(col1 + col3)
+PARTITIONS 4;
+
+
+CREATE TABLE t7 (
+ col1 INT NOT NULL,
+ col2 DATE NOT NULL,
+ col3 INT NOT NULL,
+ col4 INT NOT NULL,
+ PRIMARY KEY(col1, col2)
+)
+PARTITION BY HASH(col1 + YEAR(col2))
+PARTITIONS 4;
+
+CREATE TABLE t8 (
+ col1 INT NOT NULL,
+ col2 DATE NOT NULL,
+ col3 INT NOT NULL,
+ col4 INT NOT NULL,
+ PRIMARY KEY(col1, col2, col4),
+ UNIQUE KEY(col2, col1)
+)
+PARTITION BY HASH(col1 + YEAR(col2))
+PARTITIONS 4;
+
+
+create table t2_partition (
+ col1 int ,
+ col2 date,
+ col3 int null,
+ col4 int null,
+ unique index `idx_t2_partition_cols` (col1, col2,col3),
+ primary key (col2, col1)
+)
+partition by hash(col1)
+partitions 4;
+```
+#### 表中不存在唯一索引
+如果表中没有唯一索引(也未定义primary key),那么上述要求并不会生效,可以在partition expression中使用任意cols。
+
+#### 后续向分区表添加唯一索引
+如果想要向分区表中添加唯一索引,那么新增的唯一索引中必须包含partition expression中所有的列。
+
+#### 对非分区表进行分区
+可以参照如下示例对非分区表进行分区:
+```sql
+CREATE TABLE np_pk (
+ id INT NOT NULL AUTO_INCREMENT,
+ name VARCHAR(50),
+ added DATE,
+ PRIMARY KEY (id)
+);
+```
+可以按`id`进行分区
+```sql
+ALTER TABLE np_pk
+ PARTITION BY HASH(id)
+ PARTITIONS 4;
+```
+### 分区类型
+#### RANGE
+RANGE为较常见的分区类型,如下示例为创建RANGE类型分区表的示例:
+```sql
+create table t1 (
+ id bigint auto_increment not null,
+ tran_date datetime(6) not null default now(6) on update now(6),
+ primary key (id, tran_date)
+) engine=innodb
+partition by range (year(tran_date)) (
+ partition part_y_let_2024 values less than (2025),
+ partition part_y_eq_2025 values less than (2026)
+ );
+```
+上述创建了表`t1`,t1主键为`(id, tran_date)`,且按照`tran_date`字段的年部分进行分区,分区类型为RANGE。
+
+表t1的分区为两部分,分区1为`tran_date位于2024或之前年份`的分区`part_y_let_2024`,分区2是`tran_date位于2025年`的分区`part_y_eq_2025`。
+
+##### information_schema.partitions
+如果要查看表的分区情况,可以查询`information_schema.partitions`表,示例如下
+```sql
+select * from information_schema.partitions where table_schema = 'learn_innodb' and table_name = 't1';
+```
+查询结果如下所示:
+| TABLE\_CATALOG | TABLE\_SCHEMA | TABLE\_NAME | PARTITION\_NAME | SUBPARTITION\_NAME | PARTITION\_ORDINAL\_POSITION | SUBPARTITION\_ORDINAL\_POSITION | PARTITION\_METHOD | SUBPARTITION\_METHOD | PARTITION\_EXPRESSION | SUBPARTITION\_EXPRESSION | PARTITION\_DESCRIPTION | TABLE\_ROWS | AVG\_ROW\_LENGTH | DATA\_LENGTH | MAX\_DATA\_LENGTH | INDEX\_LENGTH | DATA\_FREE | CREATE\_TIME | UPDATE\_TIME | CHECK\_TIME | CHECKSUM | PARTITION\_COMMENT | NODEGROUP | TABLESPACE\_NAME |
+| :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- |
+| def | learn\_innodb | t1 | part\_y\_eq\_2025 | null | 2 | null | RANGE | null | year\(\`tran\_date\`\) | null | 2026 | 0 | 0 | 16384 | 0 | 0 | 0 | 2025-02-08 01:05:53 | null | null | null | | default | null |
+| def | learn\_innodb | t1 | part\_y\_let\_2024 | null | 1 | null | RANGE | null | year\(\`tran\_date\`\) | null | 2025 | 0 | 0 | 16384 | 0 | 0 | 0 | 2025-02-08 01:05:53 | null | null | null | | default | null |
+
+为分区表预置如下数据
+```sql
+insert into t1(tran_date) values ('2023-01-01'), ('2024-12-31'), ('2025-01-01');
+```
+可以看到分区表中数据分布如下:
+```sql
+select partition_name, table_rows from information_schema.partitions where table_schema = 'learn_innodb' and table_name = 't1';
+```
+| PARTITION\_NAME | TABLE\_ROWS |
+| :--- | :--- |
+| part\_y\_eq\_2025 | 1 |
+| part\_y\_let\_2024 | 2 |
+
+易知`('2023-01-01'), ('2024-12-31')`数据位于`part_y_let_2024`分区,故而该分区存在两条数据;而`('2025-01-01')`数据位于`part_y_let_2024`分区,该分区存在一条数据。
+
+##### 看select语句查询了哪些分区
+数据分布可以通过如下方式验证:
+```sql
+explain select * from t1 where tran_date >= '2023-01-01' and tran_date <= '2024-12-31';
+```
+| id | select\_type | table | partitions | type | possible\_keys | key | key\_len | ref | rows | filtered | Extra |
+| :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- |
+| 1 | SIMPLE | t1 | part\_y\_let\_2024 | index | PRIMARY | PRIMARY | 16 | null | 2 | 50 | Using where; Using index |
+
+```sql
+explain select * from t1 where tran_date >= '2025-01-01'
+```
+| id | select\_type | table | partitions | type | possible\_keys | key | key\_len | ref | rows | filtered | Extra |
+| :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- |
+| 1 | SIMPLE | t1 | part\_y\_eq\_2025 | index | PRIMARY | PRIMARY | 16 | null | 1 | 100 | Using where; Using index |
+
+##### 插入超过分区范围的数据
+如果尝试向分区表中插入超过所有分区范围的数据,会执行失败,示例如下:
+```sql
+insert into t1(tran_date) values ('2026-01-01');
+```
+由于分区表`t1`中现有分区最大只支持2025年的分区,故而当尝试插入2026年分区时,会抛出如下错误:
+```bash
+[2025-02-08 01:32:51] [HY000][1526] Table has no partition for value 2026
+```
+##### 向分区表中添加分区
+mysql支持向分区表中添加分区,语法如下
+```sql
+alter table t1 add partition (
+ partition part_year_egt_2026 values less than maxvalue
+ );
+```
+添加分区后,mysql支持`tran_date大于等于2026`的分区,执行如下语句
+```sql
+insert into t1(tran_date) values ('2026-01-01'), ('2027-12-31'), ('2028-01-01');
+```
+之后,再次分区分区中的数据分区,结果如下
+| PARTITION\_NAME | TABLE\_ROWS |
+| :--- | :--- |
+| part\_y\_eq\_2025 | 1 |
+| part\_y\_let\_2024 | 2 |
+| part\_year\_egt\_2026 | 3 |
+
+> `information.partitions`表中,`table_rows`字段可能存在不准确的情况,如果想要获取准确的值,需要执行`analyze table {schema}.{table_name}`语句
+
+##### 向分区表中删除分区
+当想要删除分区表中现存分区时,可以通过执行如下语句
+```sql
+alter table t1 drop partition part_year_egt_2026;
+```
+在删除分区后,分区中的数据也会被删除,执行查询语句后
+```sql
+select * from t1;
+
+```
+可知`part_year_egt_2026`被删除后分区中数据全部消失
+| id | tran\_date |
+| :--- | :--- |
+| 1 | 2023-01-01 00:00:00.000000 |
+| 2 | 2024-12-31 00:00:00.000000 |
+| 3 | 2025-01-01 00:00:00.000000 |
+
+#### LIST
+LIST分区类型和RANGE分区类型非常相似,但是LIST分区列的值是离散的,RANGE分区列的值是连续的。
+
+创建LIST类型分区表的示例如下:
+```sql
+create table p_list_t1 (
+ id bigint not null auto_increment,
+ area smallint not null,
+ primary key (id, area)
+)
+partition by list (area) (
+ partition p_ch_beijing values in (1),
+ partition p_ch_hubei values in (2),
+ partition p_ch_jilin values in (3)
+ );
+```
+之后可向`p_list_t1`表中预置数据,执行语句如下:
+```sql
+insert into p_list_t1(area) values (1),(1), (2), (3), (3);
+```
+此时,数据分布如下:
+| PARTITION\_METHOD | PARTITION\_NAME | TABLE\_ROWS |
+| :--- | :--- | :--- |
+| LIST | p\_ch\_beijing | 2 |
+| LIST | p\_ch\_hubei | 1 |
+| LIST | p\_ch\_jilin | 2 |
+
+如果想要向分区表中插入不位于现存分区中的值,那么插入语句同样会执行失败,示例如下
+```sql
+insert into p_list_t1(area) values (4);
+```
+由于目前没有area为4的分区,故而插入语句执行失败,报错如下
+```bash
+[2025-02-09 20:30:03] [HY000][1526] Table has no partition for value 4
+```
+
+#### HASH
+HASH分区方式是将数据均匀分布到预先定义的各个分区中,期望各个分区中散列的数据数量大致相同。
+
+在通过hash来进行分区时,建表时需要指定一个分区表达式,该表达式返回整数。
+
+创建hash分区的示例如下:
+```sql
+create table p_hash_t1 (
+ id bigint not null auto_increment,
+ content varchar(256),
+ primary key (id)
+)
+partition by hash (id)
+partitions 4;
+```
+上述ddl创建了一个按照`id`列进行hash分区的分区表,分区表包含4个分区。
+
+预置数据sql如下:
+```sql
+insert into p_hash_t1(content) values ('asahi'), ('maki'), ('katahara');
+```
+预置数据后数据分布如下
+| PARTITION\_METHOD | PARTITION\_NAME | TABLE\_ROWS |
+| :--- | :--- | :--- |
+| HASH | p0 | 0 |
+| HASH | p1 | 1 |
+| HASH | p2 | 1 |
+| HASH | p3 | 1 |
+
+预置的三条数据id分别为`1, 2, 3`,被hash放置到分区`p1, p2, p3`中。
+
+> 当使用hash分区方式时,例如存在`4`个分区,对于待插入数据其分区表达式的值为`2`,那么待插入数据将会被插入到`2%4 = 2`,第`3`个分区中(0,1,2分区,排第三),也就是`p2`。
+>
+> 可以通过`explain select * from p_hash_t1 where id = 2;`语句来进行验证,得到如下结果。
+>
+> | id | select\_type | table | partitions | type | possible\_keys | key | key\_len | ref | rows | filtered | Extra |
+> | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- |
+> | 1 | SIMPLE | p\_hash\_t1 | p2 | const | PRIMARY | PRIMARY | 8 | const | 1 | 100 | null |
+
+
+##### 新增HASH分区
+对于hash分区方式,可以通过如下方式来新增分区:
+```sql
+alter table p_hash_t1 add partition partitions 3;
+```
+其会新增3个分区,执行后分区数量为7。
+
+此时,原本分区中的数据会被重新散列到新分区中
+
+##### 减少HASH分区
+对于hash分区,在尝试减少分区数量的同时,通常不希望删除任何数据,故而无法使用`drop`。
+
+故而,可以使用`coalesce`,其只会减少分区数量,不会删除数据。
+
+示例如下:
+```sql
+alter table p_hash_t1 coalesce partition 4;
+```
+上述语句会将分区数量减少4个,故而减少后分区数量为`3`。
+
+
+#### LINEAR HASH
+创建linear hash分区表的方式和hash类似,可以通过如下方式
+```sql
+create table p_linear_hash_t1 (
+ id bigint not null auto_increment,
+ content varchar(256),
+ primary key(id)
+)
+partition by linear hash (id)
+partitions 5;
+```
+相较于hash分区,在使用linear hash分区时,添加、删除、合并、拆分分区将会变得更加快捷,但是相比于hash分区,其数据分区可能会不太均匀。
+
+#### KEY & LINEAR KEY
+KEY分区方式和HASH分区方式类似,但是HASH分区采用用户自定义的函数进行分区,而KEY分区方式则是采用mysql提供的函数进行分区。
+
+创建key分区表的示例如下:
+```sql
+create table p_key_t1 (
+ id bigint not null auto_increment,
+ content varchar(256),
+ primary key(id)
+)
+partition by key(id)
+partitions 5;
+```
+> key分区方式同样可以使用linear进行修饰,效果和hash分区方式类似。
+
+> 对于key分区,可以指定除了integer之外的col类型,而`range, list, hash`等分区类型只支持integer类型的col。
+
+
+#### COLUMNS
+COLUMNS分区方式为`RANGE`和`LIST`分区的变体。
+
+COLUMNS分区方式支持在分区时使用多个列,在插入新数据或查询数据决定分区时,所有的列都会被考虑。
+
+COLUMNS分区方式分为如下两种
+- RANGE COLUMNS
+- LIST COLUMNS
+
+上述两种方式都支持非整数类型的列,COLUMNS支持的数据类型如下:
+- 所有integers类型(DECIMAL, FLOAT则不受支持)
+- DATE和DATETIME类型
+- 字符串类型:CHAR, VARCHAR, BINARY, VARBINARY(TEXT, BLOB类型不受支持)
+
+##### range columns
+创建range columns分区表的示例如下:
+```sql
+create table p_range_columns_t1 (
+ id bigint not null auto_increment,
+ name varchar(256),
+ born_ts datetime(6),
+ primary key (id, born_ts)
+)
+partition by range columns (born_ts) (
+ partition p0 values less than ('1900-01-01'),
+ partition p1 values less than ('2000-01-01'),
+ partition p2 values less than ('2999-01-01')
+ );
+```
+
+##### list columns
+创建list columns分区表的示例则如下:
+```sql
+create table p_list_columns_t1 (
+ id bigint not null auto_increment,
+ province varchar(256),
+ city varchar(256),
+ primary key (id, province, city)
+)
+partition by list columns (province, city) (
+ partition p_beijing values in (('china', 'beijing')),
+ partition p_wuhan values in (('hubei', 'wuhan'))
+ );
+```
+
+> 通过range columns和list columns,可以很好的替代range和list分区,而无需将列值都转换为整型。
+
+### 子分区
+`子分区`代表在分区的基础上再次进行分区,mysql允许`在range和list分区的基础`上再次进行`hash或key`的子分区,示例如下:
+```sql
+create table p_list_columns_t1 (
+ id bigint not null auto_increment,
+ province varchar(256),
+ city varchar(256),
+ primary key (id, province, city)
+)
+partition by list columns (province, city)
+subpartition by key(id)
+subpartitions 3
+(
+ partition p_beijing values in (('china', 'beijing')),
+ partition p_wuhan values in (('hubei', 'wuhan'))
+);
+```
+上述示例先按照`list columns`分区方式进行了分区,然后在为每个分区都按`key`分了三个子分区,查看分区和子分区详情可以通过如下语句:
+```sql
+select partition_name, partition_method, subpartition_name, subpartition_method from information_schema.partitions where table_name = 'p_list_columns_t1';
+```
+| PARTITION\_NAME | PARTITION\_METHOD | SUBPARTITION\_NAME | SUBPARTITION\_METHOD |
+| :--- | :--- | :--- | :--- |
+| p\_wuhan | LIST COLUMNS | p\_wuhansp0 | KEY |
+| p\_wuhan | LIST COLUMNS | p\_wuhansp1 | KEY |
+| p\_wuhan | LIST COLUMNS | p\_wuhansp2 | KEY |
+| p\_beijing | LIST COLUMNS | p\_beijingsp0 | KEY |
+| p\_beijing | LIST COLUMNS | p\_beijingsp1 | KEY |
+| p\_beijing | LIST COLUMNS | p\_beijingsp2 | KEY |
+
+### 分区中的NULL值
+mysql允许对null值做分区,但`mysql数据库中的分区总是视null值小于任何非null的值`,该逻辑`和order by处理null值的逻辑一致`。
+
+故而,在使用不同的分区类型时,对于null值的处理逻辑如下:
+- 对于range类型分区,当插入null值时,其会被放在最左侧的分区中
+- 对于list类型的分区,如果要插入null值,必须在分区的`values in (...)`表达式中指定null值,否则插入语句将会报错
+- hash和key的分区类型,将会将null值当作`0`来散列
+
+### 分区和性能
+对于OLTP类型的应用,使用分区表时应该相当小心,因为分区表可能会带来严重的性能问题。
+
+例如,对于包含1000w条数据的表`t`,如果包含主键索引`id`和非主键索引`code`,分区和不分区,其性能分析如下
+
+#### 不分区
+如果不对表t进行分区,那么根据`id`(唯一主键索引)或`code`(非unique索引)进行查询,例如`select * from t where id = xxx`或`select * from t where code = xxx`时,可能只会进行2~3次磁盘io(1000w数据构成的B+树其层高为2~3)。
+
+#### 按id进行分区
+如果对表`t`按照`id`进行`hash`分区,分为10个分区,那么:
+- 对于按`id`进行查找的语句`select * from t where id = xxx`
+ - 将t按id分为10个区后,如果分区均匀,那么每个分区数据大概为100w,对分区的查询开销大概为2次磁盘io
+ - 根据`id`的查询只会在一个分区内进行查找,故而磁盘io会从3次减少为2次,可以提升查询效率
+- 对于按`code`进行查找的语句`select * from t where code = xxx`
+ - 对于按code进行查找的语句,需要扫描所有的10个分区,每个分区大概需要2次磁盘io,故而总共的磁盘io大约为20次
+
+> 在使用分区表时,应尽量小心,不正确的使用分区将可能会带来大量的io,造成性能瓶颈
+
+### 在表和分区之间交换数据
+mysql支持在表分区和非分区表之间交换数据:
+- 在非分区表为空的场景下,相当于将分区中的数据移动到非分区表中
+- 在表分区为空的场景下,相当于将非分区表中的数据移动到表分区中
+
+在表和分区之间交换数据,可以通过`alter table ... exchange partition`语句,且必须满足如下条件:
+- 要交换的非分区表和分区表必须要拥有相同的结构,但是,非分区表中不能够含有分区
+- 非分区表中的数据都要位于表分区的范围内
+- 被交换的表中不能含有外键,或是其他表含有被交换表的外键引用
+- 用户需要拥有`alter, insert, create, drop`权限
+- 使用`alter table ... exchange parition`语句时,不会触发交换表和被交换表上的触发器
+- `auto_increment`将会被重置
+
+`exchange partition ... with table`的示例如下:
+```sql
+alter table p_range_columns_t exchange partition p_2024 with table np_t
+```
diff --git a/mysql/mysql集群/CAP Theorem in DBMS.md b/mysql/mysql集群/CAP Theorem in DBMS.md
index cd6d6f3..3b58cb7 100644
--- a/mysql/mysql集群/CAP Theorem in DBMS.md
+++ b/mysql/mysql集群/CAP Theorem in DBMS.md
@@ -1,80 +1,80 @@
-- [CAP Theorem in DBMS](#cap-theorem-in-dbms)
- - [What is the CAP Theorem](#what-is-the-cap-theorem)
- - [Consistency](#consistency)
- - [Availability](#availability)
- - [Partition Tolerance](#partition-tolerance)
- - [The Trade-Offs in the CAP Theorem](#the-trade-offs-in-the-cap-theorem)
- - [CA(Consistency and Availability)](#caconsistency-and-availability)
- - [AP(Availability and Partition Tolerance)](#apavailability-and-partition-tolerance)
- - [CP(Consistency and Partition Tolerance)](#cpconsistency-and-partition-tolerance)
-
-# CAP Theorem in DBMS
-在网络共享数据系统设计中固有的权衡令构建一个可靠且高效的系统十分困难。CAP理论是理解分布式系统中这些权衡的核心基础。CAP理论强调了系统设计者在处理distributed data replication时的局限性。CAP理论指出,在分布式系统中,只能同时满足`一致性、可用性、分区容错`这三个特性中的两种。
-
-> CAP理论中,对分布式系统提出了如下三个特性:
-> - consistency(一致性)
-> - availability(可用性)
-> - partition tolerance(分区容错)
-
-由于该底层限制,开发者必须根据其应用的需要谨慎的平衡这些属性。设计者必须决定优先考虑哪些特性,从而获取最佳的性能和系统可靠性。
-
-## What is the CAP Theorem
-CAP理论是分布式系统的基础概念,其指出分布式系统中所有的三个特性无法被同时满足。
-
-### Consistency
-`Consistency`代表network中所有的节点都包含相同的replicated data拷贝,而这些数据对不同事务可见。其保证分布式居群中所有节点返回相同、最新的数据。其代表所有client对数据的视角都相同。存在许多不同类型的一致性模型,而CAP中的一致性代指的是顺序一致性,是一种非常强的一致性形式。
-
-`ACID`和`CAP`中都包含一致性,但是这两种一致性所有不同:
-- 在`ACID`中,其代表事务不能破坏数据库的完整性约束
-- 在`CAP`中,其代表分布式系统中相同数据项在不同副本中的一致性
-
-### Availability
-Availability代表每个对数据项的read/write request要么能被成功处理,要么能收到一个操作无法被完成的响应。每个non-failing节点都会为所有读写请求在合理的时间范围内生成响应。
-
-其中,“每个节点”代表,即使发生network partition,节点只要不处于failing状态,无论位于network partition的哪一侧,都应该能在合理的时间范围内返回响应。
-
-### Partition Tolerance
-partition tolerance代表在连接节点的网络发生错误、造成两个或多个分区时,系统仍然能够继续进行操作。通常,在出现network partition时,每个partition中的节点只能彼此互相沟通,跨分区的节点通信被阻断。
-
-这意味着,即使发生network partition,系统仍然能持续运行并保证其一致性。network partition是不可避免地,在网络分区恢复正常后,拥有partition tolerance的分布式系统能够优雅的从分区状态中恢复。
-
-CAP理论指出分布式数据库最多只能兼顾如下三个特性中的两种:consistency, availability, partition tolerance。
-
- -
-## The Trade-Offs in the CAP Theorem
-CAP理论表明分布式系统中只能同时满足三种特性中的两种。
-### CA(Consistency and Availability)
-> 对于CA类型的系统,其总是可以接收来源于用户的查询和修改数据请求,并且分布式网络中所有database nodes都会返回相同的响应
-
-然而,该种类似的分布式系统在现实世界中不可能存在,因为在network failure发生时,仅有如下两种选项:
-- 发送network failure发生前复制的old data
-- 不允许用户访问old data
-
-如果我们选择第一个选项,那么系统将满足Availibility;如果选择第二个选项,系统则是Consistent。
-
-`在分布式系统中,consistency和availability的组合是不可能的`。为了实现`CA`,系统必须是单体架构,当用户更新系统状态时,所有其他用户都能访问到该更新,这将代表系统满足一致性;而在单体架构中,所有用户都连接到一个节点上,这代表其是可用的。`CA`系统通常不被青睐,因为实现分布式计算必须牺牲consistency或availability中的一种,并将剩余的和partition tolerance组合,即`CP/AP`系统。
-
-> CAP中的A(Availability)只是要求非failing状态下的节点能够在合理的时间范围内返回响应,故而单体架构可以满足`Availability`。
->
-> 即使单体架构可能因单点故障导致系统不可用,不满足`Reliable`(可靠性),并不影响其满足`Availability`(可用性)。
-
-
-
-## The Trade-Offs in the CAP Theorem
-CAP理论表明分布式系统中只能同时满足三种特性中的两种。
-### CA(Consistency and Availability)
-> 对于CA类型的系统,其总是可以接收来源于用户的查询和修改数据请求,并且分布式网络中所有database nodes都会返回相同的响应
-
-然而,该种类似的分布式系统在现实世界中不可能存在,因为在network failure发生时,仅有如下两种选项:
-- 发送network failure发生前复制的old data
-- 不允许用户访问old data
-
-如果我们选择第一个选项,那么系统将满足Availibility;如果选择第二个选项,系统则是Consistent。
-
-`在分布式系统中,consistency和availability的组合是不可能的`。为了实现`CA`,系统必须是单体架构,当用户更新系统状态时,所有其他用户都能访问到该更新,这将代表系统满足一致性;而在单体架构中,所有用户都连接到一个节点上,这代表其是可用的。`CA`系统通常不被青睐,因为实现分布式计算必须牺牲consistency或availability中的一种,并将剩余的和partition tolerance组合,即`CP/AP`系统。
-
-> CAP中的A(Availability)只是要求非failing状态下的节点能够在合理的时间范围内返回响应,故而单体架构可以满足`Availability`。
->
-> 即使单体架构可能因单点故障导致系统不可用,不满足`Reliable`(可靠性),并不影响其满足`Availability`(可用性)。
-
-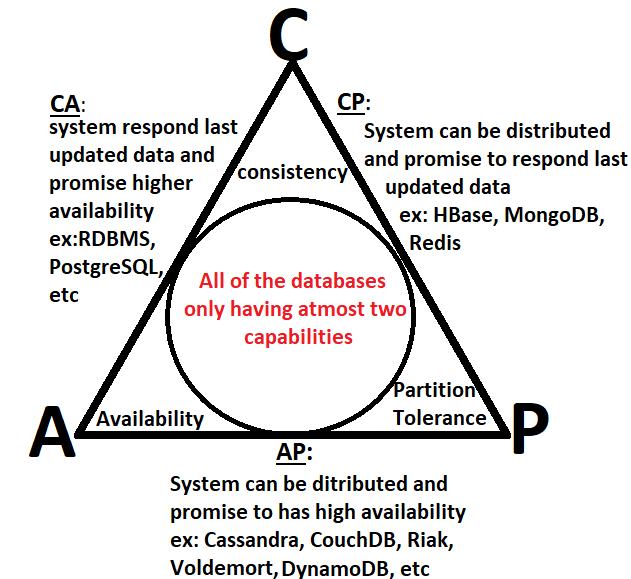 -
-### AP(Availability and Partition Tolerance)
-> 这种类型的系统本质上是分布式的,确保即使在network partition场景下,用户发送的针对database nodes中数据的查看和修改请求不会被丢失
-
-该系统优先考虑了Availability而非Consistency,并且可能会返回过期的数据。一些技术failure可能会导致partition,故而过期数据则是代表partition产生前被同步的数据。
-
-AP系统通常在构建社交媒体网站如Facebook和在线内容网站如YouTube时使用,其并不要求一致性。对于使用AP系统的场景,相比于不一致,不可用会造成更大的问题。
-
-AP系统是分布式的,可以分布于多个节点,即使在network partition发生的前提下也能够可靠运行。
-
-### CP(Consistency and Partition Tolerance)
-> 该类系统本质上是分布式的,确保由用户发起的针对database nodes中数据进行查看或修改的请求,在存在network partition的场景下,会直接被丢弃,而不是返回不一致的数据
-
-`CP`系统优先考虑了Consistency而非Availability,如果发生network partition,其不允许用户从replica读取`在network partition发生前同步的数据`。对于部分应用程序来说,相比于可用性,其更强调数据的一致性,例如股票交易系统、订票系统、银行系统等)
-
-例如,在订票系统中,还剩余一个可订购座位。在该CP系统中,将会创建数据库的副本,并且将副本发送给系统中其他的节点。此时,如果发生网络问题,那么连接到partitioned node的用户将会从replica获取数据。此时,其他连接到unpartitioned部分的用户则可以对剩余的作为进行预定。这样,在连接到partitioned node的用户视角中,仍然存在一个seat,其将导致数据不一致。
-
+- [CAP Theorem in DBMS](#cap-theorem-in-dbms)
+ - [What is the CAP Theorem](#what-is-the-cap-theorem)
+ - [Consistency](#consistency)
+ - [Availability](#availability)
+ - [Partition Tolerance](#partition-tolerance)
+ - [The Trade-Offs in the CAP Theorem](#the-trade-offs-in-the-cap-theorem)
+ - [CA(Consistency and Availability)](#caconsistency-and-availability)
+ - [AP(Availability and Partition Tolerance)](#apavailability-and-partition-tolerance)
+ - [CP(Consistency and Partition Tolerance)](#cpconsistency-and-partition-tolerance)
+
+# CAP Theorem in DBMS
+在网络共享数据系统设计中固有的权衡令构建一个可靠且高效的系统十分困难。CAP理论是理解分布式系统中这些权衡的核心基础。CAP理论强调了系统设计者在处理distributed data replication时的局限性。CAP理论指出,在分布式系统中,只能同时满足`一致性、可用性、分区容错`这三个特性中的两种。
+
+> CAP理论中,对分布式系统提出了如下三个特性:
+> - consistency(一致性)
+> - availability(可用性)
+> - partition tolerance(分区容错)
+
+由于该底层限制,开发者必须根据其应用的需要谨慎的平衡这些属性。设计者必须决定优先考虑哪些特性,从而获取最佳的性能和系统可靠性。
+
+## What is the CAP Theorem
+CAP理论是分布式系统的基础概念,其指出分布式系统中所有的三个特性无法被同时满足。
+
+### Consistency
+`Consistency`代表network中所有的节点都包含相同的replicated data拷贝,而这些数据对不同事务可见。其保证分布式居群中所有节点返回相同、最新的数据。其代表所有client对数据的视角都相同。存在许多不同类型的一致性模型,而CAP中的一致性代指的是顺序一致性,是一种非常强的一致性形式。
+
+`ACID`和`CAP`中都包含一致性,但是这两种一致性所有不同:
+- 在`ACID`中,其代表事务不能破坏数据库的完整性约束
+- 在`CAP`中,其代表分布式系统中相同数据项在不同副本中的一致性
+
+### Availability
+Availability代表每个对数据项的read/write request要么能被成功处理,要么能收到一个操作无法被完成的响应。每个non-failing节点都会为所有读写请求在合理的时间范围内生成响应。
+
+其中,“每个节点”代表,即使发生network partition,节点只要不处于failing状态,无论位于network partition的哪一侧,都应该能在合理的时间范围内返回响应。
+
+### Partition Tolerance
+partition tolerance代表在连接节点的网络发生错误、造成两个或多个分区时,系统仍然能够继续进行操作。通常,在出现network partition时,每个partition中的节点只能彼此互相沟通,跨分区的节点通信被阻断。
+
+这意味着,即使发生network partition,系统仍然能持续运行并保证其一致性。network partition是不可避免地,在网络分区恢复正常后,拥有partition tolerance的分布式系统能够优雅的从分区状态中恢复。
+
+CAP理论指出分布式数据库最多只能兼顾如下三个特性中的两种:consistency, availability, partition tolerance。
+
+
+
+## The Trade-Offs in the CAP Theorem
+CAP理论表明分布式系统中只能同时满足三种特性中的两种。
+### CA(Consistency and Availability)
+> 对于CA类型的系统,其总是可以接收来源于用户的查询和修改数据请求,并且分布式网络中所有database nodes都会返回相同的响应
+
+然而,该种类似的分布式系统在现实世界中不可能存在,因为在network failure发生时,仅有如下两种选项:
+- 发送network failure发生前复制的old data
+- 不允许用户访问old data
+
+如果我们选择第一个选项,那么系统将满足Availibility;如果选择第二个选项,系统则是Consistent。
+
+`在分布式系统中,consistency和availability的组合是不可能的`。为了实现`CA`,系统必须是单体架构,当用户更新系统状态时,所有其他用户都能访问到该更新,这将代表系统满足一致性;而在单体架构中,所有用户都连接到一个节点上,这代表其是可用的。`CA`系统通常不被青睐,因为实现分布式计算必须牺牲consistency或availability中的一种,并将剩余的和partition tolerance组合,即`CP/AP`系统。
+
+> CAP中的A(Availability)只是要求非failing状态下的节点能够在合理的时间范围内返回响应,故而单体架构可以满足`Availability`。
+>
+> 即使单体架构可能因单点故障导致系统不可用,不满足`Reliable`(可靠性),并不影响其满足`Availability`(可用性)。
+
+
+
+### AP(Availability and Partition Tolerance)
+> 这种类型的系统本质上是分布式的,确保即使在network partition场景下,用户发送的针对database nodes中数据的查看和修改请求不会被丢失
+
+该系统优先考虑了Availability而非Consistency,并且可能会返回过期的数据。一些技术failure可能会导致partition,故而过期数据则是代表partition产生前被同步的数据。
+
+AP系统通常在构建社交媒体网站如Facebook和在线内容网站如YouTube时使用,其并不要求一致性。对于使用AP系统的场景,相比于不一致,不可用会造成更大的问题。
+
+AP系统是分布式的,可以分布于多个节点,即使在network partition发生的前提下也能够可靠运行。
+
+### CP(Consistency and Partition Tolerance)
+> 该类系统本质上是分布式的,确保由用户发起的针对database nodes中数据进行查看或修改的请求,在存在network partition的场景下,会直接被丢弃,而不是返回不一致的数据
+
+`CP`系统优先考虑了Consistency而非Availability,如果发生network partition,其不允许用户从replica读取`在network partition发生前同步的数据`。对于部分应用程序来说,相比于可用性,其更强调数据的一致性,例如股票交易系统、订票系统、银行系统等)
+
+例如,在订票系统中,还剩余一个可订购座位。在该CP系统中,将会创建数据库的副本,并且将副本发送给系统中其他的节点。此时,如果发生网络问题,那么连接到partitioned node的用户将会从replica获取数据。此时,其他连接到unpartitioned部分的用户则可以对剩余的作为进行预定。这样,在连接到partitioned node的用户视角中,仍然存在一个seat,其将导致数据不一致。
+
在上述场景下,CP系统通常会令其系统对`连接到partitioned node的用户`不可用。
\ No newline at end of file
diff --git a/mysql/mysql集群/Replication.md b/mysql/mysql集群/Replication.md
index 7447a35..1f4d95f 100644
--- a/mysql/mysql集群/Replication.md
+++ b/mysql/mysql集群/Replication.md
@@ -1,355 +1,355 @@
-- [Replication](#replication)
- - [Configuration Replication](#configuration-replication)
- - [binary log file position based replication configuration overview](#binary-log-file-position-based-replication-configuration-overview)
- - [Replication with Global Transaction Identifiers](#replication-with-global-transaction-identifiers)
- - [GTID Format and Storage](#gtid-format-and-storage)
- - [GTID Sets](#gtid-sets)
- - [msyql.gtid\_executed](#msyqlgtid_executed)
- - [mysql.gtid\_executed table compression](#mysqlgtid_executed-table-compression)
- - [GTID生命周期](#gtid生命周期)
- - [What changes are assign a GTID](#what-changes-are-assign-a-gtid)
- - [Replication Implementation](#replication-implementation)
- - [Replication Formats](#replication-formats)
- - [使用statement-based和row-based replication的优缺点对比](#使用statement-based和row-based-replication的优缺点对比)
- - [Advantages of statement-based replication](#advantages-of-statement-based-replication)
- - [Disadvantages of statement-based replication](#disadvantages-of-statement-based-replication)
- - [Advantages of row-based replication](#advantages-of-row-based-replication)
- - [disadvantages of row-based replication](#disadvantages-of-row-based-replication)
- - [Replay Log and Replication Metadata Repositories](#replay-log-and-replication-metadata-repositories)
- - [The Relay Log](#the-relay-log)
-
-# Replication
-Replication允许数据从一个database server被复制到一个或多个mysql database servers(replicas)。replication默认是异步的;replicas并无需永久连接即可接收来自source的更新。基于configuration,可以针对所有的databases、选定的databases、甚至database中指定的tables进行replicate。
-
-mysql中replication包含如下优点:
-- 可拓展方案:可以将负载分散到多个replicas,从而提升性能。在该环境中,所有的writes和updates都发生在source server。但是,reads则是可以发生在一个或多个replicas上。通过该模型,能够提升writes的性能(因为source专门用于更新),并可以通过增加replicas的数量来提高read speed
-- data security: 因为replica可以暂停replication过程,故而可以在replica中运行备份服务,而不会破坏对应的source data
-- analytics:实时数据可以在source中生成,而对信息的分析则可以发生在replica,分析过程不会影响source的性能
-- long-distance data distribution:可以replication来对remote site创建一个local copy,而无需对source的永久访问
-
-在mysql 8.4中,支持不同的replication方式。
-- 传统方式基于从source的binary log中复制事件,并且需要log files和`在source和replica之间进行同步的position`。
-- 新的replication方式基于global transaction identifiers(GTIDs),是事务的,并且不需要和log files、position进行交互,其大大简化了许多通用的replication任务。使用GTIDs的replication保证了source和replica的一致性,所有在source提交的事务都会在replica被应用。
-
-mysql中的replication支持不同类型的同步。
-- 原始的同步是单向、异步的复制,一个server作为source、其他一个或多个servers作为replicas。
-- NDB Cluster中,支持synchronous replication
-- 在mysql 8.4中,支持了半同步复制,通过半同步复制,在source中执行的提交将会被阻塞,直到至少一个replica收到transaction并对transaction进行log event,且向source发送ack
-- mysql 8.4同样支持delayed replication,使得replica故意落后于source至少指定的时间
-
-## Configuration Replication
-### binary log file position based replication configuration overview
-在该section中,会描述mysql servers间基于binary log file position的replication方案。(source会将database的writes和updates操作以events的形式写入到binary log中)。根据database记录的变更,binary log中的信息将会以不同的logging format存储。replicas可以被配置,从source的binary log读取events,并且在replica本地的binary log中执行时间。
-
-每个replica都会接收binary log的完整副本内容,并由replica来决定binary log中哪些statements应当被执行。除非你显式指定,否则binary log中所有的events都会在replica上被执行。如果需要,你可以对replica进行配置,仅处理应用于特定databases、tables的events。
-
-每个replica都会记录二进制日志的坐标:其已经从source读取并处理的file name和文件中的position。这代表多个replicas可以连接到source,并执行相同binary log的不同部分。由于该过程受replicas控制,故而独立的replicas可以和source建立连接、取消连接,并且不会影响到source的操作。并且,每个replica记录了binary log的当前position,replica可以断开连接、重新连接并重启之前的过程。
-
-source和每个replica都配置了unique ID(使用`server_id` system variable),除此之外,每个replica必须配置如下信息:
-- source's host name
-- source's log file name
-- position of source's file
-
-这些可以在replica的mysql session内通过`CHANGE REPLICATION SOURCE TO`语句来管理,并且这些信息存储在replica的connection metadata repository中。
-
-### Replication with Global Transaction Identifiers
-在该章节中,描述了使用global transaction identifiers(GTIDs)的transaction-based replication。当使用GTIDs时,每个在source上提交的事务都可以被标识和追踪,并可以被任一replica应用。
-
-在使用GTIDs时,启动新replica或failover to a new source时并不需要参照log files或file position。由于GTIDs时完全transaction-based的,其更容易判断是否source和replicas一致,只要在source中提交的事务全部也都在replica上提交,那么source和replica则是保证一致的。
-
-在使用GTIDs时,可以选择是statement-based的还是row-based的,推荐使用row-based format。
-
-GTIDs在source和replica都是持久化的。总是可以通过检测binary log来判断是否source中的任一事务是否在replica上被应用。此外,一旦给定GTID的事务在给定server上被提交,那么后续任一事务如果拥有相同的GTID,其都会被server忽略。因此,在source上被提交的事务可以在replica上应用多次,冗余的应用会被忽略,其可以保证数据的一致性。
-
-#### GTID Format and Storage
-一个global transation identifier(GTID)是一个唯一标识符,该标识符的创建并和`source上提交的每一个事务`进行关联。GTID不仅在创建其的server上是唯一的,并且在给定replication拓扑的所有servers间是唯一的。
-
-GTID的分配区分了client trasactions(在source上提交的事务)以及replicated transactions(在replica上reproduced的事务)。当client transaction在source上提交时,如果transaction被写入到binary log中,其会被分配一个新的GTID。client transactions将会被保证单调递增,并且生成的编号之间不会存在间隙。`如果client transaction没有被写入到binary log,那么其在source中并不会被分配GTID`。
-
-Replicated transaction将会使用`事务被source server分配的GTID`。在replicated transaction开始执行前,GTID就已经存在,并且,即使replicated transaction没有写入到replica的binary log中或是被replica过滤,该GTID也会被持久化。`mysql.gtid_executed` system table将会被用于保存`应用到给定server的所有事务的GTID,但是,已经存储到当前active binary log file的除外`。
-
-> `active binary log file`中的gtid最终也会被写入到`gtid_executed`表中,但是,对于不同的存储引擎,写入时机可能不同。对于innodb而言,在事务提交时就会写入gtid_executed表,而对于其他存储引擎而言,则会在binary log发生rotation/server shutdown后才会将active binary log中尚未写入的GTIDs写入到`mysql.gtid_executed`表
-
-GTIDs的auto-skip功能代表一个在source上提交的事务最多只能在replica上应用一次,这有助于保证一致性。一旦拥有给定GTID的事务在给定server上被提交,任何后续执行的事务如果拥有相同的GTID,都会被server忽略。并不会抛出异常,并且事务中的statements都不会被实际执行。
-
-如果拥有给定GTID的事务在server上已经开始执行,但是尚未提交或回滚,那么任何尝试开启一个`拥有相同GTID事务的操作都会被阻塞`。该server并不会开始执行拥有相同GTID的事务,也不会将控制权交还给client。一旦第一个事务提交或回滚,那么被阻塞的事务就可以开始执行。如果第一次执行被回滚,那么被阻塞事务可以实际执行;如果第一个事务成功提交,那么被阻塞事务并不会被实际执行,而是会被自动跳过。
-
-GTID的表示形式如下:
-```
-GTID = source_id:transaction_id
-```
-- `source_id`表示了originating server,通常为source的`server_uuid`
-- `transaction_id`则是一个由`transaction在source上提交顺序`决定的序列号。例如,第一个被提交的事务,其transaction_id为1;而第十个被提交的事务,其transaction_id则是为10.
- - 在GTID中,transaction_id部分的值不可能为0
-
-例如,在UUID为`3E11FA47-71CA-11E1-9E33-C80AA9429562`上的server提交的第23个事务,其GTID为
-```
-3E11FA47-71CA-11E1-9E33-C80AA9429562:23
-```
-
-在GTID中,序列号的上限值为`2^63 - 1, or 9223372036854775807`(signed 64-bit integer)。如果server运行时超过GTIDs,其将执行`binlog_error_action`指定的行为。当server接近该限制时,会发出一个warning message。
-
-在mysql 8.4中,也支持tagged GTIDs,一个tagged GTID由三部分组成,通过`:`进行分隔,示例如下所示:
-```
-GTID = source_id:tag:transaction_id
-```
-
-在该示例中,`source_id`和`transaction_id`的含义和先前相同,`tag`则是一个用户自定义的字符串,用于表示`specific group of transactions`。
-
-例如,在UUID为`ed102faf-eb00-11eb-8f20-0c5415bfaa1d`的server上第117个提交的tag为`Domain_1`的事务,其GTID为
-```
-ed102faf-eb00-11eb-8f20-0c5415bfaa1d:Domain_1:117
-```
-
-事务的GTID会展示在`mysqlbinlog`的输出中,用于分辨`performance schema replication status tables`中独立的事务,例如`replication_applier_status_by_worker`表。
-
-`gtid_next` system variable的值是单个GTID。
-
-##### GTID Sets
-一个GTID set由`一个或多个GTIDs`或`GTIDs`范围构成。`gtid_executed`或`gtid_purged` system variables存储的就是GTID sets。`START REPLICA`选项`UNTIL SQL_BEFORE_GTIDS`和`UNTIL SQL_AFTER_GTIDS`可令replica在处理事务时,`最多只处理到GTID set中的第一个GTID`或`在处理完GTID set中的最后一个GTID后停止`。内置的`GTID_SUBSET()`和`GTID_SUBTRACT()`函数需要`GTID sets`作为输入。
-
-在相同server上的GTIDs范围可以按照如下形式来表示:
-```
-3E11FA47-71CA-11E1-9E33-C80AA9429562:1-5
-```
-上述示例表示在uuid为`3E11FA47-71CA-11E1-9E33-C80AA9429562`的server上提交的顺序为`1~5`之间的事务。
-
-相同server上的多个single GTIDs或ranges of GTIDs可以通过如下形式来表示
-```
-3E11FA47-71CA-11E1-9E33-C80AA9429562:1-3:11:47-49
-```
-
-GTID set可以包含任意`single GTIDs`和`GTIDs range`的组合,也可以包含来自不同server的GTIDs。如下实例中展示了`gtid_executed` system variable中存储的GTID set,代表replica中应用了来自超过一个source的事务:
-```
-2174B383-5441-11E8-B90A-C80AA9429562:1-3, 24DA167-0C0C-11E8-8442-00059A3C7B00:1-19
-```
-当GTID set从server variables中返回时,UUID按照字母排序返回,而序列号间区间则是合并后按照升序排列。
-
-当构建GTID set时,用户自定义tag也会被作为UUID的一部分,这代表来自相同server且tag相同的多个GTIDs可以被包含在一个表达式中,如下所示:
-```
-3E11FA47-71CA-11E1-9E33-C80AA9429562:Domain_1:1-3:11:47-49
-```
-来源相同server,但是tags不同的GTIDs表示方式如下:
-```
-3E11FA47-71CA-11E1-9E33-C80AA9429562:Domain_1:1-3:15-21, 3E11FA47-71CA-11E1-9E33-C80AA9429562:Domain_2:8-52
-```
-
-GTID set的完整语法如下所示:
-```
-gtid_set:
- uuid_set [, uuid_set] ...
- | ''
-
-uuid_set:
- uuid:[tag:]interval[:interval]...
-
-uuid:
- hhhhhhhh-hhhh-hhhh-hhhh-hhhhhhhhhhhh
-
-h:
- [0-9|A-F]
-
-tag:
- [a-z_][a-z0-9_]{0,31}
-
-interval:
- m[-n]
-
- (m >= 1; n > m)
-```
-##### msyql.gtid_executed
-GTIDs被存储在`mysql.gtid_executed`表中,该表中的行用于表示GTID或GTID set,行包含信息如下
-- source server的uuid
-- 用户自定义的tag
-- starting transaction IDs of the set
-- ending transaction IDs of the set
-
-如果行代表single GTID,那么最后两个字段的值相同。
-
-`mysql.gtid_executed`表在mysql server安装或升级时会被自动创建,其表结构如下:
-```sql
-CREATE TABLE gtid_executed (
- source_uuid CHAR(36) NOT NULL,
- interval_start BIGINT NOT NULL,
- interval_end BIGINT NOT NULL,
- gtid_tag CHAR(32) NOT NULL,
- PRIMARY KEY (source_uuid, gtid_tag, interval_start)
-);
-```
-
-`mysql.gtid_executed`用于mysql server内部使用,其允许replica在binary logging被禁用的情况下使用GTIDs,其也可以在binary logs丢失时保留GTID的状态。如果执行`RESET BINARY LOGS AND GTIDS`,那么`mysql.gtid_executed`表将会被清空。
-
-只有当`gtid_mode`被设置为`ON`或`ON_PERMISSIVE`时,GTIDs才会被存储到mysql.gtid_executed中。如果binary logging被禁用,或者`log_replica_updates`被禁用,server在事务提交时将会把属于个各事务的GTID和事务一起存储到buffer中,并且background threads将会周期性将buffer中的内容以entries的形式添加到`mysql.gtid_executed`表中。
-
-对于innodb存储引擎而言,如果binary logging被启用,server更新`mysql.gtid_executed`表的方式将会和`binary logging或replica update logging被启用`时一样,都会在每个事务提交时存储GTID。对于其他存储引擎,则是在binary log rotation发生时或server shut down时更新`mysql.gtid_executed`表的内容。
-
-如果mysql.gtid_executed表无法被写访问,并且binary log file因`reaching the maximum file size`之外的任何理由被rotated,那么current binary log file将仍被使用。并且,当client发起rotation时将会返回错误信息,并且server将会输出warning日志。如果`mysql.gtid_executed`无法被写访问,并且binary log单个文件大小达到`max_binlog_size`,那么server将会根据`binlog_error_action`设置来执行操作。如果`IGNORE_ERROR`被设置,那么server将会输出error到日志,并且binary logging将会被停止;如果`ABORT_SERVER`被设置,那么server将会shutdown。
-
-> 因为写入到active binary log的GTIDs最终也要被写入`mysql.gtid_executed`表,但是该表若当前不可写访问,那么此时将无法触发`binary log rotation`。
->
-> MySQL.gtid_executed中缺失的GTIDs必须包含在active binary log file中,如果log file触发rotation,但是无法向mysql.gtid_executed中写入数据,那么rotation是不被允许的。
-
-
-##### mysql.gtid_executed table compression
-随着时间的推移,mysql.gtid_executed表会填满大量行,行数据代表独立的GTID,示例如下:
-```
-+--------------------------------------+----------------+--------------+----------+
-| source_uuid | interval_start | interval_end | gtid_tag |
-|--------------------------------------+----------------+--------------|----------+
-| 3E11FA47-71CA-11E1-9E33-C80AA9429562 | 31 | 31 | Domain_1 |
-| 3E11FA47-71CA-11E1-9E33-C80AA9429562 | 32 | 32 | Domain_1 |
-| 3E11FA47-71CA-11E1-9E33-C80AA9429562 | 33 | 33 | Domain_1 |
-| 3E11FA47-71CA-11E1-9E33-C80AA9429562 | 34 | 34 | Domain_1 |
-| 3E11FA47-71CA-11E1-9E33-C80AA9429562 | 35 | 35 | Domain_1 |
-| 3E11FA47-71CA-11E1-9E33-C80AA9429562 | 36 | 36 | Domain_2 |
-| 3E11FA47-71CA-11E1-9E33-C80AA9429562 | 37 | 37 | Domain_2 |
-| 3E11FA47-71CA-11E1-9E33-C80AA9429562 | 38 | 38 | Domain_2 |
-| 3E11FA47-71CA-11E1-9E33-C80AA9429562 | 39 | 39 | Domain_2 |
-| 3E11FA47-71CA-11E1-9E33-C80AA9429562 | 40 | 40 | Domain_1 |
-| 3E11FA47-71CA-11E1-9E33-C80AA9429562 | 41 | 41 | Domain_1 |
-| 3E11FA47-71CA-11E1-9E33-C80AA9429562 | 42 | 42 | Domain_1 |
-| 3E11FA47-71CA-11E1-9E33-C80AA9429562 | 43 | 43 | Domain_1 |
-| 3E11FA47-71CA-11E1-9E33-C80AA9429562 | 44 | 44 | Domain_2 |
-| 3E11FA47-71CA-11E1-9E33-C80AA9429562 | 45 | 45 | Domain_2 |
-| 3E11FA47-71CA-11E1-9E33-C80AA9429562 | 46 | 46 | Domain_2 |
-| 3E11FA47-71CA-11E1-9E33-C80AA9429562 | 47 | 47 | Domain_1 |
-| 3E11FA47-71CA-11E1-9E33-C80AA9429562 | 48 | 48 | Domain_1 |
-```
-
-为了节省空间,可以对gtid_executed表周期性的进行压缩,将多个`single GTID`替换为单个`GTID set`,压缩后的数据如下;
-```
-+--------------------------------------+----------------+--------------+----------+
-| source_uuid | interval_start | interval_end | gtid_tag |
-|--------------------------------------+----------------+--------------|----------+
-| 3E11FA47-71CA-11E1-9E33-C80AA9429562 | 31 | 35 | Domain_1 |
-| 3E11FA47-71CA-11E1-9E33-C80AA9429562 | 36 | 39 | Domain_2 |
-| 3E11FA47-71CA-11E1-9E33-C80AA9429562 | 40 | 43 | Domain_1 |
-| 3E11FA47-71CA-11E1-9E33-C80AA9429562 | 44 | 46 | Domain_2 |
-| 3E11FA47-71CA-11E1-9E33-C80AA9429562 | 47 | 48 | Domain_1 |
-...
-```
-server可通过名为`thread/sql/compress_gtid_table`的前台线程来执行gtid_executed表的压缩操作,该线程并不会在`show processlist`的输出中被列出,但是可以通过查询`threads`表来查看,示例如下:
-```sql
-mysql> SELECT * FROM performance_schema.threads WHERE NAME LIKE '%gtid%'\G
-*************************** 1. row ***************************
- THREAD_ID: 26
- NAME: thread/sql/compress_gtid_table
- TYPE: FOREGROUND
- PROCESSLIST_ID: 1
- PROCESSLIST_USER: NULL
- PROCESSLIST_HOST: NULL
- PROCESSLIST_DB: NULL
-PROCESSLIST_COMMAND: Daemon
- PROCESSLIST_TIME: 1509
- PROCESSLIST_STATE: Suspending
- PROCESSLIST_INFO: NULL
- PARENT_THREAD_ID: 1
- ROLE: NULL
- INSTRUMENTED: YES
- HISTORY: YES
- CONNECTION_TYPE: NULL
- THREAD_OS_ID: 18677
-```
-当server启用了binary log时,上述压缩方式并不会被使用,`mysql.gtid_executed`在每次binary log rotation时会被压缩。但是,当binary logging被禁用时,`thread/sql/compress_gtid`线程处于sleep状态,每有一定数量的事务被执行时,线程会wake up并执行压缩操作。在table被压缩之前经过的事务数量,即压缩率,可由system variable `gtid_executed_compression_period`来进行控制。如果将值设置为0,代表该thread永远不会wake up。
-
-相比于其他存储引擎,innodb事务写入`mysql.gtid_executed`的过程有所不同,在innodb存储引擎中,过程通过线程`innodb/clone_gtid_thread`来执行。此GTID持久化线程将会分组收集GTIDs,并将其刷新到`mysql.gtid_executed`表中,并对table进行压缩。如果server中既包含innodb事务,又包含non-innodb事务,那么由`compress_gtid_table`线程执行的压缩操作将会干扰`clone_gtid_thread`的工作,并对其效率进行显著下降。为此,在此场景下更推荐将`gtid_executed_compression_period`设置为0,故而`compress_gtid_table`线程将永远不被激活。
-
-`gtid_executed_compression_period`的默认值为0,且所有事务不论其所属存储引擎,都会被`clone_gitid_thread`写入到`mysql.gtid_exec uted`中。
-
-当server实例启动后,如果`gtid_executed_compression_preiod`被设置为非0值,并且`compress_gtid_table`线程也启动,在多数server配置中,将会对`msyql.gtid_executed`表执行显式压缩。压缩通过线程的启动触发。
-
-#### GTID生命周期
-GTID生命周期由如下步骤组成:
-1. 事务在source上被执行并提交,client transaction将会被分配GTID,GTID由`source UUID`和`smallest nonzero transaction sequence number not yet used on this server`组成。GTID也会被写入到binary log中(在log中,GTID被写入在事务之前)。如果client transaction没有被写入binary log(例如,事务被过滤或事务为read-only),那么该事务不会被分配GTID
-2. 如果为事务分配了GTID,那么在事务提交时GTID会被原子的持久化。在binary log中,GTID会被写入到事务开始的位置。不管何时,如果binary log发生rotation或server shutdown,server会将所有写入到binary log file中事务的GTIDs写入到`mysql.gtid_executed`表中
-3. 如果为事务分配了GTID,那么GTID的外部化是`non-atomically`的(在事务提交后非常短的时间)。外部化过程会将GTID添加到`gtid_executed` system variable所代表的GTID set中(`@@GLOBAL.gtid_executed`)。该GTID set中包含`representation of the set of all committed GTID transactions`,并且在replication中会作为代表server state的token使用。
- 1. 当binary logging启用时,`gtid_executed` system variable代表的GTIDs set是已被应用事务的完整记录。但是`mysql.gtid_executed`表则并记录所有GTIDs,可能由部分GTIDs仍存在于active binary log file中尚未被写入到gtid_executed table
-4. 在binary log data被转移到replica并存储在replica的relay log中后,replica会读取GTID的值,并且将其设置到`gtid_next` system variable中。这告知replica下一个事务将会使用`gtid_next`所代表的GTID。replica在session context中设置`gtid_next`
-5. replica在处理事务前,会验证没有其他线程已经持有了`gtid_next`中GTID的所有权。通过该方法,replica可以保证该该GTID关联的事务在replica上没有被应用过,并且还能保证没有其他session已经读取该GTID但是尚未提交关联事务。故而,如果并发的尝试应用相同的事务,那么server只会让其中的一个运行。
- 1. replica的`gtid_owned` system variable(`@@GLOBAL.gtid_owned`)代表了当前正在使用的每个GTID和拥有该GTID的线程ID。如果GTID已经被使用过,并不会抛出错误,`auto-skip`功能会忽略该事务
-6. 如果GTID尚未被使用,那么replica将会对replicated transaction进行应用。因为`gtid_next`被设置为了`由source分配的GTID`,replica将不会尝试为事务分配新的GTID,而是直接使用存储在`gtid_next`中存储的GTID
-7. 如果replica上启用了binary logging,GTID将会在提交时被原子的持久化,写入到binary log中事务开始的位置。无论何时,如果binary log发生rotation或server shutdown,server会将`先前写入到binary log中事务的GTIDs`写入到`mysql.gtid_executed`表中
-8. 如果replica禁用binary log,GTID将会原子的被持久化,直接被写入到`mysql.gtid_executed`表中。mysql会向事务中追加一个statement,并且将GTID插入到table中该操作是原子的,在该场景下,`mysql.gtid_executed`表记录了完整的`transactions applied on the replica`。
-9. 在replicated transaction提交后很短的时间,GTID会被非原子的externalized,GTID会被添加到replica的`gtid_executed` system variable代表的GTIDs中。在source中,`gtid_executed` system variable包含了所有提交的GTID事务。
-
-在source上被完全过滤的client transactions并不会被分配GTID,因此其不会被添加到`gtid_executed` system variable或被添加到`mysql.gtid_executed`表中。然而,replicated transaction中的GTIDs即使在replica被完全过滤,也会被持久化。
-- 如果binary logging在replica开启,被过滤的事务将会作为gtid_log_event的形式被写入到binary log,后续跟着一个empty transaction,事务中仅包含BEGIN和COMMIT语句
-- 如果binary logging在replica被禁用,给过滤事务的GTID将会被写入到`mysql.gtid_executed`表
-
-将filtered-out transactions的GTIDs保留,可以确保`mysql.gtid_executed`表和`gtid_executed`system variable中的GTIDs可以被压缩。同时其也能确保replica重新连接到source时,filtered-out transactions不会被重新获取
-
-在多线程的replica上(`replica_parallel_workers > 0`),事务可以被并行的应用,故而replicated transactions可以以不同的顺序来提交(除非`replica_preserve_commit_order = 1`)。在并行提交时,`gtid_executed`system variable中的GTIDs将包含多个GTID ranges,多个范围之间存在空隙。在多线程replicas上,只有最近被应用的事务间才会存在空隙,并且会随着replication的进行而被填充。当replication threads通过`STOP REPLICA`停止时,这些空隙会被填补。当发生shutdown event时(server failure导致),此时replication 停止,空隙仍可能保留。
-
-##### What changes are assign a GTID
-GTID生成的典型场景为`server为提交事务生成新的GTID`。然而,GTIDs可以被分配给除事务外的其他修改,且在某些场景下一个事务可以被分配多个GTIDs。
-
-每个写入binary log的数据库修改(`DDL/DML`)都会被分配一个GTID。其包含了自动提交的变更、使用`BEGIN...COMMIT`的变更和使用`START TRANSACTION`的变更。一个GTID会被分配给数据库的`creation, alteration, deletion`操作,并且`non-table` database object例如`procedure, function, trigger, event, view, user, role, grant`的`creation, alteration, deletion`也会被分配GTID。
-
-非事务更新和事务更新都会被分配`GTID`,额外的,对于非事务更新,如果在尝试写入binary log cahche时发生disk write failure,导致binary log中出现间隙,那么生成的日志事件将会被分配一个GTID。
-
-## Replication Implementation
-在replication的设计中,source server会追踪其binary log中所有对databases的修改。binary log中记录了自server启动时所有修改数据库结构或内容的事件。通常,`SELECT`语句将不会被记录,其并没有对数据库结构或内容造成修改。
-
-每个连接到source的replica都会请求binary log的副本,replica会从source处拉取数据,而不是source向replica推送数据。replica也会执行其从binary log收到的事件。`发生在source上的修改将会在replica上进行重现`。在重现过程中,会发生表创建、表结构修改、数据的新增/删除/修改等操作。
-
-由于每个replica都是独立的,每个连接到source的replica,其对`source中binary log`内容的replaying都是独立的。此外,因为每个replica只通过请求source来接收binary log的拷贝,replica能够以其自身的节奏来读取和更新其数据副本,并且其能在不对source和其他replicas造成影响的条件下开启或停止replication过程。
-
-### Replication Formats
-在binary log中,events根据其事件类型以不同的格式被记录。replication使用的foramts取决于事件被记录到source server的binary log中时所使用的foramt。binary log format和replciation过程中使用到的format,其关联关系如下:
-- 当使用statement-based binary logging时,source会将sql statements写入到binary log。从source到replica的replication将会在replica上执行该sql语句。这被称之为statement-based replication,关联了mysql statement-based binary logging format
-- 当使用row-based loggging时,source将会将`table rows如何变更`的事件写入到binary log中。在replica中,将会重现events对table rows所做的修改。则会被成为row-based replication
- - `row-based logging`是默认的方法
-- 可以配置mysql使用`mix-format logging`,但使用`mix-format logging`时,将默认使用statement-based log。但是对于特定的语句,也取决于使用的存储引擎,在某些床惊吓log也会被自动切换到row-based。使用mixed format的replication被称之为mix-based replication或mix-format replication
-
-mysql server中的logging format通过`binlog_format` system variable来进行控制。该变量可以在session/global级别进行设置
-- 在将variable设置为session级别时,将仅会对当前session生效,并且仅持续到当前session结束
-- 将variable设置为global级别时,该设置将会对`clients that connect after the change`生效,`但对于any current client sessions,包括.发出该修改请求的session都不生效`
-
-#### 使用statement-based和row-based replication的优缺点对比
-每个binary logging format都有优缺点。对大多数users,mixed replication format能够提供性能和数据完整性的最佳组合。
-
-##### Advantages of statement-based replication
-- 在使用statement-based格式时,会向log files中写入更少的数据。特别是在更新或删除大量行时,使用statement-based格式能够导致更少的空间占用。在从备份中获取和恢复时,其速度也更快
-- log files包含所有造成修改的statements,可以被用于审核database
-
-##### Disadvantages of statement-based replication
-- 对于Statement-based replication而言,statements并不是安全的。并非所有对数据造成修改的statements都可以使用statement-based replication。在使用statement-based replication时,任何非确定性的行为都难以复制(例如在语句中包含随机函数等非确定性行为)
-- 对于复杂语句,statement必须在实际对目标行执行修改前重新计算。而当使用row-based replication时,replica可以直接修改受影响行,而无需重新计算
-
-##### Advantages of row-based replication
-- 所有的修改可以被replicated,其是最安全的replication形式
-
-##### disadvantages of row-based replication
-- 相比于statement-based replication,row-based replication通常会向log中ieur更多数据,特别是当statement操作大量行数据是
-- 在replica并无法查看从source接收并执行的statements。可以通过`mysqlbinlog`的`--base64-output=DECODE-ROWS`和`--verbose`选项来查看数据变更
-
-### Replay Log and Replication Metadata Repositories
-replica server会创建一系列仓库,其中存储在replication过程中使用的信息;
-- `relay log`: 该日志被replication I/O线程写入,包含从source server的binary log读取的事务。relay log中记录的事务将会被replication SQL thread应用到replica
-- `connection metadata repository`: 包含replication receiver thread连接到source server并从binary log获取事务时,需要的信息。connection metadata repository会被写入到`mysql.slave_master_info`中
-- `applier metadata repository`: 包含replication applier thread从relay log读取并应用事务时所需要的信息。applier metadata repository会被写入到`mysql.slave_relay_log_info`表中
-
-#### The Relay Log
-relay log和binary log类似,由一些`numbered files`构成,文件中包含`描述数据库变更的事件`。relay log还包含一个index file,其中记录了所有被使用的relay log files的名称。默认情况下,relay log files位于data directory中
-
-relay log files拥有和binary log相同的格式,也可以通过mysqlbinlog进行读取。如果使用了binary log transaction compression,那么写入relay log的事务payloads也会按照和binary log相同的方式被压缩。
-
-对于默认的replication channel,relay log file命名形式如下`host_name-relay-bin.nnnnnn`:
-- `host_name`为replica server host的名称
-- `nnnnnn`是序列号,序列号从000001开始
-
-对于非默认的replication channels,默认的名称为`host_name-relay-bin-channel`:
-- `channel`为replciation channel的名称
-
-replica会使用index file来追踪当前在使用的relay log files。默认relay log index file的名称为`host_name-relay-bin.index`。
-
-当如下条件下,replica server将会创建新的relay log file:
-- 每次replication I/O thread开启时
-- 当logs被刷新时(例如,当执行`FLUSH LOGS`命令时)
-- 当当前relay log file的大小太大时,大小上限可以通过如下方式决定
- - 如果`max_relay_log_size`的大小大于0,那么其就是relay log file的最大大小
- - 如果`max_relay_log_size`为0,那么relay log file的最大大小由`max_binlog_size`决定
-
-replication sql thread在其执行完文件中所有events之后,都不再需要该文件,被执行完的relay log file都会被自动删除。目前没有显式的机制来删除relay logs,relay log的删除由replciation sql thread来处理。但是,`FLUSH LOGS`可以针对relay logs进行rotation。
-
-
+- [Replication](#replication)
+ - [Configuration Replication](#configuration-replication)
+ - [binary log file position based replication configuration overview](#binary-log-file-position-based-replication-configuration-overview)
+ - [Replication with Global Transaction Identifiers](#replication-with-global-transaction-identifiers)
+ - [GTID Format and Storage](#gtid-format-and-storage)
+ - [GTID Sets](#gtid-sets)
+ - [msyql.gtid\_executed](#msyqlgtid_executed)
+ - [mysql.gtid\_executed table compression](#mysqlgtid_executed-table-compression)
+ - [GTID生命周期](#gtid生命周期)
+ - [What changes are assign a GTID](#what-changes-are-assign-a-gtid)
+ - [Replication Implementation](#replication-implementation)
+ - [Replication Formats](#replication-formats)
+ - [使用statement-based和row-based replication的优缺点对比](#使用statement-based和row-based-replication的优缺点对比)
+ - [Advantages of statement-based replication](#advantages-of-statement-based-replication)
+ - [Disadvantages of statement-based replication](#disadvantages-of-statement-based-replication)
+ - [Advantages of row-based replication](#advantages-of-row-based-replication)
+ - [disadvantages of row-based replication](#disadvantages-of-row-based-replication)
+ - [Replay Log and Replication Metadata Repositories](#replay-log-and-replication-metadata-repositories)
+ - [The Relay Log](#the-relay-log)
+
+# Replication
+Replication允许数据从一个database server被复制到一个或多个mysql database servers(replicas)。replication默认是异步的;replicas并无需永久连接即可接收来自source的更新。基于configuration,可以针对所有的databases、选定的databases、甚至database中指定的tables进行replicate。
+
+mysql中replication包含如下优点:
+- 可拓展方案:可以将负载分散到多个replicas,从而提升性能。在该环境中,所有的writes和updates都发生在source server。但是,reads则是可以发生在一个或多个replicas上。通过该模型,能够提升writes的性能(因为source专门用于更新),并可以通过增加replicas的数量来提高read speed
+- data security: 因为replica可以暂停replication过程,故而可以在replica中运行备份服务,而不会破坏对应的source data
+- analytics:实时数据可以在source中生成,而对信息的分析则可以发生在replica,分析过程不会影响source的性能
+- long-distance data distribution:可以replication来对remote site创建一个local copy,而无需对source的永久访问
+
+在mysql 8.4中,支持不同的replication方式。
+- 传统方式基于从source的binary log中复制事件,并且需要log files和`在source和replica之间进行同步的position`。
+- 新的replication方式基于global transaction identifiers(GTIDs),是事务的,并且不需要和log files、position进行交互,其大大简化了许多通用的replication任务。使用GTIDs的replication保证了source和replica的一致性,所有在source提交的事务都会在replica被应用。
+
+mysql中的replication支持不同类型的同步。
+- 原始的同步是单向、异步的复制,一个server作为source、其他一个或多个servers作为replicas。
+- NDB Cluster中,支持synchronous replication
+- 在mysql 8.4中,支持了半同步复制,通过半同步复制,在source中执行的提交将会被阻塞,直到至少一个replica收到transaction并对transaction进行log event,且向source发送ack
+- mysql 8.4同样支持delayed replication,使得replica故意落后于source至少指定的时间
+
+## Configuration Replication
+### binary log file position based replication configuration overview
+在该section中,会描述mysql servers间基于binary log file position的replication方案。(source会将database的writes和updates操作以events的形式写入到binary log中)。根据database记录的变更,binary log中的信息将会以不同的logging format存储。replicas可以被配置,从source的binary log读取events,并且在replica本地的binary log中执行时间。
+
+每个replica都会接收binary log的完整副本内容,并由replica来决定binary log中哪些statements应当被执行。除非你显式指定,否则binary log中所有的events都会在replica上被执行。如果需要,你可以对replica进行配置,仅处理应用于特定databases、tables的events。
+
+每个replica都会记录二进制日志的坐标:其已经从source读取并处理的file name和文件中的position。这代表多个replicas可以连接到source,并执行相同binary log的不同部分。由于该过程受replicas控制,故而独立的replicas可以和source建立连接、取消连接,并且不会影响到source的操作。并且,每个replica记录了binary log的当前position,replica可以断开连接、重新连接并重启之前的过程。
+
+source和每个replica都配置了unique ID(使用`server_id` system variable),除此之外,每个replica必须配置如下信息:
+- source's host name
+- source's log file name
+- position of source's file
+
+这些可以在replica的mysql session内通过`CHANGE REPLICATION SOURCE TO`语句来管理,并且这些信息存储在replica的connection metadata repository中。
+
+### Replication with Global Transaction Identifiers
+在该章节中,描述了使用global transaction identifiers(GTIDs)的transaction-based replication。当使用GTIDs时,每个在source上提交的事务都可以被标识和追踪,并可以被任一replica应用。
+
+在使用GTIDs时,启动新replica或failover to a new source时并不需要参照log files或file position。由于GTIDs时完全transaction-based的,其更容易判断是否source和replicas一致,只要在source中提交的事务全部也都在replica上提交,那么source和replica则是保证一致的。
+
+在使用GTIDs时,可以选择是statement-based的还是row-based的,推荐使用row-based format。
+
+GTIDs在source和replica都是持久化的。总是可以通过检测binary log来判断是否source中的任一事务是否在replica上被应用。此外,一旦给定GTID的事务在给定server上被提交,那么后续任一事务如果拥有相同的GTID,其都会被server忽略。因此,在source上被提交的事务可以在replica上应用多次,冗余的应用会被忽略,其可以保证数据的一致性。
+
+#### GTID Format and Storage
+一个global transation identifier(GTID)是一个唯一标识符,该标识符的创建并和`source上提交的每一个事务`进行关联。GTID不仅在创建其的server上是唯一的,并且在给定replication拓扑的所有servers间是唯一的。
+
+GTID的分配区分了client trasactions(在source上提交的事务)以及replicated transactions(在replica上reproduced的事务)。当client transaction在source上提交时,如果transaction被写入到binary log中,其会被分配一个新的GTID。client transactions将会被保证单调递增,并且生成的编号之间不会存在间隙。`如果client transaction没有被写入到binary log,那么其在source中并不会被分配GTID`。
+
+Replicated transaction将会使用`事务被source server分配的GTID`。在replicated transaction开始执行前,GTID就已经存在,并且,即使replicated transaction没有写入到replica的binary log中或是被replica过滤,该GTID也会被持久化。`mysql.gtid_executed` system table将会被用于保存`应用到给定server的所有事务的GTID,但是,已经存储到当前active binary log file的除外`。
+
+> `active binary log file`中的gtid最终也会被写入到`gtid_executed`表中,但是,对于不同的存储引擎,写入时机可能不同。对于innodb而言,在事务提交时就会写入gtid_executed表,而对于其他存储引擎而言,则会在binary log发生rotation/server shutdown后才会将active binary log中尚未写入的GTIDs写入到`mysql.gtid_executed`表
+
+GTIDs的auto-skip功能代表一个在source上提交的事务最多只能在replica上应用一次,这有助于保证一致性。一旦拥有给定GTID的事务在给定server上被提交,任何后续执行的事务如果拥有相同的GTID,都会被server忽略。并不会抛出异常,并且事务中的statements都不会被实际执行。
+
+如果拥有给定GTID的事务在server上已经开始执行,但是尚未提交或回滚,那么任何尝试开启一个`拥有相同GTID事务的操作都会被阻塞`。该server并不会开始执行拥有相同GTID的事务,也不会将控制权交还给client。一旦第一个事务提交或回滚,那么被阻塞的事务就可以开始执行。如果第一次执行被回滚,那么被阻塞事务可以实际执行;如果第一个事务成功提交,那么被阻塞事务并不会被实际执行,而是会被自动跳过。
+
+GTID的表示形式如下:
+```
+GTID = source_id:transaction_id
+```
+- `source_id`表示了originating server,通常为source的`server_uuid`
+- `transaction_id`则是一个由`transaction在source上提交顺序`决定的序列号。例如,第一个被提交的事务,其transaction_id为1;而第十个被提交的事务,其transaction_id则是为10.
+ - 在GTID中,transaction_id部分的值不可能为0
+
+例如,在UUID为`3E11FA47-71CA-11E1-9E33-C80AA9429562`上的server提交的第23个事务,其GTID为
+```
+3E11FA47-71CA-11E1-9E33-C80AA9429562:23
+```
+
+在GTID中,序列号的上限值为`2^63 - 1, or 9223372036854775807`(signed 64-bit integer)。如果server运行时超过GTIDs,其将执行`binlog_error_action`指定的行为。当server接近该限制时,会发出一个warning message。
+
+在mysql 8.4中,也支持tagged GTIDs,一个tagged GTID由三部分组成,通过`:`进行分隔,示例如下所示:
+```
+GTID = source_id:tag:transaction_id
+```
+
+在该示例中,`source_id`和`transaction_id`的含义和先前相同,`tag`则是一个用户自定义的字符串,用于表示`specific group of transactions`。
+
+例如,在UUID为`ed102faf-eb00-11eb-8f20-0c5415bfaa1d`的server上第117个提交的tag为`Domain_1`的事务,其GTID为
+```
+ed102faf-eb00-11eb-8f20-0c5415bfaa1d:Domain_1:117
+```
+
+事务的GTID会展示在`mysqlbinlog`的输出中,用于分辨`performance schema replication status tables`中独立的事务,例如`replication_applier_status_by_worker`表。
+
+`gtid_next` system variable的值是单个GTID。
+
+##### GTID Sets
+一个GTID set由`一个或多个GTIDs`或`GTIDs`范围构成。`gtid_executed`或`gtid_purged` system variables存储的就是GTID sets。`START REPLICA`选项`UNTIL SQL_BEFORE_GTIDS`和`UNTIL SQL_AFTER_GTIDS`可令replica在处理事务时,`最多只处理到GTID set中的第一个GTID`或`在处理完GTID set中的最后一个GTID后停止`。内置的`GTID_SUBSET()`和`GTID_SUBTRACT()`函数需要`GTID sets`作为输入。
+
+在相同server上的GTIDs范围可以按照如下形式来表示:
+```
+3E11FA47-71CA-11E1-9E33-C80AA9429562:1-5
+```
+上述示例表示在uuid为`3E11FA47-71CA-11E1-9E33-C80AA9429562`的server上提交的顺序为`1~5`之间的事务。
+
+相同server上的多个single GTIDs或ranges of GTIDs可以通过如下形式来表示
+```
+3E11FA47-71CA-11E1-9E33-C80AA9429562:1-3:11:47-49
+```
+
+GTID set可以包含任意`single GTIDs`和`GTIDs range`的组合,也可以包含来自不同server的GTIDs。如下实例中展示了`gtid_executed` system variable中存储的GTID set,代表replica中应用了来自超过一个source的事务:
+```
+2174B383-5441-11E8-B90A-C80AA9429562:1-3, 24DA167-0C0C-11E8-8442-00059A3C7B00:1-19
+```
+当GTID set从server variables中返回时,UUID按照字母排序返回,而序列号间区间则是合并后按照升序排列。
+
+当构建GTID set时,用户自定义tag也会被作为UUID的一部分,这代表来自相同server且tag相同的多个GTIDs可以被包含在一个表达式中,如下所示:
+```
+3E11FA47-71CA-11E1-9E33-C80AA9429562:Domain_1:1-3:11:47-49
+```
+来源相同server,但是tags不同的GTIDs表示方式如下:
+```
+3E11FA47-71CA-11E1-9E33-C80AA9429562:Domain_1:1-3:15-21, 3E11FA47-71CA-11E1-9E33-C80AA9429562:Domain_2:8-52
+```
+
+GTID set的完整语法如下所示:
+```
+gtid_set:
+ uuid_set [, uuid_set] ...
+ | ''
+
+uuid_set:
+ uuid:[tag:]interval[:interval]...
+
+uuid:
+ hhhhhhhh-hhhh-hhhh-hhhh-hhhhhhhhhhhh
+
+h:
+ [0-9|A-F]
+
+tag:
+ [a-z_][a-z0-9_]{0,31}
+
+interval:
+ m[-n]
+
+ (m >= 1; n > m)
+```
+##### msyql.gtid_executed
+GTIDs被存储在`mysql.gtid_executed`表中,该表中的行用于表示GTID或GTID set,行包含信息如下
+- source server的uuid
+- 用户自定义的tag
+- starting transaction IDs of the set
+- ending transaction IDs of the set
+
+如果行代表single GTID,那么最后两个字段的值相同。
+
+`mysql.gtid_executed`表在mysql server安装或升级时会被自动创建,其表结构如下:
+```sql
+CREATE TABLE gtid_executed (
+ source_uuid CHAR(36) NOT NULL,
+ interval_start BIGINT NOT NULL,
+ interval_end BIGINT NOT NULL,
+ gtid_tag CHAR(32) NOT NULL,
+ PRIMARY KEY (source_uuid, gtid_tag, interval_start)
+);
+```
+
+`mysql.gtid_executed`用于mysql server内部使用,其允许replica在binary logging被禁用的情况下使用GTIDs,其也可以在binary logs丢失时保留GTID的状态。如果执行`RESET BINARY LOGS AND GTIDS`,那么`mysql.gtid_executed`表将会被清空。
+
+只有当`gtid_mode`被设置为`ON`或`ON_PERMISSIVE`时,GTIDs才会被存储到mysql.gtid_executed中。如果binary logging被禁用,或者`log_replica_updates`被禁用,server在事务提交时将会把属于个各事务的GTID和事务一起存储到buffer中,并且background threads将会周期性将buffer中的内容以entries的形式添加到`mysql.gtid_executed`表中。
+
+对于innodb存储引擎而言,如果binary logging被启用,server更新`mysql.gtid_executed`表的方式将会和`binary logging或replica update logging被启用`时一样,都会在每个事务提交时存储GTID。对于其他存储引擎,则是在binary log rotation发生时或server shut down时更新`mysql.gtid_executed`表的内容。
+
+如果mysql.gtid_executed表无法被写访问,并且binary log file因`reaching the maximum file size`之外的任何理由被rotated,那么current binary log file将仍被使用。并且,当client发起rotation时将会返回错误信息,并且server将会输出warning日志。如果`mysql.gtid_executed`无法被写访问,并且binary log单个文件大小达到`max_binlog_size`,那么server将会根据`binlog_error_action`设置来执行操作。如果`IGNORE_ERROR`被设置,那么server将会输出error到日志,并且binary logging将会被停止;如果`ABORT_SERVER`被设置,那么server将会shutdown。
+
+> 因为写入到active binary log的GTIDs最终也要被写入`mysql.gtid_executed`表,但是该表若当前不可写访问,那么此时将无法触发`binary log rotation`。
+>
+> MySQL.gtid_executed中缺失的GTIDs必须包含在active binary log file中,如果log file触发rotation,但是无法向mysql.gtid_executed中写入数据,那么rotation是不被允许的。
+
+
+##### mysql.gtid_executed table compression
+随着时间的推移,mysql.gtid_executed表会填满大量行,行数据代表独立的GTID,示例如下:
+```
++--------------------------------------+----------------+--------------+----------+
+| source_uuid | interval_start | interval_end | gtid_tag |
+|--------------------------------------+----------------+--------------|----------+
+| 3E11FA47-71CA-11E1-9E33-C80AA9429562 | 31 | 31 | Domain_1 |
+| 3E11FA47-71CA-11E1-9E33-C80AA9429562 | 32 | 32 | Domain_1 |
+| 3E11FA47-71CA-11E1-9E33-C80AA9429562 | 33 | 33 | Domain_1 |
+| 3E11FA47-71CA-11E1-9E33-C80AA9429562 | 34 | 34 | Domain_1 |
+| 3E11FA47-71CA-11E1-9E33-C80AA9429562 | 35 | 35 | Domain_1 |
+| 3E11FA47-71CA-11E1-9E33-C80AA9429562 | 36 | 36 | Domain_2 |
+| 3E11FA47-71CA-11E1-9E33-C80AA9429562 | 37 | 37 | Domain_2 |
+| 3E11FA47-71CA-11E1-9E33-C80AA9429562 | 38 | 38 | Domain_2 |
+| 3E11FA47-71CA-11E1-9E33-C80AA9429562 | 39 | 39 | Domain_2 |
+| 3E11FA47-71CA-11E1-9E33-C80AA9429562 | 40 | 40 | Domain_1 |
+| 3E11FA47-71CA-11E1-9E33-C80AA9429562 | 41 | 41 | Domain_1 |
+| 3E11FA47-71CA-11E1-9E33-C80AA9429562 | 42 | 42 | Domain_1 |
+| 3E11FA47-71CA-11E1-9E33-C80AA9429562 | 43 | 43 | Domain_1 |
+| 3E11FA47-71CA-11E1-9E33-C80AA9429562 | 44 | 44 | Domain_2 |
+| 3E11FA47-71CA-11E1-9E33-C80AA9429562 | 45 | 45 | Domain_2 |
+| 3E11FA47-71CA-11E1-9E33-C80AA9429562 | 46 | 46 | Domain_2 |
+| 3E11FA47-71CA-11E1-9E33-C80AA9429562 | 47 | 47 | Domain_1 |
+| 3E11FA47-71CA-11E1-9E33-C80AA9429562 | 48 | 48 | Domain_1 |
+```
+
+为了节省空间,可以对gtid_executed表周期性的进行压缩,将多个`single GTID`替换为单个`GTID set`,压缩后的数据如下;
+```
++--------------------------------------+----------------+--------------+----------+
+| source_uuid | interval_start | interval_end | gtid_tag |
+|--------------------------------------+----------------+--------------|----------+
+| 3E11FA47-71CA-11E1-9E33-C80AA9429562 | 31 | 35 | Domain_1 |
+| 3E11FA47-71CA-11E1-9E33-C80AA9429562 | 36 | 39 | Domain_2 |
+| 3E11FA47-71CA-11E1-9E33-C80AA9429562 | 40 | 43 | Domain_1 |
+| 3E11FA47-71CA-11E1-9E33-C80AA9429562 | 44 | 46 | Domain_2 |
+| 3E11FA47-71CA-11E1-9E33-C80AA9429562 | 47 | 48 | Domain_1 |
+...
+```
+server可通过名为`thread/sql/compress_gtid_table`的前台线程来执行gtid_executed表的压缩操作,该线程并不会在`show processlist`的输出中被列出,但是可以通过查询`threads`表来查看,示例如下:
+```sql
+mysql> SELECT * FROM performance_schema.threads WHERE NAME LIKE '%gtid%'\G
+*************************** 1. row ***************************
+ THREAD_ID: 26
+ NAME: thread/sql/compress_gtid_table
+ TYPE: FOREGROUND
+ PROCESSLIST_ID: 1
+ PROCESSLIST_USER: NULL
+ PROCESSLIST_HOST: NULL
+ PROCESSLIST_DB: NULL
+PROCESSLIST_COMMAND: Daemon
+ PROCESSLIST_TIME: 1509
+ PROCESSLIST_STATE: Suspending
+ PROCESSLIST_INFO: NULL
+ PARENT_THREAD_ID: 1
+ ROLE: NULL
+ INSTRUMENTED: YES
+ HISTORY: YES
+ CONNECTION_TYPE: NULL
+ THREAD_OS_ID: 18677
+```
+当server启用了binary log时,上述压缩方式并不会被使用,`mysql.gtid_executed`在每次binary log rotation时会被压缩。但是,当binary logging被禁用时,`thread/sql/compress_gtid`线程处于sleep状态,每有一定数量的事务被执行时,线程会wake up并执行压缩操作。在table被压缩之前经过的事务数量,即压缩率,可由system variable `gtid_executed_compression_period`来进行控制。如果将值设置为0,代表该thread永远不会wake up。
+
+相比于其他存储引擎,innodb事务写入`mysql.gtid_executed`的过程有所不同,在innodb存储引擎中,过程通过线程`innodb/clone_gtid_thread`来执行。此GTID持久化线程将会分组收集GTIDs,并将其刷新到`mysql.gtid_executed`表中,并对table进行压缩。如果server中既包含innodb事务,又包含non-innodb事务,那么由`compress_gtid_table`线程执行的压缩操作将会干扰`clone_gtid_thread`的工作,并对其效率进行显著下降。为此,在此场景下更推荐将`gtid_executed_compression_period`设置为0,故而`compress_gtid_table`线程将永远不被激活。
+
+`gtid_executed_compression_period`的默认值为0,且所有事务不论其所属存储引擎,都会被`clone_gitid_thread`写入到`mysql.gtid_exec uted`中。
+
+当server实例启动后,如果`gtid_executed_compression_preiod`被设置为非0值,并且`compress_gtid_table`线程也启动,在多数server配置中,将会对`msyql.gtid_executed`表执行显式压缩。压缩通过线程的启动触发。
+
+#### GTID生命周期
+GTID生命周期由如下步骤组成:
+1. 事务在source上被执行并提交,client transaction将会被分配GTID,GTID由`source UUID`和`smallest nonzero transaction sequence number not yet used on this server`组成。GTID也会被写入到binary log中(在log中,GTID被写入在事务之前)。如果client transaction没有被写入binary log(例如,事务被过滤或事务为read-only),那么该事务不会被分配GTID
+2. 如果为事务分配了GTID,那么在事务提交时GTID会被原子的持久化。在binary log中,GTID会被写入到事务开始的位置。不管何时,如果binary log发生rotation或server shutdown,server会将所有写入到binary log file中事务的GTIDs写入到`mysql.gtid_executed`表中
+3. 如果为事务分配了GTID,那么GTID的外部化是`non-atomically`的(在事务提交后非常短的时间)。外部化过程会将GTID添加到`gtid_executed` system variable所代表的GTID set中(`@@GLOBAL.gtid_executed`)。该GTID set中包含`representation of the set of all committed GTID transactions`,并且在replication中会作为代表server state的token使用。
+ 1. 当binary logging启用时,`gtid_executed` system variable代表的GTIDs set是已被应用事务的完整记录。但是`mysql.gtid_executed`表则并记录所有GTIDs,可能由部分GTIDs仍存在于active binary log file中尚未被写入到gtid_executed table
+4. 在binary log data被转移到replica并存储在replica的relay log中后,replica会读取GTID的值,并且将其设置到`gtid_next` system variable中。这告知replica下一个事务将会使用`gtid_next`所代表的GTID。replica在session context中设置`gtid_next`
+5. replica在处理事务前,会验证没有其他线程已经持有了`gtid_next`中GTID的所有权。通过该方法,replica可以保证该该GTID关联的事务在replica上没有被应用过,并且还能保证没有其他session已经读取该GTID但是尚未提交关联事务。故而,如果并发的尝试应用相同的事务,那么server只会让其中的一个运行。
+ 1. replica的`gtid_owned` system variable(`@@GLOBAL.gtid_owned`)代表了当前正在使用的每个GTID和拥有该GTID的线程ID。如果GTID已经被使用过,并不会抛出错误,`auto-skip`功能会忽略该事务
+6. 如果GTID尚未被使用,那么replica将会对replicated transaction进行应用。因为`gtid_next`被设置为了`由source分配的GTID`,replica将不会尝试为事务分配新的GTID,而是直接使用存储在`gtid_next`中存储的GTID
+7. 如果replica上启用了binary logging,GTID将会在提交时被原子的持久化,写入到binary log中事务开始的位置。无论何时,如果binary log发生rotation或server shutdown,server会将`先前写入到binary log中事务的GTIDs`写入到`mysql.gtid_executed`表中
+8. 如果replica禁用binary log,GTID将会原子的被持久化,直接被写入到`mysql.gtid_executed`表中。mysql会向事务中追加一个statement,并且将GTID插入到table中该操作是原子的,在该场景下,`mysql.gtid_executed`表记录了完整的`transactions applied on the replica`。
+9. 在replicated transaction提交后很短的时间,GTID会被非原子的externalized,GTID会被添加到replica的`gtid_executed` system variable代表的GTIDs中。在source中,`gtid_executed` system variable包含了所有提交的GTID事务。
+
+在source上被完全过滤的client transactions并不会被分配GTID,因此其不会被添加到`gtid_executed` system variable或被添加到`mysql.gtid_executed`表中。然而,replicated transaction中的GTIDs即使在replica被完全过滤,也会被持久化。
+- 如果binary logging在replica开启,被过滤的事务将会作为gtid_log_event的形式被写入到binary log,后续跟着一个empty transaction,事务中仅包含BEGIN和COMMIT语句
+- 如果binary logging在replica被禁用,给过滤事务的GTID将会被写入到`mysql.gtid_executed`表
+
+将filtered-out transactions的GTIDs保留,可以确保`mysql.gtid_executed`表和`gtid_executed`system variable中的GTIDs可以被压缩。同时其也能确保replica重新连接到source时,filtered-out transactions不会被重新获取
+
+在多线程的replica上(`replica_parallel_workers > 0`),事务可以被并行的应用,故而replicated transactions可以以不同的顺序来提交(除非`replica_preserve_commit_order = 1`)。在并行提交时,`gtid_executed`system variable中的GTIDs将包含多个GTID ranges,多个范围之间存在空隙。在多线程replicas上,只有最近被应用的事务间才会存在空隙,并且会随着replication的进行而被填充。当replication threads通过`STOP REPLICA`停止时,这些空隙会被填补。当发生shutdown event时(server failure导致),此时replication 停止,空隙仍可能保留。
+
+##### What changes are assign a GTID
+GTID生成的典型场景为`server为提交事务生成新的GTID`。然而,GTIDs可以被分配给除事务外的其他修改,且在某些场景下一个事务可以被分配多个GTIDs。
+
+每个写入binary log的数据库修改(`DDL/DML`)都会被分配一个GTID。其包含了自动提交的变更、使用`BEGIN...COMMIT`的变更和使用`START TRANSACTION`的变更。一个GTID会被分配给数据库的`creation, alteration, deletion`操作,并且`non-table` database object例如`procedure, function, trigger, event, view, user, role, grant`的`creation, alteration, deletion`也会被分配GTID。
+
+非事务更新和事务更新都会被分配`GTID`,额外的,对于非事务更新,如果在尝试写入binary log cahche时发生disk write failure,导致binary log中出现间隙,那么生成的日志事件将会被分配一个GTID。
+
+## Replication Implementation
+在replication的设计中,source server会追踪其binary log中所有对databases的修改。binary log中记录了自server启动时所有修改数据库结构或内容的事件。通常,`SELECT`语句将不会被记录,其并没有对数据库结构或内容造成修改。
+
+每个连接到source的replica都会请求binary log的副本,replica会从source处拉取数据,而不是source向replica推送数据。replica也会执行其从binary log收到的事件。`发生在source上的修改将会在replica上进行重现`。在重现过程中,会发生表创建、表结构修改、数据的新增/删除/修改等操作。
+
+由于每个replica都是独立的,每个连接到source的replica,其对`source中binary log`内容的replaying都是独立的。此外,因为每个replica只通过请求source来接收binary log的拷贝,replica能够以其自身的节奏来读取和更新其数据副本,并且其能在不对source和其他replicas造成影响的条件下开启或停止replication过程。
+
+### Replication Formats
+在binary log中,events根据其事件类型以不同的格式被记录。replication使用的foramts取决于事件被记录到source server的binary log中时所使用的foramt。binary log format和replciation过程中使用到的format,其关联关系如下:
+- 当使用statement-based binary logging时,source会将sql statements写入到binary log。从source到replica的replication将会在replica上执行该sql语句。这被称之为statement-based replication,关联了mysql statement-based binary logging format
+- 当使用row-based loggging时,source将会将`table rows如何变更`的事件写入到binary log中。在replica中,将会重现events对table rows所做的修改。则会被成为row-based replication
+ - `row-based logging`是默认的方法
+- 可以配置mysql使用`mix-format logging`,但使用`mix-format logging`时,将默认使用statement-based log。但是对于特定的语句,也取决于使用的存储引擎,在某些床惊吓log也会被自动切换到row-based。使用mixed format的replication被称之为mix-based replication或mix-format replication
+
+mysql server中的logging format通过`binlog_format` system variable来进行控制。该变量可以在session/global级别进行设置
+- 在将variable设置为session级别时,将仅会对当前session生效,并且仅持续到当前session结束
+- 将variable设置为global级别时,该设置将会对`clients that connect after the change`生效,`但对于any current client sessions,包括.发出该修改请求的session都不生效`
+
+#### 使用statement-based和row-based replication的优缺点对比
+每个binary logging format都有优缺点。对大多数users,mixed replication format能够提供性能和数据完整性的最佳组合。
+
+##### Advantages of statement-based replication
+- 在使用statement-based格式时,会向log files中写入更少的数据。特别是在更新或删除大量行时,使用statement-based格式能够导致更少的空间占用。在从备份中获取和恢复时,其速度也更快
+- log files包含所有造成修改的statements,可以被用于审核database
+
+##### Disadvantages of statement-based replication
+- 对于Statement-based replication而言,statements并不是安全的。并非所有对数据造成修改的statements都可以使用statement-based replication。在使用statement-based replication时,任何非确定性的行为都难以复制(例如在语句中包含随机函数等非确定性行为)
+- 对于复杂语句,statement必须在实际对目标行执行修改前重新计算。而当使用row-based replication时,replica可以直接修改受影响行,而无需重新计算
+
+##### Advantages of row-based replication
+- 所有的修改可以被replicated,其是最安全的replication形式
+
+##### disadvantages of row-based replication
+- 相比于statement-based replication,row-based replication通常会向log中ieur更多数据,特别是当statement操作大量行数据是
+- 在replica并无法查看从source接收并执行的statements。可以通过`mysqlbinlog`的`--base64-output=DECODE-ROWS`和`--verbose`选项来查看数据变更
+
+### Replay Log and Replication Metadata Repositories
+replica server会创建一系列仓库,其中存储在replication过程中使用的信息;
+- `relay log`: 该日志被replication I/O线程写入,包含从source server的binary log读取的事务。relay log中记录的事务将会被replication SQL thread应用到replica
+- `connection metadata repository`: 包含replication receiver thread连接到source server并从binary log获取事务时,需要的信息。connection metadata repository会被写入到`mysql.slave_master_info`中
+- `applier metadata repository`: 包含replication applier thread从relay log读取并应用事务时所需要的信息。applier metadata repository会被写入到`mysql.slave_relay_log_info`表中
+
+#### The Relay Log
+relay log和binary log类似,由一些`numbered files`构成,文件中包含`描述数据库变更的事件`。relay log还包含一个index file,其中记录了所有被使用的relay log files的名称。默认情况下,relay log files位于data directory中
+
+relay log files拥有和binary log相同的格式,也可以通过mysqlbinlog进行读取。如果使用了binary log transaction compression,那么写入relay log的事务payloads也会按照和binary log相同的方式被压缩。
+
+对于默认的replication channel,relay log file命名形式如下`host_name-relay-bin.nnnnnn`:
+- `host_name`为replica server host的名称
+- `nnnnnn`是序列号,序列号从000001开始
+
+对于非默认的replication channels,默认的名称为`host_name-relay-bin-channel`:
+- `channel`为replciation channel的名称
+
+replica会使用index file来追踪当前在使用的relay log files。默认relay log index file的名称为`host_name-relay-bin.index`。
+
+当如下条件下,replica server将会创建新的relay log file:
+- 每次replication I/O thread开启时
+- 当logs被刷新时(例如,当执行`FLUSH LOGS`命令时)
+- 当当前relay log file的大小太大时,大小上限可以通过如下方式决定
+ - 如果`max_relay_log_size`的大小大于0,那么其就是relay log file的最大大小
+ - 如果`max_relay_log_size`为0,那么relay log file的最大大小由`max_binlog_size`决定
+
+replication sql thread在其执行完文件中所有events之后,都不再需要该文件,被执行完的relay log file都会被自动删除。目前没有显式的机制来删除relay logs,relay log的删除由replciation sql thread来处理。但是,`FLUSH LOGS`可以针对relay logs进行rotation。
+
+
diff --git a/spring/Spring Cloud/Spring Cloud.md b/spring/Spring Cloud/Spring Cloud.md
index 220745c..2812075 100644
--- a/spring/Spring Cloud/Spring Cloud.md
+++ b/spring/Spring Cloud/Spring Cloud.md
@@ -1,33 +1,33 @@
-# Spring Cloud简介
-## eureka
-eureka是由netflix公司开源的一个服务注册与发现组件。eureka和其他一些同样由netflix公司开源的组建一起被整合为spring cloud netflix模块。
-### eureka和zookeeper的区别
-#### CAP原则
-CAP原则指的是在一个分布式系统中,一致性(Consistency)、可用性(Aailability)和分区容错性(Partition Tolerance),三者中最多只能实现两者,无法实现三者兼顾。
-- C:一致性表示分布式系统中,不同节点中的数据都要相同
-- A:可用性代表可以允许某一段时间内分布式系统中不同节点的数据可以不同,只要分布式系统能够保证最终数据的一致性。中途,允许分布式系统中的节点数据存在不一致的情形
-- P:及Partition Tolerance,通常情况下,节点之间的网络的断开被称之为network partition。故而,partition tolerance则是能够保证即使发生network partition,分布式系统中的节点也能够继续运行
-
-通常P是必选的,而在满足P的前提下,A和C只能够满足一条,即AP或CP。
-#### zookeeper遵循的原则
-zookeeper遵循的是cp原则,如果zookeeper集群中的leader宕机,那么在新leader选举出来之前,zookeeper集群是拒绝向外提供服务的。
-#### eureka遵循的原则
-和zookeeper不同,eureka遵循的是ap原则,这这意味着eureka允许多个节点之间存在数据不一致的情况,即使某个节点的宕机,eureka仍然能够向外提供服务。
-
-### eureka使用
-可以通过向项目中添加eureka-server的依赖来启动一个eureka-server实例。eureka-server作为注册中心,会将其本身也作为一个服务注册到注册中心中。
-#### 注册实例id
-注册实例id由三部分组成,`主机名称:应用名称:端口号`构成了实例的id。每个实例id都唯一。
-#### eureka-server配置
-- eviction-interval-timer-in-ms:eureka-server会运行固定的scheduled task来清除过期的client,eviction-interval-timer-in-ms属性用于定义task之间的间隔,默认情况下该属性值为60s
-- renewal-percent-threshold:基于该属性,eureka来计算每分钟期望从所有客户端接受到的心跳数。根据eureka-server的自我保护机制,如果eureka-server收到的心跳数小于threshold,那么eureka-server会停止进行客户端实例的淘汰,直到接收到的心跳数大于threshold
-#### eureka-instance配置
-eureka-server-instance本身也作为一个instance注册到注册中心中,故而可以针对eureka-instance作一些配置。
-#### eureka集群
-eureka集群是去中心化的集群,没有主机和从机的概念,eureka节点会向集群中所有其他的节点广播数据的变动。
-## Ribbon
-Spring Cloud Ribbon是一个基于Http和Tcp的客户端负载均衡工具,基于Netflix Ribbon实现,Ribbon主要用于提供负载均衡算法和服务调用。Ribbon的客户端组件提供了一套完善的配置项,如超时和重试等。
-在通过Spring Cloud构建微服务时,Ribbon有两种使用方法,一种是和RedisTemplate结合使用,另一种是和OpenFegin相结合。
-## OpenFeign
-OpenFeign是一个远程调用组件,使用接口和注解以http的形式完成调用。
-Feign中集成了Ribbon,而Ribbon中则集成了eureka。
+# Spring Cloud简介
+## eureka
+eureka是由netflix公司开源的一个服务注册与发现组件。eureka和其他一些同样由netflix公司开源的组建一起被整合为spring cloud netflix模块。
+### eureka和zookeeper的区别
+#### CAP原则
+CAP原则指的是在一个分布式系统中,一致性(Consistency)、可用性(Aailability)和分区容错性(Partition Tolerance),三者中最多只能实现两者,无法实现三者兼顾。
+- C:一致性表示分布式系统中,不同节点中的数据都要相同
+- A:可用性代表可以允许某一段时间内分布式系统中不同节点的数据可以不同,只要分布式系统能够保证最终数据的一致性。中途,允许分布式系统中的节点数据存在不一致的情形
+- P:及Partition Tolerance,通常情况下,节点之间的网络的断开被称之为network partition。故而,partition tolerance则是能够保证即使发生network partition,分布式系统中的节点也能够继续运行
+
+通常P是必选的,而在满足P的前提下,A和C只能够满足一条,即AP或CP。
+#### zookeeper遵循的原则
+zookeeper遵循的是cp原则,如果zookeeper集群中的leader宕机,那么在新leader选举出来之前,zookeeper集群是拒绝向外提供服务的。
+#### eureka遵循的原则
+和zookeeper不同,eureka遵循的是ap原则,这这意味着eureka允许多个节点之间存在数据不一致的情况,即使某个节点的宕机,eureka仍然能够向外提供服务。
+
+### eureka使用
+可以通过向项目中添加eureka-server的依赖来启动一个eureka-server实例。eureka-server作为注册中心,会将其本身也作为一个服务注册到注册中心中。
+#### 注册实例id
+注册实例id由三部分组成,`主机名称:应用名称:端口号`构成了实例的id。每个实例id都唯一。
+#### eureka-server配置
+- eviction-interval-timer-in-ms:eureka-server会运行固定的scheduled task来清除过期的client,eviction-interval-timer-in-ms属性用于定义task之间的间隔,默认情况下该属性值为60s
+- renewal-percent-threshold:基于该属性,eureka来计算每分钟期望从所有客户端接受到的心跳数。根据eureka-server的自我保护机制,如果eureka-server收到的心跳数小于threshold,那么eureka-server会停止进行客户端实例的淘汰,直到接收到的心跳数大于threshold
+#### eureka-instance配置
+eureka-server-instance本身也作为一个instance注册到注册中心中,故而可以针对eureka-instance作一些配置。
+#### eureka集群
+eureka集群是去中心化的集群,没有主机和从机的概念,eureka节点会向集群中所有其他的节点广播数据的变动。
+## Ribbon
+Spring Cloud Ribbon是一个基于Http和Tcp的客户端负载均衡工具,基于Netflix Ribbon实现,Ribbon主要用于提供负载均衡算法和服务调用。Ribbon的客户端组件提供了一套完善的配置项,如超时和重试等。
+在通过Spring Cloud构建微服务时,Ribbon有两种使用方法,一种是和RedisTemplate结合使用,另一种是和OpenFegin相结合。
+## OpenFeign
+OpenFeign是一个远程调用组件,使用接口和注解以http的形式完成调用。
+Feign中集成了Ribbon,而Ribbon中则集成了eureka。
diff --git a/spring/caffeine/caffeine.md b/spring/caffeine/caffeine.md
index aa2da22..1abcc07 100644
--- a/spring/caffeine/caffeine.md
+++ b/spring/caffeine/caffeine.md
@@ -1,234 +1,234 @@
-- [caffeine](#caffeine)
- - [Cache](#cache)
- - [注入](#注入)
- - [手动](#手动)
- - [Loading](#loading)
- - [异步(手动)](#异步手动)
- - [Async Loading](#async-loading)
- - [淘汰](#淘汰)
- - [基于时间的](#基于时间的)
- - [基于时间的淘汰策略](#基于时间的淘汰策略)
- - [基于引用的淘汰策略](#基于引用的淘汰策略)
- - [移除](#移除)
- - [removal listener](#removal-listener)
- - [compute](#compute)
- - [统计](#统计)
- - [cleanup](#cleanup)
- - [软引用和弱引用](#软引用和弱引用)
- - [weakKeys](#weakkeys)
- - [weakValues](#weakvalues)
- - [softValues](#softvalues)
-
-
-# caffeine
-caffeine是一个高性能的java缓存库,其几乎能够提供最佳的命中率。
-cache类似于ConcurrentMap,但并不完全相同。在ConcurrentMap中,会维护所有添加到其中的元素,直到元素被显式移除;而Cache则是可以通过配置来自动的淘汰元素,从而限制cache的内存占用。
-## Cache
-### 注入
-Cache提供了如下的注入策略
-#### 手动
-```java
-Cache cache = Caffeine.newBuilder()
- .expireAfterWrite(10, TimeUnit.MINUTES)
- .maximumSize(10_000)
- .build();
-
-// Lookup an entry, or null if not found
-Graph graph = cache.getIfPresent(key);
-// Lookup and compute an entry if absent, or null if not computable
-graph = cache.get(key, k -> createExpensiveGraph(key));
-// Insert or update an entry
-cache.put(key, graph);
-// Remove an entry
-cache.invalidate(key);
-```
-Cache接口可以显示的操作缓存条目的获取、失效、更新。
-条目可以直接通过cache.put(key,value)来插入到缓存中,该操作会覆盖已存在的key对应的条目。
-也可以使用cache.get(key,k->value)的形式来对缓存进行插入,该方法会在缓存中查找key对应的条目,如果不存在,会调用k->value来进行计算并将计算后的将计算后的结果插入到缓存中。该操作是原子的。如果该条目不可计算,会返回null,如果计算过程中发生异常,则是会抛出异常。
-除上述方法外,也可以通过cache.asMap()返回map对象,并且调用ConcurrentMap中的接口来对缓存条目进行修改。
-#### Loading
-```java
-// build方法可以指定一个CacheLoader参数
-LoadingCache cache = Caffeine.newBuilder()
- .maximumSize(10_000)
- .expireAfterWrite(10, TimeUnit.MINUTES)
- .build(key -> createExpensiveGraph(key));
-
-// Lookup and compute an entry if absent, or null if not computable
-Graph graph = cache.get(key);
-// Lookup and compute entries that are absent
-Map graphs = cache.getAll(keys);
-```
-LoadingCache和CacheLoader相关联。
-可以通过getAll方法来执行批量查找,默认情况下,getAll方法会为每个cache中不存在的key向CacheLoader.load发送一个请求。当批量查找比许多单独的查找效率更加高时,可以重写CacheLoader.loadAll方法。
-#### 异步(手动)
-```java
-AsyncCache cache = Caffeine.newBuilder()
- .expireAfterWrite(10, TimeUnit.MINUTES)
- .maximumSize(10_000)
- .buildAsync();
-
-// Lookup an entry, or null if not found
-CompletableFuture graph = cache.getIfPresent(key);
-// Lookup and asynchronously compute an entry if absent
-graph = cache.get(key, k -> createExpensiveGraph(key));
-// Insert or update an entry
-cache.put(key, graph);
-// Remove an entry
-cache.synchronous().invalidate(key);
-```
-AsyncCache允许异步的计算条目,并且返回CompletableFuture。
-AsyncCache可以调用synchronous方法来提供同步的视图。
-默认情况下executor是ForkJoinPool.commonPool(),可以通过Caffeine.executor(threadPool)来进行覆盖。
-#### Async Loading
-```java
-AsyncLoadingCache cache = Caffeine.newBuilder()
- .maximumSize(10_000)
- .expireAfterWrite(10, TimeUnit.MINUTES)
- // Either: Build with a synchronous computation that is wrapped as asynchronous
- .buildAsync(key -> createExpensiveGraph(key));
- // Or: Build with a asynchronous computation that returns a future
- .buildAsync((key, executor) -> createExpensiveGraphAsync(key, executor));
-
-// Lookup and asynchronously compute an entry if absent
-CompletableFuture graph = cache.get(key);
-// Lookup and asynchronously compute entries that are absent
-CompletableFuture> graphs = cache.getAll(keys);
-```
-AsyncLoadingCache是一个AsyncCache加上一个AsyncCacheLoader。
-同样地,AsyncCacheLoader支持重写load和loadAll方法。
-### 淘汰
-Caffeine提供了三种类型的淘汰:基于size的,基于时间的,基于引用的。
-#### 基于时间的
-```java
-// Evict based on the number of entries in the cache
-LoadingCache graphs = Caffeine.newBuilder()
- .maximumSize(10_000)
- .build(key -> createExpensiveGraph(key));
-
-// Evict based on the number of vertices in the cache
-LoadingCache graphs = Caffeine.newBuilder()
- .maximumWeight(10_000)
- .weigher((Key key, Graph graph) -> graph.vertices().size())
- .build(key -> createExpensiveGraph(key));
-```
-如果你的缓存不应该超过特定的容量限制,应该使用`Caffeine.maximumSize(long)`方法。该缓存会对不常用的条目进行淘汰。
-如果每条记录的权重不同,那么可以通过`Caffeine.weigher(Weigher)`指定一个权重计算方法,并且通过`Caffeine.maximumWeight(long)`指定缓存最大的权重值。
-#### 基于时间的淘汰策略
-```java
-// Evict based on a fixed expiration policy
-LoadingCache graphs = Caffeine.newBuilder()
- .expireAfterAccess(5, TimeUnit.MINUTES)
- .build(key -> createExpensiveGraph(key));
-LoadingCache graphs = Caffeine.newBuilder()
- .expireAfterWrite(10, TimeUnit.MINUTES)
- .build(key -> createExpensiveGraph(key));
-
-// Evict based on a varying expiration policy
-LoadingCache graphs = Caffeine.newBuilder()
- .expireAfter(new Expiry() {
- public long expireAfterCreate(Key key, Graph graph, long currentTime) {
- // Use wall clock time, rather than nanotime, if from an external resource
- long seconds = graph.creationDate().plusHours(5)
- .minus(System.currentTimeMillis(), MILLIS)
- .toEpochSecond();
- return TimeUnit.SECONDS.toNanos(seconds);
- }
- public long expireAfterUpdate(Key key, Graph graph,
- long currentTime, long currentDuration) {
- return currentDuration;
- }
- public long expireAfterRead(Key key, Graph graph,
- long currentTime, long currentDuration) {
- return currentDuration;
- }
- })
- .build(key -> createExpensiveGraph(key));
-```
-caffine提供三种方法来进行基于时间的淘汰:
-- expireAfterAccess(long, TimeUnit):基于上次读写操作过后的时间来进行淘汰
-- expireAfterWrite(long, TimeUnit):基于创建时间、或上次写操作执行的时间来进行淘汰
-- expireAfter(Expire):基于自定义的策略来进行淘汰
-过期在写操作之间周期性的进行触发,偶尔也会在读操作之间进行出发。调度和发送过期事件都是在o(1)时间之内完成的。
-为了及时过期,而不是通过缓存活动来触发过期,可以通过`Caffeine.scheuler(scheduler)`来指定调度线程
-#### 基于引用的淘汰策略
-```java
-// Evict when neither the key nor value are strongly reachable
-LoadingCache graphs = Caffeine.newBuilder()
- .weakKeys()
- .weakValues()
- .build(key -> createExpensiveGraph(key));
-
-// Evict when the garbage collector needs to free memory
-LoadingCache graphs = Caffeine.newBuilder()
- .softValues()
- .build(key -> createExpensiveGraph(key));
-```
-caffeine允许设置cache支持垃圾回收,通过使用为key指定weak reference,为value制定soft reference
-
-### 移除
-可以通过下述方法显式移除条目:
-```java
-// individual key
-cache.invalidate(key)
-// bulk keys
-cache.invalidateAll(keys)
-// all keys
-cache.invalidateAll()
-```
-#### removal listener
-```java
-Cache graphs = Caffeine.newBuilder()
- .evictionListener((Key key, Graph graph, RemovalCause cause) ->
- System.out.printf("Key %s was evicted (%s)%n", key, cause))
- .removalListener((Key key, Graph graph, RemovalCause cause) ->
- System.out.printf("Key %s was removed (%s)%n", key, cause))
- .build();
-```
-在entry被移除时,可以指定listener来执行一系列操作,通过`Caffeine.removalListener(RemovalListener)`。操作是通过Executor异步执行的。
-当想要在缓存失效之后同步执行操作时,可以使用`Caffeine.evictionListener(RemovalListener)`.该监听器将会在`RemovalCause.wasEvicted()`时被触发
-### compute
-通过compute,caffeine可以在entry创建、淘汰、更新时,原子的执行一系列操作:
-```java
-Cache graphs = Caffeine.newBuilder()
- .evictionListener((Key key, Graph graph, RemovalCause cause) -> {
- // atomically intercept the entry's eviction
- }).build();
-
-graphs.asMap().compute(key, (k, v) -> {
- Graph graph = createExpensiveGraph(key);
- ... // update a secondary store
- return graph;
-});
-```
-### 统计
-通过`Caffeine.recordStats()`方法,可以启用统计信息的收集,`cache.stats()`方法将返回一个CacheStats对象,提供如下接口:
-- hitRate():返回请求命中率
-- evictionCount():cache淘汰次数
-- averageLoadPenalty():load新值花费的平均时间
-```java
-Cache graphs = Caffeine.newBuilder()
- .maximumSize(10_000)
- .recordStats()
- .build();
-```
-### cleanup
-默认情况下,Caffine并不会在自动淘汰entry后或entry失效之后立即进行清理,而是在写操作之后执行少量的清理工作,如果写操作很少,则是偶尔在读操作后执行少量读操作。
-如果你的缓存是高吞吐量的,那么不必担心过期缓存的清理,如果你的缓存读写操作都比较少,那么需要新建一个外部线程来调用`Cache.cleanUp()`来进行缓存清理。
-```java
-LoadingCache graphs = Caffeine.newBuilder()
- .scheduler(Scheduler.systemScheduler())
- .expireAfterWrite(10, TimeUnit.MINUTES)
- .build(key -> createExpensiveGraph(key));
-```
-scheduler可以用于及时的清理过期缓存
-
-### 软引用和弱引用
-caffeine支持基于引用来设置淘汰策略。caffeine支持针对key和value使用弱引用,针对value使用软引用。
-#### weakKeys
-`caffeine.weakKeys()`存储使用弱引用的key,如果没有强引用指向key,那么key将会被垃圾回收。垃圾回收时只会比较对象地址,故而整个缓存在比较key时会通过`==`而不是`equals`来进行比较
-#### weakValues
-`caffeine.weakValues()`存储使用弱引用的value,如果没有强引用指向value,value会被垃圾回收。同样地,在整个cache中,会使用`==`而不是`equals`来对value进行比较
-#### softValues
-软引用的value通常会在垃圾回收时按照lru的方式进行回收,根据内存情况决定是否进行回收。由于使用软引用会带来性能问题,通常更推荐使用基于max-size的回收策略。
-同样地,基于软引用的value在整个缓存中会通过`==`而不是`equals()`来进行垃圾回收。
+- [caffeine](#caffeine)
+ - [Cache](#cache)
+ - [注入](#注入)
+ - [手动](#手动)
+ - [Loading](#loading)
+ - [异步(手动)](#异步手动)
+ - [Async Loading](#async-loading)
+ - [淘汰](#淘汰)
+ - [基于时间的](#基于时间的)
+ - [基于时间的淘汰策略](#基于时间的淘汰策略)
+ - [基于引用的淘汰策略](#基于引用的淘汰策略)
+ - [移除](#移除)
+ - [removal listener](#removal-listener)
+ - [compute](#compute)
+ - [统计](#统计)
+ - [cleanup](#cleanup)
+ - [软引用和弱引用](#软引用和弱引用)
+ - [weakKeys](#weakkeys)
+ - [weakValues](#weakvalues)
+ - [softValues](#softvalues)
+
+
+# caffeine
+caffeine是一个高性能的java缓存库,其几乎能够提供最佳的命中率。
+cache类似于ConcurrentMap,但并不完全相同。在ConcurrentMap中,会维护所有添加到其中的元素,直到元素被显式移除;而Cache则是可以通过配置来自动的淘汰元素,从而限制cache的内存占用。
+## Cache
+### 注入
+Cache提供了如下的注入策略
+#### 手动
+```java
+Cache cache = Caffeine.newBuilder()
+ .expireAfterWrite(10, TimeUnit.MINUTES)
+ .maximumSize(10_000)
+ .build();
+
+// Lookup an entry, or null if not found
+Graph graph = cache.getIfPresent(key);
+// Lookup and compute an entry if absent, or null if not computable
+graph = cache.get(key, k -> createExpensiveGraph(key));
+// Insert or update an entry
+cache.put(key, graph);
+// Remove an entry
+cache.invalidate(key);
+```
+Cache接口可以显示的操作缓存条目的获取、失效、更新。
+条目可以直接通过cache.put(key,value)来插入到缓存中,该操作会覆盖已存在的key对应的条目。
+也可以使用cache.get(key,k->value)的形式来对缓存进行插入,该方法会在缓存中查找key对应的条目,如果不存在,会调用k->value来进行计算并将计算后的将计算后的结果插入到缓存中。该操作是原子的。如果该条目不可计算,会返回null,如果计算过程中发生异常,则是会抛出异常。
+除上述方法外,也可以通过cache.asMap()返回map对象,并且调用ConcurrentMap中的接口来对缓存条目进行修改。
+#### Loading
+```java
+// build方法可以指定一个CacheLoader参数
+LoadingCache cache = Caffeine.newBuilder()
+ .maximumSize(10_000)
+ .expireAfterWrite(10, TimeUnit.MINUTES)
+ .build(key -> createExpensiveGraph(key));
+
+// Lookup and compute an entry if absent, or null if not computable
+Graph graph = cache.get(key);
+// Lookup and compute entries that are absent
+Map graphs = cache.getAll(keys);
+```
+LoadingCache和CacheLoader相关联。
+可以通过getAll方法来执行批量查找,默认情况下,getAll方法会为每个cache中不存在的key向CacheLoader.load发送一个请求。当批量查找比许多单独的查找效率更加高时,可以重写CacheLoader.loadAll方法。
+#### 异步(手动)
+```java
+AsyncCache cache = Caffeine.newBuilder()
+ .expireAfterWrite(10, TimeUnit.MINUTES)
+ .maximumSize(10_000)
+ .buildAsync();
+
+// Lookup an entry, or null if not found
+CompletableFuture graph = cache.getIfPresent(key);
+// Lookup and asynchronously compute an entry if absent
+graph = cache.get(key, k -> createExpensiveGraph(key));
+// Insert or update an entry
+cache.put(key, graph);
+// Remove an entry
+cache.synchronous().invalidate(key);
+```
+AsyncCache允许异步的计算条目,并且返回CompletableFuture。
+AsyncCache可以调用synchronous方法来提供同步的视图。
+默认情况下executor是ForkJoinPool.commonPool(),可以通过Caffeine.executor(threadPool)来进行覆盖。
+#### Async Loading
+```java
+AsyncLoadingCache cache = Caffeine.newBuilder()
+ .maximumSize(10_000)
+ .expireAfterWrite(10, TimeUnit.MINUTES)
+ // Either: Build with a synchronous computation that is wrapped as asynchronous
+ .buildAsync(key -> createExpensiveGraph(key));
+ // Or: Build with a asynchronous computation that returns a future
+ .buildAsync((key, executor) -> createExpensiveGraphAsync(key, executor));
+
+// Lookup and asynchronously compute an entry if absent
+CompletableFuture graph = cache.get(key);
+// Lookup and asynchronously compute entries that are absent
+CompletableFuture> graphs = cache.getAll(keys);
+```
+AsyncLoadingCache是一个AsyncCache加上一个AsyncCacheLoader。
+同样地,AsyncCacheLoader支持重写load和loadAll方法。
+### 淘汰
+Caffeine提供了三种类型的淘汰:基于size的,基于时间的,基于引用的。
+#### 基于时间的
+```java
+// Evict based on the number of entries in the cache
+LoadingCache graphs = Caffeine.newBuilder()
+ .maximumSize(10_000)
+ .build(key -> createExpensiveGraph(key));
+
+// Evict based on the number of vertices in the cache
+LoadingCache graphs = Caffeine.newBuilder()
+ .maximumWeight(10_000)
+ .weigher((Key key, Graph graph) -> graph.vertices().size())
+ .build(key -> createExpensiveGraph(key));
+```
+如果你的缓存不应该超过特定的容量限制,应该使用`Caffeine.maximumSize(long)`方法。该缓存会对不常用的条目进行淘汰。
+如果每条记录的权重不同,那么可以通过`Caffeine.weigher(Weigher)`指定一个权重计算方法,并且通过`Caffeine.maximumWeight(long)`指定缓存最大的权重值。
+#### 基于时间的淘汰策略
+```java
+// Evict based on a fixed expiration policy
+LoadingCache graphs = Caffeine.newBuilder()
+ .expireAfterAccess(5, TimeUnit.MINUTES)
+ .build(key -> createExpensiveGraph(key));
+LoadingCache graphs = Caffeine.newBuilder()
+ .expireAfterWrite(10, TimeUnit.MINUTES)
+ .build(key -> createExpensiveGraph(key));
+
+// Evict based on a varying expiration policy
+LoadingCache graphs = Caffeine.newBuilder()
+ .expireAfter(new Expiry() {
+ public long expireAfterCreate(Key key, Graph graph, long currentTime) {
+ // Use wall clock time, rather than nanotime, if from an external resource
+ long seconds = graph.creationDate().plusHours(5)
+ .minus(System.currentTimeMillis(), MILLIS)
+ .toEpochSecond();
+ return TimeUnit.SECONDS.toNanos(seconds);
+ }
+ public long expireAfterUpdate(Key key, Graph graph,
+ long currentTime, long currentDuration) {
+ return currentDuration;
+ }
+ public long expireAfterRead(Key key, Graph graph,
+ long currentTime, long currentDuration) {
+ return currentDuration;
+ }
+ })
+ .build(key -> createExpensiveGraph(key));
+```
+caffine提供三种方法来进行基于时间的淘汰:
+- expireAfterAccess(long, TimeUnit):基于上次读写操作过后的时间来进行淘汰
+- expireAfterWrite(long, TimeUnit):基于创建时间、或上次写操作执行的时间来进行淘汰
+- expireAfter(Expire):基于自定义的策略来进行淘汰
+过期在写操作之间周期性的进行触发,偶尔也会在读操作之间进行出发。调度和发送过期事件都是在o(1)时间之内完成的。
+为了及时过期,而不是通过缓存活动来触发过期,可以通过`Caffeine.scheuler(scheduler)`来指定调度线程
+#### 基于引用的淘汰策略
+```java
+// Evict when neither the key nor value are strongly reachable
+LoadingCache graphs = Caffeine.newBuilder()
+ .weakKeys()
+ .weakValues()
+ .build(key -> createExpensiveGraph(key));
+
+// Evict when the garbage collector needs to free memory
+LoadingCache graphs = Caffeine.newBuilder()
+ .softValues()
+ .build(key -> createExpensiveGraph(key));
+```
+caffeine允许设置cache支持垃圾回收,通过使用为key指定weak reference,为value制定soft reference
+
+### 移除
+可以通过下述方法显式移除条目:
+```java
+// individual key
+cache.invalidate(key)
+// bulk keys
+cache.invalidateAll(keys)
+// all keys
+cache.invalidateAll()
+```
+#### removal listener
+```java
+Cache graphs = Caffeine.newBuilder()
+ .evictionListener((Key key, Graph graph, RemovalCause cause) ->
+ System.out.printf("Key %s was evicted (%s)%n", key, cause))
+ .removalListener((Key key, Graph graph, RemovalCause cause) ->
+ System.out.printf("Key %s was removed (%s)%n", key, cause))
+ .build();
+```
+在entry被移除时,可以指定listener来执行一系列操作,通过`Caffeine.removalListener(RemovalListener)`。操作是通过Executor异步执行的。
+当想要在缓存失效之后同步执行操作时,可以使用`Caffeine.evictionListener(RemovalListener)`.该监听器将会在`RemovalCause.wasEvicted()`时被触发
+### compute
+通过compute,caffeine可以在entry创建、淘汰、更新时,原子的执行一系列操作:
+```java
+Cache graphs = Caffeine.newBuilder()
+ .evictionListener((Key key, Graph graph, RemovalCause cause) -> {
+ // atomically intercept the entry's eviction
+ }).build();
+
+graphs.asMap().compute(key, (k, v) -> {
+ Graph graph = createExpensiveGraph(key);
+ ... // update a secondary store
+ return graph;
+});
+```
+### 统计
+通过`Caffeine.recordStats()`方法,可以启用统计信息的收集,`cache.stats()`方法将返回一个CacheStats对象,提供如下接口:
+- hitRate():返回请求命中率
+- evictionCount():cache淘汰次数
+- averageLoadPenalty():load新值花费的平均时间
+```java
+Cache graphs = Caffeine.newBuilder()
+ .maximumSize(10_000)
+ .recordStats()
+ .build();
+```
+### cleanup
+默认情况下,Caffine并不会在自动淘汰entry后或entry失效之后立即进行清理,而是在写操作之后执行少量的清理工作,如果写操作很少,则是偶尔在读操作后执行少量读操作。
+如果你的缓存是高吞吐量的,那么不必担心过期缓存的清理,如果你的缓存读写操作都比较少,那么需要新建一个外部线程来调用`Cache.cleanUp()`来进行缓存清理。
+```java
+LoadingCache graphs = Caffeine.newBuilder()
+ .scheduler(Scheduler.systemScheduler())
+ .expireAfterWrite(10, TimeUnit.MINUTES)
+ .build(key -> createExpensiveGraph(key));
+```
+scheduler可以用于及时的清理过期缓存
+
+### 软引用和弱引用
+caffeine支持基于引用来设置淘汰策略。caffeine支持针对key和value使用弱引用,针对value使用软引用。
+#### weakKeys
+`caffeine.weakKeys()`存储使用弱引用的key,如果没有强引用指向key,那么key将会被垃圾回收。垃圾回收时只会比较对象地址,故而整个缓存在比较key时会通过`==`而不是`equals`来进行比较
+#### weakValues
+`caffeine.weakValues()`存储使用弱引用的value,如果没有强引用指向value,value会被垃圾回收。同样地,在整个cache中,会使用`==`而不是`equals`来对value进行比较
+#### softValues
+软引用的value通常会在垃圾回收时按照lru的方式进行回收,根据内存情况决定是否进行回收。由于使用软引用会带来性能问题,通常更推荐使用基于max-size的回收策略。
+同样地,基于软引用的value在整个缓存中会通过`==`而不是`equals()`来进行垃圾回收。
diff --git a/中间件/redis/redis sentinel.md b/中间件/redis/redis sentinel.md
new file mode 100644
index 0000000..f3f0570
--- /dev/null
+++ b/中间件/redis/redis sentinel.md
@@ -0,0 +1,83 @@
+- [redis sentinel](#redis-sentinel)
+ - [sentinel as a distributed system](#sentinel-as-a-distributed-system)
+ - [sentinel部署要点](#sentinel部署要点)
+ - [sentinel配置](#sentinel配置)
+ - [sentinel monitor](#sentinel-monitor)
+ - [其他sentinel选项](#其他sentinel选项)
+ - [down-after-milliseconds](#down-after-milliseconds)
+ - [parallel-syncs](#parallel-syncs)
+
+
+# redis sentinel
+## sentinel as a distributed system
+redis sentinel是一个分布式系统,其设计旨在多个sentinel进程协同工作。
+
+redis sentinel的优势如下:
+- 当多个sentinel节点都一致认为master不再可访问时,将会触发故障检测机制。该机制能够有效的降低false positive几率
+- 即使并非所有sentinel进程都正常工作,sentinel机制仍然能够正常工作,确保整个sentinel机制拥有容错性
+
+sentinels、redis实例、客户端共同构成了包含特定属性的更大分布式系统。
+
+sentinels默认会监听26379端口, sentinels实例之间会通过该端口进行通信。如果该端口未开放,那么sentinels之间将无法通信,也无法协商一致,failover将不会被执行。
+
+### sentinel部署要点
+- 对于一个具备鲁棒性的形同部署而言,至少需要三个sentinels进程实例
+- 三个sentinel实例应当被部署在独立故障的计算机/虚拟机中
+- sentinel + redis 分布式系统并不保证在发生故障时,对系统的`acked writes`不被丢失。
+ - 因为redis的replication是异步的,故而在发生故障时可能会丢失部分写入
+- clients需要sentinel支持,大部分client library中包含sentinel支持
+
+### sentinel配置
+redis包含一个名为`sentinel.conf`的文件,用于配置sentinel,典型的最小化配置如下:
+```redis
+sentinel monitor mymaster 127.0.0.1 6379 2
+sentinel down-after-milliseconds mymaster 60000
+sentinel failover-timeout mymaster 180000
+sentinel parallel-syncs mymaster 1
+
+sentinel monitor resque 192.168.1.3 6380 4
+sentinel down-after-milliseconds resque 10000
+sentinel failover-timeout resque 180000
+sentinel parallel-syncs resque 5
+```
+
+只需要指定监控的主节点,并为每个主节点指定不同的名称。无需手动指定replicas,系统会自动发现replicas。sentinel将会自动使用replicas的额外信息来更新配置。
+
+并且,发生故障转移replica被提升为主节点时/新sentinel被发现时,该配置文件也会被重写。
+
+在上述配置文件示例中,监控了两个redis实例集合,每个redis实例集合都由一个master和一系列replicas组成。上述,一个集合被称为`mymaster`,另一个集合被称为`resque`。
+
+### sentinel monitor
+```
+sentinel monitor
+```
+上述是`sentinel monitor`的语法,其用于告知redis监控名为`mymaster`的master实例,并且其地址为`127.0.0.1`,端口号为`6379`,quorum为2。
+
+其中,quorum的含义如下:
+- quorm为需要达成`master不可访问`这一共识的sentinels数量,其将将master标记为失败,并且在条件允许的情况下启动failover
+- quorum仅用于检测失败。为了实际的执行故障转移,sentinels中的一个需要被选举为leader,这需要获取多数sentinel进程的投票后才能完成
+
+例如,假设有5个sentinel进程,并且给定master的quorum为2,那么:
+- 如果两个sentinels达成共识master不可访问,那么其中一个sentinel将会尝试开启故障转移
+- 只有当至少存在3个sentinels可访问时,故障转移才会被授权,并实际启动故障转移
+
+在实际应用中,少数派分区将永远不会在故障时触发故障转移。
+
+### 其他sentinel选项
+其他sentinel选项的格式集合都如下:
+```
+sentinel
+```
+
+#### down-after-milliseconds
+`down-after-milliseconds`选项代表sentinel认为实例宕机的时间,在该段时间内实例应当是不可访问的
+
+#### parallel-syncs
+`parallel-syncs`代表故障转移时,replicas同时被重新配置的数量。replicas在故障转移时,会被重新配置并使用新的master节点。
+
+- 当`parallel-syncs`参数指定的值被降低时,故障转移过程耗费的时间将会增加
+- replication过程通常是非阻塞的,但是其间有一个时间段会中止并从master批量加载数据。此时,可能并不希望所有的replicas都不可用并从新master同步数据
+
+配置参数可以在运行时被修改,
+- 针对master的配置参数可以通过`SENTINEL SET`命令修改
+- 全局配置参数可以通过`SENTINEL CONFIG SET`命令来进行修改
-
-### AP(Availability and Partition Tolerance)
-> 这种类型的系统本质上是分布式的,确保即使在network partition场景下,用户发送的针对database nodes中数据的查看和修改请求不会被丢失
-
-该系统优先考虑了Availability而非Consistency,并且可能会返回过期的数据。一些技术failure可能会导致partition,故而过期数据则是代表partition产生前被同步的数据。
-
-AP系统通常在构建社交媒体网站如Facebook和在线内容网站如YouTube时使用,其并不要求一致性。对于使用AP系统的场景,相比于不一致,不可用会造成更大的问题。
-
-AP系统是分布式的,可以分布于多个节点,即使在network partition发生的前提下也能够可靠运行。
-
-### CP(Consistency and Partition Tolerance)
-> 该类系统本质上是分布式的,确保由用户发起的针对database nodes中数据进行查看或修改的请求,在存在network partition的场景下,会直接被丢弃,而不是返回不一致的数据
-
-`CP`系统优先考虑了Consistency而非Availability,如果发生network partition,其不允许用户从replica读取`在network partition发生前同步的数据`。对于部分应用程序来说,相比于可用性,其更强调数据的一致性,例如股票交易系统、订票系统、银行系统等)
-
-例如,在订票系统中,还剩余一个可订购座位。在该CP系统中,将会创建数据库的副本,并且将副本发送给系统中其他的节点。此时,如果发生网络问题,那么连接到partitioned node的用户将会从replica获取数据。此时,其他连接到unpartitioned部分的用户则可以对剩余的作为进行预定。这样,在连接到partitioned node的用户视角中,仍然存在一个seat,其将导致数据不一致。
-
+- [CAP Theorem in DBMS](#cap-theorem-in-dbms)
+ - [What is the CAP Theorem](#what-is-the-cap-theorem)
+ - [Consistency](#consistency)
+ - [Availability](#availability)
+ - [Partition Tolerance](#partition-tolerance)
+ - [The Trade-Offs in the CAP Theorem](#the-trade-offs-in-the-cap-theorem)
+ - [CA(Consistency and Availability)](#caconsistency-and-availability)
+ - [AP(Availability and Partition Tolerance)](#apavailability-and-partition-tolerance)
+ - [CP(Consistency and Partition Tolerance)](#cpconsistency-and-partition-tolerance)
+
+# CAP Theorem in DBMS
+在网络共享数据系统设计中固有的权衡令构建一个可靠且高效的系统十分困难。CAP理论是理解分布式系统中这些权衡的核心基础。CAP理论强调了系统设计者在处理distributed data replication时的局限性。CAP理论指出,在分布式系统中,只能同时满足`一致性、可用性、分区容错`这三个特性中的两种。
+
+> CAP理论中,对分布式系统提出了如下三个特性:
+> - consistency(一致性)
+> - availability(可用性)
+> - partition tolerance(分区容错)
+
+由于该底层限制,开发者必须根据其应用的需要谨慎的平衡这些属性。设计者必须决定优先考虑哪些特性,从而获取最佳的性能和系统可靠性。
+
+## What is the CAP Theorem
+CAP理论是分布式系统的基础概念,其指出分布式系统中所有的三个特性无法被同时满足。
+
+### Consistency
+`Consistency`代表network中所有的节点都包含相同的replicated data拷贝,而这些数据对不同事务可见。其保证分布式居群中所有节点返回相同、最新的数据。其代表所有client对数据的视角都相同。存在许多不同类型的一致性模型,而CAP中的一致性代指的是顺序一致性,是一种非常强的一致性形式。
+
+`ACID`和`CAP`中都包含一致性,但是这两种一致性所有不同:
+- 在`ACID`中,其代表事务不能破坏数据库的完整性约束
+- 在`CAP`中,其代表分布式系统中相同数据项在不同副本中的一致性
+
+### Availability
+Availability代表每个对数据项的read/write request要么能被成功处理,要么能收到一个操作无法被完成的响应。每个non-failing节点都会为所有读写请求在合理的时间范围内生成响应。
+
+其中,“每个节点”代表,即使发生network partition,节点只要不处于failing状态,无论位于network partition的哪一侧,都应该能在合理的时间范围内返回响应。
+
+### Partition Tolerance
+partition tolerance代表在连接节点的网络发生错误、造成两个或多个分区时,系统仍然能够继续进行操作。通常,在出现network partition时,每个partition中的节点只能彼此互相沟通,跨分区的节点通信被阻断。
+
+这意味着,即使发生network partition,系统仍然能持续运行并保证其一致性。network partition是不可避免地,在网络分区恢复正常后,拥有partition tolerance的分布式系统能够优雅的从分区状态中恢复。
+
+CAP理论指出分布式数据库最多只能兼顾如下三个特性中的两种:consistency, availability, partition tolerance。
+
+
+
+## The Trade-Offs in the CAP Theorem
+CAP理论表明分布式系统中只能同时满足三种特性中的两种。
+### CA(Consistency and Availability)
+> 对于CA类型的系统,其总是可以接收来源于用户的查询和修改数据请求,并且分布式网络中所有database nodes都会返回相同的响应
+
+然而,该种类似的分布式系统在现实世界中不可能存在,因为在network failure发生时,仅有如下两种选项:
+- 发送network failure发生前复制的old data
+- 不允许用户访问old data
+
+如果我们选择第一个选项,那么系统将满足Availibility;如果选择第二个选项,系统则是Consistent。
+
+`在分布式系统中,consistency和availability的组合是不可能的`。为了实现`CA`,系统必须是单体架构,当用户更新系统状态时,所有其他用户都能访问到该更新,这将代表系统满足一致性;而在单体架构中,所有用户都连接到一个节点上,这代表其是可用的。`CA`系统通常不被青睐,因为实现分布式计算必须牺牲consistency或availability中的一种,并将剩余的和partition tolerance组合,即`CP/AP`系统。
+
+> CAP中的A(Availability)只是要求非failing状态下的节点能够在合理的时间范围内返回响应,故而单体架构可以满足`Availability`。
+>
+> 即使单体架构可能因单点故障导致系统不可用,不满足`Reliable`(可靠性),并不影响其满足`Availability`(可用性)。
+
+
+
+### AP(Availability and Partition Tolerance)
+> 这种类型的系统本质上是分布式的,确保即使在network partition场景下,用户发送的针对database nodes中数据的查看和修改请求不会被丢失
+
+该系统优先考虑了Availability而非Consistency,并且可能会返回过期的数据。一些技术failure可能会导致partition,故而过期数据则是代表partition产生前被同步的数据。
+
+AP系统通常在构建社交媒体网站如Facebook和在线内容网站如YouTube时使用,其并不要求一致性。对于使用AP系统的场景,相比于不一致,不可用会造成更大的问题。
+
+AP系统是分布式的,可以分布于多个节点,即使在network partition发生的前提下也能够可靠运行。
+
+### CP(Consistency and Partition Tolerance)
+> 该类系统本质上是分布式的,确保由用户发起的针对database nodes中数据进行查看或修改的请求,在存在network partition的场景下,会直接被丢弃,而不是返回不一致的数据
+
+`CP`系统优先考虑了Consistency而非Availability,如果发生network partition,其不允许用户从replica读取`在network partition发生前同步的数据`。对于部分应用程序来说,相比于可用性,其更强调数据的一致性,例如股票交易系统、订票系统、银行系统等)
+
+例如,在订票系统中,还剩余一个可订购座位。在该CP系统中,将会创建数据库的副本,并且将副本发送给系统中其他的节点。此时,如果发生网络问题,那么连接到partitioned node的用户将会从replica获取数据。此时,其他连接到unpartitioned部分的用户则可以对剩余的作为进行预定。这样,在连接到partitioned node的用户视角中,仍然存在一个seat,其将导致数据不一致。
+
在上述场景下,CP系统通常会令其系统对`连接到partitioned node的用户`不可用。
\ No newline at end of file
diff --git a/mysql/mysql集群/Replication.md b/mysql/mysql集群/Replication.md
index 7447a35..1f4d95f 100644
--- a/mysql/mysql集群/Replication.md
+++ b/mysql/mysql集群/Replication.md
@@ -1,355 +1,355 @@
-- [Replication](#replication)
- - [Configuration Replication](#configuration-replication)
- - [binary log file position based replication configuration overview](#binary-log-file-position-based-replication-configuration-overview)
- - [Replication with Global Transaction Identifiers](#replication-with-global-transaction-identifiers)
- - [GTID Format and Storage](#gtid-format-and-storage)
- - [GTID Sets](#gtid-sets)
- - [msyql.gtid\_executed](#msyqlgtid_executed)
- - [mysql.gtid\_executed table compression](#mysqlgtid_executed-table-compression)
- - [GTID生命周期](#gtid生命周期)
- - [What changes are assign a GTID](#what-changes-are-assign-a-gtid)
- - [Replication Implementation](#replication-implementation)
- - [Replication Formats](#replication-formats)
- - [使用statement-based和row-based replication的优缺点对比](#使用statement-based和row-based-replication的优缺点对比)
- - [Advantages of statement-based replication](#advantages-of-statement-based-replication)
- - [Disadvantages of statement-based replication](#disadvantages-of-statement-based-replication)
- - [Advantages of row-based replication](#advantages-of-row-based-replication)
- - [disadvantages of row-based replication](#disadvantages-of-row-based-replication)
- - [Replay Log and Replication Metadata Repositories](#replay-log-and-replication-metadata-repositories)
- - [The Relay Log](#the-relay-log)
-
-# Replication
-Replication允许数据从一个database server被复制到一个或多个mysql database servers(replicas)。replication默认是异步的;replicas并无需永久连接即可接收来自source的更新。基于configuration,可以针对所有的databases、选定的databases、甚至database中指定的tables进行replicate。
-
-mysql中replication包含如下优点:
-- 可拓展方案:可以将负载分散到多个replicas,从而提升性能。在该环境中,所有的writes和updates都发生在source server。但是,reads则是可以发生在一个或多个replicas上。通过该模型,能够提升writes的性能(因为source专门用于更新),并可以通过增加replicas的数量来提高read speed
-- data security: 因为replica可以暂停replication过程,故而可以在replica中运行备份服务,而不会破坏对应的source data
-- analytics:实时数据可以在source中生成,而对信息的分析则可以发生在replica,分析过程不会影响source的性能
-- long-distance data distribution:可以replication来对remote site创建一个local copy,而无需对source的永久访问
-
-在mysql 8.4中,支持不同的replication方式。
-- 传统方式基于从source的binary log中复制事件,并且需要log files和`在source和replica之间进行同步的position`。
-- 新的replication方式基于global transaction identifiers(GTIDs),是事务的,并且不需要和log files、position进行交互,其大大简化了许多通用的replication任务。使用GTIDs的replication保证了source和replica的一致性,所有在source提交的事务都会在replica被应用。
-
-mysql中的replication支持不同类型的同步。
-- 原始的同步是单向、异步的复制,一个server作为source、其他一个或多个servers作为replicas。
-- NDB Cluster中,支持synchronous replication
-- 在mysql 8.4中,支持了半同步复制,通过半同步复制,在source中执行的提交将会被阻塞,直到至少一个replica收到transaction并对transaction进行log event,且向source发送ack
-- mysql 8.4同样支持delayed replication,使得replica故意落后于source至少指定的时间
-
-## Configuration Replication
-### binary log file position based replication configuration overview
-在该section中,会描述mysql servers间基于binary log file position的replication方案。(source会将database的writes和updates操作以events的形式写入到binary log中)。根据database记录的变更,binary log中的信息将会以不同的logging format存储。replicas可以被配置,从source的binary log读取events,并且在replica本地的binary log中执行时间。
-
-每个replica都会接收binary log的完整副本内容,并由replica来决定binary log中哪些statements应当被执行。除非你显式指定,否则binary log中所有的events都会在replica上被执行。如果需要,你可以对replica进行配置,仅处理应用于特定databases、tables的events。
-
-每个replica都会记录二进制日志的坐标:其已经从source读取并处理的file name和文件中的position。这代表多个replicas可以连接到source,并执行相同binary log的不同部分。由于该过程受replicas控制,故而独立的replicas可以和source建立连接、取消连接,并且不会影响到source的操作。并且,每个replica记录了binary log的当前position,replica可以断开连接、重新连接并重启之前的过程。
-
-source和每个replica都配置了unique ID(使用`server_id` system variable),除此之外,每个replica必须配置如下信息:
-- source's host name
-- source's log file name
-- position of source's file
-
-这些可以在replica的mysql session内通过`CHANGE REPLICATION SOURCE TO`语句来管理,并且这些信息存储在replica的connection metadata repository中。
-
-### Replication with Global Transaction Identifiers
-在该章节中,描述了使用global transaction identifiers(GTIDs)的transaction-based replication。当使用GTIDs时,每个在source上提交的事务都可以被标识和追踪,并可以被任一replica应用。
-
-在使用GTIDs时,启动新replica或failover to a new source时并不需要参照log files或file position。由于GTIDs时完全transaction-based的,其更容易判断是否source和replicas一致,只要在source中提交的事务全部也都在replica上提交,那么source和replica则是保证一致的。
-
-在使用GTIDs时,可以选择是statement-based的还是row-based的,推荐使用row-based format。
-
-GTIDs在source和replica都是持久化的。总是可以通过检测binary log来判断是否source中的任一事务是否在replica上被应用。此外,一旦给定GTID的事务在给定server上被提交,那么后续任一事务如果拥有相同的GTID,其都会被server忽略。因此,在source上被提交的事务可以在replica上应用多次,冗余的应用会被忽略,其可以保证数据的一致性。
-
-#### GTID Format and Storage
-一个global transation identifier(GTID)是一个唯一标识符,该标识符的创建并和`source上提交的每一个事务`进行关联。GTID不仅在创建其的server上是唯一的,并且在给定replication拓扑的所有servers间是唯一的。
-
-GTID的分配区分了client trasactions(在source上提交的事务)以及replicated transactions(在replica上reproduced的事务)。当client transaction在source上提交时,如果transaction被写入到binary log中,其会被分配一个新的GTID。client transactions将会被保证单调递增,并且生成的编号之间不会存在间隙。`如果client transaction没有被写入到binary log,那么其在source中并不会被分配GTID`。
-
-Replicated transaction将会使用`事务被source server分配的GTID`。在replicated transaction开始执行前,GTID就已经存在,并且,即使replicated transaction没有写入到replica的binary log中或是被replica过滤,该GTID也会被持久化。`mysql.gtid_executed` system table将会被用于保存`应用到给定server的所有事务的GTID,但是,已经存储到当前active binary log file的除外`。
-
-> `active binary log file`中的gtid最终也会被写入到`gtid_executed`表中,但是,对于不同的存储引擎,写入时机可能不同。对于innodb而言,在事务提交时就会写入gtid_executed表,而对于其他存储引擎而言,则会在binary log发生rotation/server shutdown后才会将active binary log中尚未写入的GTIDs写入到`mysql.gtid_executed`表
-
-GTIDs的auto-skip功能代表一个在source上提交的事务最多只能在replica上应用一次,这有助于保证一致性。一旦拥有给定GTID的事务在给定server上被提交,任何后续执行的事务如果拥有相同的GTID,都会被server忽略。并不会抛出异常,并且事务中的statements都不会被实际执行。
-
-如果拥有给定GTID的事务在server上已经开始执行,但是尚未提交或回滚,那么任何尝试开启一个`拥有相同GTID事务的操作都会被阻塞`。该server并不会开始执行拥有相同GTID的事务,也不会将控制权交还给client。一旦第一个事务提交或回滚,那么被阻塞的事务就可以开始执行。如果第一次执行被回滚,那么被阻塞事务可以实际执行;如果第一个事务成功提交,那么被阻塞事务并不会被实际执行,而是会被自动跳过。
-
-GTID的表示形式如下:
-```
-GTID = source_id:transaction_id
-```
-- `source_id`表示了originating server,通常为source的`server_uuid`
-- `transaction_id`则是一个由`transaction在source上提交顺序`决定的序列号。例如,第一个被提交的事务,其transaction_id为1;而第十个被提交的事务,其transaction_id则是为10.
- - 在GTID中,transaction_id部分的值不可能为0
-
-例如,在UUID为`3E11FA47-71CA-11E1-9E33-C80AA9429562`上的server提交的第23个事务,其GTID为
-```
-3E11FA47-71CA-11E1-9E33-C80AA9429562:23
-```
-
-在GTID中,序列号的上限值为`2^63 - 1, or 9223372036854775807`(signed 64-bit integer)。如果server运行时超过GTIDs,其将执行`binlog_error_action`指定的行为。当server接近该限制时,会发出一个warning message。
-
-在mysql 8.4中,也支持tagged GTIDs,一个tagged GTID由三部分组成,通过`:`进行分隔,示例如下所示:
-```
-GTID = source_id:tag:transaction_id
-```
-
-在该示例中,`source_id`和`transaction_id`的含义和先前相同,`tag`则是一个用户自定义的字符串,用于表示`specific group of transactions`。
-
-例如,在UUID为`ed102faf-eb00-11eb-8f20-0c5415bfaa1d`的server上第117个提交的tag为`Domain_1`的事务,其GTID为
-```
-ed102faf-eb00-11eb-8f20-0c5415bfaa1d:Domain_1:117
-```
-
-事务的GTID会展示在`mysqlbinlog`的输出中,用于分辨`performance schema replication status tables`中独立的事务,例如`replication_applier_status_by_worker`表。
-
-`gtid_next` system variable的值是单个GTID。
-
-##### GTID Sets
-一个GTID set由`一个或多个GTIDs`或`GTIDs`范围构成。`gtid_executed`或`gtid_purged` system variables存储的就是GTID sets。`START REPLICA`选项`UNTIL SQL_BEFORE_GTIDS`和`UNTIL SQL_AFTER_GTIDS`可令replica在处理事务时,`最多只处理到GTID set中的第一个GTID`或`在处理完GTID set中的最后一个GTID后停止`。内置的`GTID_SUBSET()`和`GTID_SUBTRACT()`函数需要`GTID sets`作为输入。
-
-在相同server上的GTIDs范围可以按照如下形式来表示:
-```
-3E11FA47-71CA-11E1-9E33-C80AA9429562:1-5
-```
-上述示例表示在uuid为`3E11FA47-71CA-11E1-9E33-C80AA9429562`的server上提交的顺序为`1~5`之间的事务。
-
-相同server上的多个single GTIDs或ranges of GTIDs可以通过如下形式来表示
-```
-3E11FA47-71CA-11E1-9E33-C80AA9429562:1-3:11:47-49
-```
-
-GTID set可以包含任意`single GTIDs`和`GTIDs range`的组合,也可以包含来自不同server的GTIDs。如下实例中展示了`gtid_executed` system variable中存储的GTID set,代表replica中应用了来自超过一个source的事务:
-```
-2174B383-5441-11E8-B90A-C80AA9429562:1-3, 24DA167-0C0C-11E8-8442-00059A3C7B00:1-19
-```
-当GTID set从server variables中返回时,UUID按照字母排序返回,而序列号间区间则是合并后按照升序排列。
-
-当构建GTID set时,用户自定义tag也会被作为UUID的一部分,这代表来自相同server且tag相同的多个GTIDs可以被包含在一个表达式中,如下所示:
-```
-3E11FA47-71CA-11E1-9E33-C80AA9429562:Domain_1:1-3:11:47-49
-```
-来源相同server,但是tags不同的GTIDs表示方式如下:
-```
-3E11FA47-71CA-11E1-9E33-C80AA9429562:Domain_1:1-3:15-21, 3E11FA47-71CA-11E1-9E33-C80AA9429562:Domain_2:8-52
-```
-
-GTID set的完整语法如下所示:
-```
-gtid_set:
- uuid_set [, uuid_set] ...
- | ''
-
-uuid_set:
- uuid:[tag:]interval[:interval]...
-
-uuid:
- hhhhhhhh-hhhh-hhhh-hhhh-hhhhhhhhhhhh
-
-h:
- [0-9|A-F]
-
-tag:
- [a-z_][a-z0-9_]{0,31}
-
-interval:
- m[-n]
-
- (m >= 1; n > m)
-```
-##### msyql.gtid_executed
-GTIDs被存储在`mysql.gtid_executed`表中,该表中的行用于表示GTID或GTID set,行包含信息如下
-- source server的uuid
-- 用户自定义的tag
-- starting transaction IDs of the set
-- ending transaction IDs of the set
-
-如果行代表single GTID,那么最后两个字段的值相同。
-
-`mysql.gtid_executed`表在mysql server安装或升级时会被自动创建,其表结构如下:
-```sql
-CREATE TABLE gtid_executed (
- source_uuid CHAR(36) NOT NULL,
- interval_start BIGINT NOT NULL,
- interval_end BIGINT NOT NULL,
- gtid_tag CHAR(32) NOT NULL,
- PRIMARY KEY (source_uuid, gtid_tag, interval_start)
-);
-```
-
-`mysql.gtid_executed`用于mysql server内部使用,其允许replica在binary logging被禁用的情况下使用GTIDs,其也可以在binary logs丢失时保留GTID的状态。如果执行`RESET BINARY LOGS AND GTIDS`,那么`mysql.gtid_executed`表将会被清空。
-
-只有当`gtid_mode`被设置为`ON`或`ON_PERMISSIVE`时,GTIDs才会被存储到mysql.gtid_executed中。如果binary logging被禁用,或者`log_replica_updates`被禁用,server在事务提交时将会把属于个各事务的GTID和事务一起存储到buffer中,并且background threads将会周期性将buffer中的内容以entries的形式添加到`mysql.gtid_executed`表中。
-
-对于innodb存储引擎而言,如果binary logging被启用,server更新`mysql.gtid_executed`表的方式将会和`binary logging或replica update logging被启用`时一样,都会在每个事务提交时存储GTID。对于其他存储引擎,则是在binary log rotation发生时或server shut down时更新`mysql.gtid_executed`表的内容。
-
-如果mysql.gtid_executed表无法被写访问,并且binary log file因`reaching the maximum file size`之外的任何理由被rotated,那么current binary log file将仍被使用。并且,当client发起rotation时将会返回错误信息,并且server将会输出warning日志。如果`mysql.gtid_executed`无法被写访问,并且binary log单个文件大小达到`max_binlog_size`,那么server将会根据`binlog_error_action`设置来执行操作。如果`IGNORE_ERROR`被设置,那么server将会输出error到日志,并且binary logging将会被停止;如果`ABORT_SERVER`被设置,那么server将会shutdown。
-
-> 因为写入到active binary log的GTIDs最终也要被写入`mysql.gtid_executed`表,但是该表若当前不可写访问,那么此时将无法触发`binary log rotation`。
->
-> MySQL.gtid_executed中缺失的GTIDs必须包含在active binary log file中,如果log file触发rotation,但是无法向mysql.gtid_executed中写入数据,那么rotation是不被允许的。
-
-
-##### mysql.gtid_executed table compression
-随着时间的推移,mysql.gtid_executed表会填满大量行,行数据代表独立的GTID,示例如下:
-```
-+--------------------------------------+----------------+--------------+----------+
-| source_uuid | interval_start | interval_end | gtid_tag |
-|--------------------------------------+----------------+--------------|----------+
-| 3E11FA47-71CA-11E1-9E33-C80AA9429562 | 31 | 31 | Domain_1 |
-| 3E11FA47-71CA-11E1-9E33-C80AA9429562 | 32 | 32 | Domain_1 |
-| 3E11FA47-71CA-11E1-9E33-C80AA9429562 | 33 | 33 | Domain_1 |
-| 3E11FA47-71CA-11E1-9E33-C80AA9429562 | 34 | 34 | Domain_1 |
-| 3E11FA47-71CA-11E1-9E33-C80AA9429562 | 35 | 35 | Domain_1 |
-| 3E11FA47-71CA-11E1-9E33-C80AA9429562 | 36 | 36 | Domain_2 |
-| 3E11FA47-71CA-11E1-9E33-C80AA9429562 | 37 | 37 | Domain_2 |
-| 3E11FA47-71CA-11E1-9E33-C80AA9429562 | 38 | 38 | Domain_2 |
-| 3E11FA47-71CA-11E1-9E33-C80AA9429562 | 39 | 39 | Domain_2 |
-| 3E11FA47-71CA-11E1-9E33-C80AA9429562 | 40 | 40 | Domain_1 |
-| 3E11FA47-71CA-11E1-9E33-C80AA9429562 | 41 | 41 | Domain_1 |
-| 3E11FA47-71CA-11E1-9E33-C80AA9429562 | 42 | 42 | Domain_1 |
-| 3E11FA47-71CA-11E1-9E33-C80AA9429562 | 43 | 43 | Domain_1 |
-| 3E11FA47-71CA-11E1-9E33-C80AA9429562 | 44 | 44 | Domain_2 |
-| 3E11FA47-71CA-11E1-9E33-C80AA9429562 | 45 | 45 | Domain_2 |
-| 3E11FA47-71CA-11E1-9E33-C80AA9429562 | 46 | 46 | Domain_2 |
-| 3E11FA47-71CA-11E1-9E33-C80AA9429562 | 47 | 47 | Domain_1 |
-| 3E11FA47-71CA-11E1-9E33-C80AA9429562 | 48 | 48 | Domain_1 |
-```
-
-为了节省空间,可以对gtid_executed表周期性的进行压缩,将多个`single GTID`替换为单个`GTID set`,压缩后的数据如下;
-```
-+--------------------------------------+----------------+--------------+----------+
-| source_uuid | interval_start | interval_end | gtid_tag |
-|--------------------------------------+----------------+--------------|----------+
-| 3E11FA47-71CA-11E1-9E33-C80AA9429562 | 31 | 35 | Domain_1 |
-| 3E11FA47-71CA-11E1-9E33-C80AA9429562 | 36 | 39 | Domain_2 |
-| 3E11FA47-71CA-11E1-9E33-C80AA9429562 | 40 | 43 | Domain_1 |
-| 3E11FA47-71CA-11E1-9E33-C80AA9429562 | 44 | 46 | Domain_2 |
-| 3E11FA47-71CA-11E1-9E33-C80AA9429562 | 47 | 48 | Domain_1 |
-...
-```
-server可通过名为`thread/sql/compress_gtid_table`的前台线程来执行gtid_executed表的压缩操作,该线程并不会在`show processlist`的输出中被列出,但是可以通过查询`threads`表来查看,示例如下:
-```sql
-mysql> SELECT * FROM performance_schema.threads WHERE NAME LIKE '%gtid%'\G
-*************************** 1. row ***************************
- THREAD_ID: 26
- NAME: thread/sql/compress_gtid_table
- TYPE: FOREGROUND
- PROCESSLIST_ID: 1
- PROCESSLIST_USER: NULL
- PROCESSLIST_HOST: NULL
- PROCESSLIST_DB: NULL
-PROCESSLIST_COMMAND: Daemon
- PROCESSLIST_TIME: 1509
- PROCESSLIST_STATE: Suspending
- PROCESSLIST_INFO: NULL
- PARENT_THREAD_ID: 1
- ROLE: NULL
- INSTRUMENTED: YES
- HISTORY: YES
- CONNECTION_TYPE: NULL
- THREAD_OS_ID: 18677
-```
-当server启用了binary log时,上述压缩方式并不会被使用,`mysql.gtid_executed`在每次binary log rotation时会被压缩。但是,当binary logging被禁用时,`thread/sql/compress_gtid`线程处于sleep状态,每有一定数量的事务被执行时,线程会wake up并执行压缩操作。在table被压缩之前经过的事务数量,即压缩率,可由system variable `gtid_executed_compression_period`来进行控制。如果将值设置为0,代表该thread永远不会wake up。
-
-相比于其他存储引擎,innodb事务写入`mysql.gtid_executed`的过程有所不同,在innodb存储引擎中,过程通过线程`innodb/clone_gtid_thread`来执行。此GTID持久化线程将会分组收集GTIDs,并将其刷新到`mysql.gtid_executed`表中,并对table进行压缩。如果server中既包含innodb事务,又包含non-innodb事务,那么由`compress_gtid_table`线程执行的压缩操作将会干扰`clone_gtid_thread`的工作,并对其效率进行显著下降。为此,在此场景下更推荐将`gtid_executed_compression_period`设置为0,故而`compress_gtid_table`线程将永远不被激活。
-
-`gtid_executed_compression_period`的默认值为0,且所有事务不论其所属存储引擎,都会被`clone_gitid_thread`写入到`mysql.gtid_exec uted`中。
-
-当server实例启动后,如果`gtid_executed_compression_preiod`被设置为非0值,并且`compress_gtid_table`线程也启动,在多数server配置中,将会对`msyql.gtid_executed`表执行显式压缩。压缩通过线程的启动触发。
-
-#### GTID生命周期
-GTID生命周期由如下步骤组成:
-1. 事务在source上被执行并提交,client transaction将会被分配GTID,GTID由`source UUID`和`smallest nonzero transaction sequence number not yet used on this server`组成。GTID也会被写入到binary log中(在log中,GTID被写入在事务之前)。如果client transaction没有被写入binary log(例如,事务被过滤或事务为read-only),那么该事务不会被分配GTID
-2. 如果为事务分配了GTID,那么在事务提交时GTID会被原子的持久化。在binary log中,GTID会被写入到事务开始的位置。不管何时,如果binary log发生rotation或server shutdown,server会将所有写入到binary log file中事务的GTIDs写入到`mysql.gtid_executed`表中
-3. 如果为事务分配了GTID,那么GTID的外部化是`non-atomically`的(在事务提交后非常短的时间)。外部化过程会将GTID添加到`gtid_executed` system variable所代表的GTID set中(`@@GLOBAL.gtid_executed`)。该GTID set中包含`representation of the set of all committed GTID transactions`,并且在replication中会作为代表server state的token使用。
- 1. 当binary logging启用时,`gtid_executed` system variable代表的GTIDs set是已被应用事务的完整记录。但是`mysql.gtid_executed`表则并记录所有GTIDs,可能由部分GTIDs仍存在于active binary log file中尚未被写入到gtid_executed table
-4. 在binary log data被转移到replica并存储在replica的relay log中后,replica会读取GTID的值,并且将其设置到`gtid_next` system variable中。这告知replica下一个事务将会使用`gtid_next`所代表的GTID。replica在session context中设置`gtid_next`
-5. replica在处理事务前,会验证没有其他线程已经持有了`gtid_next`中GTID的所有权。通过该方法,replica可以保证该该GTID关联的事务在replica上没有被应用过,并且还能保证没有其他session已经读取该GTID但是尚未提交关联事务。故而,如果并发的尝试应用相同的事务,那么server只会让其中的一个运行。
- 1. replica的`gtid_owned` system variable(`@@GLOBAL.gtid_owned`)代表了当前正在使用的每个GTID和拥有该GTID的线程ID。如果GTID已经被使用过,并不会抛出错误,`auto-skip`功能会忽略该事务
-6. 如果GTID尚未被使用,那么replica将会对replicated transaction进行应用。因为`gtid_next`被设置为了`由source分配的GTID`,replica将不会尝试为事务分配新的GTID,而是直接使用存储在`gtid_next`中存储的GTID
-7. 如果replica上启用了binary logging,GTID将会在提交时被原子的持久化,写入到binary log中事务开始的位置。无论何时,如果binary log发生rotation或server shutdown,server会将`先前写入到binary log中事务的GTIDs`写入到`mysql.gtid_executed`表中
-8. 如果replica禁用binary log,GTID将会原子的被持久化,直接被写入到`mysql.gtid_executed`表中。mysql会向事务中追加一个statement,并且将GTID插入到table中该操作是原子的,在该场景下,`mysql.gtid_executed`表记录了完整的`transactions applied on the replica`。
-9. 在replicated transaction提交后很短的时间,GTID会被非原子的externalized,GTID会被添加到replica的`gtid_executed` system variable代表的GTIDs中。在source中,`gtid_executed` system variable包含了所有提交的GTID事务。
-
-在source上被完全过滤的client transactions并不会被分配GTID,因此其不会被添加到`gtid_executed` system variable或被添加到`mysql.gtid_executed`表中。然而,replicated transaction中的GTIDs即使在replica被完全过滤,也会被持久化。
-- 如果binary logging在replica开启,被过滤的事务将会作为gtid_log_event的形式被写入到binary log,后续跟着一个empty transaction,事务中仅包含BEGIN和COMMIT语句
-- 如果binary logging在replica被禁用,给过滤事务的GTID将会被写入到`mysql.gtid_executed`表
-
-将filtered-out transactions的GTIDs保留,可以确保`mysql.gtid_executed`表和`gtid_executed`system variable中的GTIDs可以被压缩。同时其也能确保replica重新连接到source时,filtered-out transactions不会被重新获取
-
-在多线程的replica上(`replica_parallel_workers > 0`),事务可以被并行的应用,故而replicated transactions可以以不同的顺序来提交(除非`replica_preserve_commit_order = 1`)。在并行提交时,`gtid_executed`system variable中的GTIDs将包含多个GTID ranges,多个范围之间存在空隙。在多线程replicas上,只有最近被应用的事务间才会存在空隙,并且会随着replication的进行而被填充。当replication threads通过`STOP REPLICA`停止时,这些空隙会被填补。当发生shutdown event时(server failure导致),此时replication 停止,空隙仍可能保留。
-
-##### What changes are assign a GTID
-GTID生成的典型场景为`server为提交事务生成新的GTID`。然而,GTIDs可以被分配给除事务外的其他修改,且在某些场景下一个事务可以被分配多个GTIDs。
-
-每个写入binary log的数据库修改(`DDL/DML`)都会被分配一个GTID。其包含了自动提交的变更、使用`BEGIN...COMMIT`的变更和使用`START TRANSACTION`的变更。一个GTID会被分配给数据库的`creation, alteration, deletion`操作,并且`non-table` database object例如`procedure, function, trigger, event, view, user, role, grant`的`creation, alteration, deletion`也会被分配GTID。
-
-非事务更新和事务更新都会被分配`GTID`,额外的,对于非事务更新,如果在尝试写入binary log cahche时发生disk write failure,导致binary log中出现间隙,那么生成的日志事件将会被分配一个GTID。
-
-## Replication Implementation
-在replication的设计中,source server会追踪其binary log中所有对databases的修改。binary log中记录了自server启动时所有修改数据库结构或内容的事件。通常,`SELECT`语句将不会被记录,其并没有对数据库结构或内容造成修改。
-
-每个连接到source的replica都会请求binary log的副本,replica会从source处拉取数据,而不是source向replica推送数据。replica也会执行其从binary log收到的事件。`发生在source上的修改将会在replica上进行重现`。在重现过程中,会发生表创建、表结构修改、数据的新增/删除/修改等操作。
-
-由于每个replica都是独立的,每个连接到source的replica,其对`source中binary log`内容的replaying都是独立的。此外,因为每个replica只通过请求source来接收binary log的拷贝,replica能够以其自身的节奏来读取和更新其数据副本,并且其能在不对source和其他replicas造成影响的条件下开启或停止replication过程。
-
-### Replication Formats
-在binary log中,events根据其事件类型以不同的格式被记录。replication使用的foramts取决于事件被记录到source server的binary log中时所使用的foramt。binary log format和replciation过程中使用到的format,其关联关系如下:
-- 当使用statement-based binary logging时,source会将sql statements写入到binary log。从source到replica的replication将会在replica上执行该sql语句。这被称之为statement-based replication,关联了mysql statement-based binary logging format
-- 当使用row-based loggging时,source将会将`table rows如何变更`的事件写入到binary log中。在replica中,将会重现events对table rows所做的修改。则会被成为row-based replication
- - `row-based logging`是默认的方法
-- 可以配置mysql使用`mix-format logging`,但使用`mix-format logging`时,将默认使用statement-based log。但是对于特定的语句,也取决于使用的存储引擎,在某些床惊吓log也会被自动切换到row-based。使用mixed format的replication被称之为mix-based replication或mix-format replication
-
-mysql server中的logging format通过`binlog_format` system variable来进行控制。该变量可以在session/global级别进行设置
-- 在将variable设置为session级别时,将仅会对当前session生效,并且仅持续到当前session结束
-- 将variable设置为global级别时,该设置将会对`clients that connect after the change`生效,`但对于any current client sessions,包括.发出该修改请求的session都不生效`
-
-#### 使用statement-based和row-based replication的优缺点对比
-每个binary logging format都有优缺点。对大多数users,mixed replication format能够提供性能和数据完整性的最佳组合。
-
-##### Advantages of statement-based replication
-- 在使用statement-based格式时,会向log files中写入更少的数据。特别是在更新或删除大量行时,使用statement-based格式能够导致更少的空间占用。在从备份中获取和恢复时,其速度也更快
-- log files包含所有造成修改的statements,可以被用于审核database
-
-##### Disadvantages of statement-based replication
-- 对于Statement-based replication而言,statements并不是安全的。并非所有对数据造成修改的statements都可以使用statement-based replication。在使用statement-based replication时,任何非确定性的行为都难以复制(例如在语句中包含随机函数等非确定性行为)
-- 对于复杂语句,statement必须在实际对目标行执行修改前重新计算。而当使用row-based replication时,replica可以直接修改受影响行,而无需重新计算
-
-##### Advantages of row-based replication
-- 所有的修改可以被replicated,其是最安全的replication形式
-
-##### disadvantages of row-based replication
-- 相比于statement-based replication,row-based replication通常会向log中ieur更多数据,特别是当statement操作大量行数据是
-- 在replica并无法查看从source接收并执行的statements。可以通过`mysqlbinlog`的`--base64-output=DECODE-ROWS`和`--verbose`选项来查看数据变更
-
-### Replay Log and Replication Metadata Repositories
-replica server会创建一系列仓库,其中存储在replication过程中使用的信息;
-- `relay log`: 该日志被replication I/O线程写入,包含从source server的binary log读取的事务。relay log中记录的事务将会被replication SQL thread应用到replica
-- `connection metadata repository`: 包含replication receiver thread连接到source server并从binary log获取事务时,需要的信息。connection metadata repository会被写入到`mysql.slave_master_info`中
-- `applier metadata repository`: 包含replication applier thread从relay log读取并应用事务时所需要的信息。applier metadata repository会被写入到`mysql.slave_relay_log_info`表中
-
-#### The Relay Log
-relay log和binary log类似,由一些`numbered files`构成,文件中包含`描述数据库变更的事件`。relay log还包含一个index file,其中记录了所有被使用的relay log files的名称。默认情况下,relay log files位于data directory中
-
-relay log files拥有和binary log相同的格式,也可以通过mysqlbinlog进行读取。如果使用了binary log transaction compression,那么写入relay log的事务payloads也会按照和binary log相同的方式被压缩。
-
-对于默认的replication channel,relay log file命名形式如下`host_name-relay-bin.nnnnnn`:
-- `host_name`为replica server host的名称
-- `nnnnnn`是序列号,序列号从000001开始
-
-对于非默认的replication channels,默认的名称为`host_name-relay-bin-channel`:
-- `channel`为replciation channel的名称
-
-replica会使用index file来追踪当前在使用的relay log files。默认relay log index file的名称为`host_name-relay-bin.index`。
-
-当如下条件下,replica server将会创建新的relay log file:
-- 每次replication I/O thread开启时
-- 当logs被刷新时(例如,当执行`FLUSH LOGS`命令时)
-- 当当前relay log file的大小太大时,大小上限可以通过如下方式决定
- - 如果`max_relay_log_size`的大小大于0,那么其就是relay log file的最大大小
- - 如果`max_relay_log_size`为0,那么relay log file的最大大小由`max_binlog_size`决定
-
-replication sql thread在其执行完文件中所有events之后,都不再需要该文件,被执行完的relay log file都会被自动删除。目前没有显式的机制来删除relay logs,relay log的删除由replciation sql thread来处理。但是,`FLUSH LOGS`可以针对relay logs进行rotation。
-
-
+- [Replication](#replication)
+ - [Configuration Replication](#configuration-replication)
+ - [binary log file position based replication configuration overview](#binary-log-file-position-based-replication-configuration-overview)
+ - [Replication with Global Transaction Identifiers](#replication-with-global-transaction-identifiers)
+ - [GTID Format and Storage](#gtid-format-and-storage)
+ - [GTID Sets](#gtid-sets)
+ - [msyql.gtid\_executed](#msyqlgtid_executed)
+ - [mysql.gtid\_executed table compression](#mysqlgtid_executed-table-compression)
+ - [GTID生命周期](#gtid生命周期)
+ - [What changes are assign a GTID](#what-changes-are-assign-a-gtid)
+ - [Replication Implementation](#replication-implementation)
+ - [Replication Formats](#replication-formats)
+ - [使用statement-based和row-based replication的优缺点对比](#使用statement-based和row-based-replication的优缺点对比)
+ - [Advantages of statement-based replication](#advantages-of-statement-based-replication)
+ - [Disadvantages of statement-based replication](#disadvantages-of-statement-based-replication)
+ - [Advantages of row-based replication](#advantages-of-row-based-replication)
+ - [disadvantages of row-based replication](#disadvantages-of-row-based-replication)
+ - [Replay Log and Replication Metadata Repositories](#replay-log-and-replication-metadata-repositories)
+ - [The Relay Log](#the-relay-log)
+
+# Replication
+Replication允许数据从一个database server被复制到一个或多个mysql database servers(replicas)。replication默认是异步的;replicas并无需永久连接即可接收来自source的更新。基于configuration,可以针对所有的databases、选定的databases、甚至database中指定的tables进行replicate。
+
+mysql中replication包含如下优点:
+- 可拓展方案:可以将负载分散到多个replicas,从而提升性能。在该环境中,所有的writes和updates都发生在source server。但是,reads则是可以发生在一个或多个replicas上。通过该模型,能够提升writes的性能(因为source专门用于更新),并可以通过增加replicas的数量来提高read speed
+- data security: 因为replica可以暂停replication过程,故而可以在replica中运行备份服务,而不会破坏对应的source data
+- analytics:实时数据可以在source中生成,而对信息的分析则可以发生在replica,分析过程不会影响source的性能
+- long-distance data distribution:可以replication来对remote site创建一个local copy,而无需对source的永久访问
+
+在mysql 8.4中,支持不同的replication方式。
+- 传统方式基于从source的binary log中复制事件,并且需要log files和`在source和replica之间进行同步的position`。
+- 新的replication方式基于global transaction identifiers(GTIDs),是事务的,并且不需要和log files、position进行交互,其大大简化了许多通用的replication任务。使用GTIDs的replication保证了source和replica的一致性,所有在source提交的事务都会在replica被应用。
+
+mysql中的replication支持不同类型的同步。
+- 原始的同步是单向、异步的复制,一个server作为source、其他一个或多个servers作为replicas。
+- NDB Cluster中,支持synchronous replication
+- 在mysql 8.4中,支持了半同步复制,通过半同步复制,在source中执行的提交将会被阻塞,直到至少一个replica收到transaction并对transaction进行log event,且向source发送ack
+- mysql 8.4同样支持delayed replication,使得replica故意落后于source至少指定的时间
+
+## Configuration Replication
+### binary log file position based replication configuration overview
+在该section中,会描述mysql servers间基于binary log file position的replication方案。(source会将database的writes和updates操作以events的形式写入到binary log中)。根据database记录的变更,binary log中的信息将会以不同的logging format存储。replicas可以被配置,从source的binary log读取events,并且在replica本地的binary log中执行时间。
+
+每个replica都会接收binary log的完整副本内容,并由replica来决定binary log中哪些statements应当被执行。除非你显式指定,否则binary log中所有的events都会在replica上被执行。如果需要,你可以对replica进行配置,仅处理应用于特定databases、tables的events。
+
+每个replica都会记录二进制日志的坐标:其已经从source读取并处理的file name和文件中的position。这代表多个replicas可以连接到source,并执行相同binary log的不同部分。由于该过程受replicas控制,故而独立的replicas可以和source建立连接、取消连接,并且不会影响到source的操作。并且,每个replica记录了binary log的当前position,replica可以断开连接、重新连接并重启之前的过程。
+
+source和每个replica都配置了unique ID(使用`server_id` system variable),除此之外,每个replica必须配置如下信息:
+- source's host name
+- source's log file name
+- position of source's file
+
+这些可以在replica的mysql session内通过`CHANGE REPLICATION SOURCE TO`语句来管理,并且这些信息存储在replica的connection metadata repository中。
+
+### Replication with Global Transaction Identifiers
+在该章节中,描述了使用global transaction identifiers(GTIDs)的transaction-based replication。当使用GTIDs时,每个在source上提交的事务都可以被标识和追踪,并可以被任一replica应用。
+
+在使用GTIDs时,启动新replica或failover to a new source时并不需要参照log files或file position。由于GTIDs时完全transaction-based的,其更容易判断是否source和replicas一致,只要在source中提交的事务全部也都在replica上提交,那么source和replica则是保证一致的。
+
+在使用GTIDs时,可以选择是statement-based的还是row-based的,推荐使用row-based format。
+
+GTIDs在source和replica都是持久化的。总是可以通过检测binary log来判断是否source中的任一事务是否在replica上被应用。此外,一旦给定GTID的事务在给定server上被提交,那么后续任一事务如果拥有相同的GTID,其都会被server忽略。因此,在source上被提交的事务可以在replica上应用多次,冗余的应用会被忽略,其可以保证数据的一致性。
+
+#### GTID Format and Storage
+一个global transation identifier(GTID)是一个唯一标识符,该标识符的创建并和`source上提交的每一个事务`进行关联。GTID不仅在创建其的server上是唯一的,并且在给定replication拓扑的所有servers间是唯一的。
+
+GTID的分配区分了client trasactions(在source上提交的事务)以及replicated transactions(在replica上reproduced的事务)。当client transaction在source上提交时,如果transaction被写入到binary log中,其会被分配一个新的GTID。client transactions将会被保证单调递增,并且生成的编号之间不会存在间隙。`如果client transaction没有被写入到binary log,那么其在source中并不会被分配GTID`。
+
+Replicated transaction将会使用`事务被source server分配的GTID`。在replicated transaction开始执行前,GTID就已经存在,并且,即使replicated transaction没有写入到replica的binary log中或是被replica过滤,该GTID也会被持久化。`mysql.gtid_executed` system table将会被用于保存`应用到给定server的所有事务的GTID,但是,已经存储到当前active binary log file的除外`。
+
+> `active binary log file`中的gtid最终也会被写入到`gtid_executed`表中,但是,对于不同的存储引擎,写入时机可能不同。对于innodb而言,在事务提交时就会写入gtid_executed表,而对于其他存储引擎而言,则会在binary log发生rotation/server shutdown后才会将active binary log中尚未写入的GTIDs写入到`mysql.gtid_executed`表
+
+GTIDs的auto-skip功能代表一个在source上提交的事务最多只能在replica上应用一次,这有助于保证一致性。一旦拥有给定GTID的事务在给定server上被提交,任何后续执行的事务如果拥有相同的GTID,都会被server忽略。并不会抛出异常,并且事务中的statements都不会被实际执行。
+
+如果拥有给定GTID的事务在server上已经开始执行,但是尚未提交或回滚,那么任何尝试开启一个`拥有相同GTID事务的操作都会被阻塞`。该server并不会开始执行拥有相同GTID的事务,也不会将控制权交还给client。一旦第一个事务提交或回滚,那么被阻塞的事务就可以开始执行。如果第一次执行被回滚,那么被阻塞事务可以实际执行;如果第一个事务成功提交,那么被阻塞事务并不会被实际执行,而是会被自动跳过。
+
+GTID的表示形式如下:
+```
+GTID = source_id:transaction_id
+```
+- `source_id`表示了originating server,通常为source的`server_uuid`
+- `transaction_id`则是一个由`transaction在source上提交顺序`决定的序列号。例如,第一个被提交的事务,其transaction_id为1;而第十个被提交的事务,其transaction_id则是为10.
+ - 在GTID中,transaction_id部分的值不可能为0
+
+例如,在UUID为`3E11FA47-71CA-11E1-9E33-C80AA9429562`上的server提交的第23个事务,其GTID为
+```
+3E11FA47-71CA-11E1-9E33-C80AA9429562:23
+```
+
+在GTID中,序列号的上限值为`2^63 - 1, or 9223372036854775807`(signed 64-bit integer)。如果server运行时超过GTIDs,其将执行`binlog_error_action`指定的行为。当server接近该限制时,会发出一个warning message。
+
+在mysql 8.4中,也支持tagged GTIDs,一个tagged GTID由三部分组成,通过`:`进行分隔,示例如下所示:
+```
+GTID = source_id:tag:transaction_id
+```
+
+在该示例中,`source_id`和`transaction_id`的含义和先前相同,`tag`则是一个用户自定义的字符串,用于表示`specific group of transactions`。
+
+例如,在UUID为`ed102faf-eb00-11eb-8f20-0c5415bfaa1d`的server上第117个提交的tag为`Domain_1`的事务,其GTID为
+```
+ed102faf-eb00-11eb-8f20-0c5415bfaa1d:Domain_1:117
+```
+
+事务的GTID会展示在`mysqlbinlog`的输出中,用于分辨`performance schema replication status tables`中独立的事务,例如`replication_applier_status_by_worker`表。
+
+`gtid_next` system variable的值是单个GTID。
+
+##### GTID Sets
+一个GTID set由`一个或多个GTIDs`或`GTIDs`范围构成。`gtid_executed`或`gtid_purged` system variables存储的就是GTID sets。`START REPLICA`选项`UNTIL SQL_BEFORE_GTIDS`和`UNTIL SQL_AFTER_GTIDS`可令replica在处理事务时,`最多只处理到GTID set中的第一个GTID`或`在处理完GTID set中的最后一个GTID后停止`。内置的`GTID_SUBSET()`和`GTID_SUBTRACT()`函数需要`GTID sets`作为输入。
+
+在相同server上的GTIDs范围可以按照如下形式来表示:
+```
+3E11FA47-71CA-11E1-9E33-C80AA9429562:1-5
+```
+上述示例表示在uuid为`3E11FA47-71CA-11E1-9E33-C80AA9429562`的server上提交的顺序为`1~5`之间的事务。
+
+相同server上的多个single GTIDs或ranges of GTIDs可以通过如下形式来表示
+```
+3E11FA47-71CA-11E1-9E33-C80AA9429562:1-3:11:47-49
+```
+
+GTID set可以包含任意`single GTIDs`和`GTIDs range`的组合,也可以包含来自不同server的GTIDs。如下实例中展示了`gtid_executed` system variable中存储的GTID set,代表replica中应用了来自超过一个source的事务:
+```
+2174B383-5441-11E8-B90A-C80AA9429562:1-3, 24DA167-0C0C-11E8-8442-00059A3C7B00:1-19
+```
+当GTID set从server variables中返回时,UUID按照字母排序返回,而序列号间区间则是合并后按照升序排列。
+
+当构建GTID set时,用户自定义tag也会被作为UUID的一部分,这代表来自相同server且tag相同的多个GTIDs可以被包含在一个表达式中,如下所示:
+```
+3E11FA47-71CA-11E1-9E33-C80AA9429562:Domain_1:1-3:11:47-49
+```
+来源相同server,但是tags不同的GTIDs表示方式如下:
+```
+3E11FA47-71CA-11E1-9E33-C80AA9429562:Domain_1:1-3:15-21, 3E11FA47-71CA-11E1-9E33-C80AA9429562:Domain_2:8-52
+```
+
+GTID set的完整语法如下所示:
+```
+gtid_set:
+ uuid_set [, uuid_set] ...
+ | ''
+
+uuid_set:
+ uuid:[tag:]interval[:interval]...
+
+uuid:
+ hhhhhhhh-hhhh-hhhh-hhhh-hhhhhhhhhhhh
+
+h:
+ [0-9|A-F]
+
+tag:
+ [a-z_][a-z0-9_]{0,31}
+
+interval:
+ m[-n]
+
+ (m >= 1; n > m)
+```
+##### msyql.gtid_executed
+GTIDs被存储在`mysql.gtid_executed`表中,该表中的行用于表示GTID或GTID set,行包含信息如下
+- source server的uuid
+- 用户自定义的tag
+- starting transaction IDs of the set
+- ending transaction IDs of the set
+
+如果行代表single GTID,那么最后两个字段的值相同。
+
+`mysql.gtid_executed`表在mysql server安装或升级时会被自动创建,其表结构如下:
+```sql
+CREATE TABLE gtid_executed (
+ source_uuid CHAR(36) NOT NULL,
+ interval_start BIGINT NOT NULL,
+ interval_end BIGINT NOT NULL,
+ gtid_tag CHAR(32) NOT NULL,
+ PRIMARY KEY (source_uuid, gtid_tag, interval_start)
+);
+```
+
+`mysql.gtid_executed`用于mysql server内部使用,其允许replica在binary logging被禁用的情况下使用GTIDs,其也可以在binary logs丢失时保留GTID的状态。如果执行`RESET BINARY LOGS AND GTIDS`,那么`mysql.gtid_executed`表将会被清空。
+
+只有当`gtid_mode`被设置为`ON`或`ON_PERMISSIVE`时,GTIDs才会被存储到mysql.gtid_executed中。如果binary logging被禁用,或者`log_replica_updates`被禁用,server在事务提交时将会把属于个各事务的GTID和事务一起存储到buffer中,并且background threads将会周期性将buffer中的内容以entries的形式添加到`mysql.gtid_executed`表中。
+
+对于innodb存储引擎而言,如果binary logging被启用,server更新`mysql.gtid_executed`表的方式将会和`binary logging或replica update logging被启用`时一样,都会在每个事务提交时存储GTID。对于其他存储引擎,则是在binary log rotation发生时或server shut down时更新`mysql.gtid_executed`表的内容。
+
+如果mysql.gtid_executed表无法被写访问,并且binary log file因`reaching the maximum file size`之外的任何理由被rotated,那么current binary log file将仍被使用。并且,当client发起rotation时将会返回错误信息,并且server将会输出warning日志。如果`mysql.gtid_executed`无法被写访问,并且binary log单个文件大小达到`max_binlog_size`,那么server将会根据`binlog_error_action`设置来执行操作。如果`IGNORE_ERROR`被设置,那么server将会输出error到日志,并且binary logging将会被停止;如果`ABORT_SERVER`被设置,那么server将会shutdown。
+
+> 因为写入到active binary log的GTIDs最终也要被写入`mysql.gtid_executed`表,但是该表若当前不可写访问,那么此时将无法触发`binary log rotation`。
+>
+> MySQL.gtid_executed中缺失的GTIDs必须包含在active binary log file中,如果log file触发rotation,但是无法向mysql.gtid_executed中写入数据,那么rotation是不被允许的。
+
+
+##### mysql.gtid_executed table compression
+随着时间的推移,mysql.gtid_executed表会填满大量行,行数据代表独立的GTID,示例如下:
+```
++--------------------------------------+----------------+--------------+----------+
+| source_uuid | interval_start | interval_end | gtid_tag |
+|--------------------------------------+----------------+--------------|----------+
+| 3E11FA47-71CA-11E1-9E33-C80AA9429562 | 31 | 31 | Domain_1 |
+| 3E11FA47-71CA-11E1-9E33-C80AA9429562 | 32 | 32 | Domain_1 |
+| 3E11FA47-71CA-11E1-9E33-C80AA9429562 | 33 | 33 | Domain_1 |
+| 3E11FA47-71CA-11E1-9E33-C80AA9429562 | 34 | 34 | Domain_1 |
+| 3E11FA47-71CA-11E1-9E33-C80AA9429562 | 35 | 35 | Domain_1 |
+| 3E11FA47-71CA-11E1-9E33-C80AA9429562 | 36 | 36 | Domain_2 |
+| 3E11FA47-71CA-11E1-9E33-C80AA9429562 | 37 | 37 | Domain_2 |
+| 3E11FA47-71CA-11E1-9E33-C80AA9429562 | 38 | 38 | Domain_2 |
+| 3E11FA47-71CA-11E1-9E33-C80AA9429562 | 39 | 39 | Domain_2 |
+| 3E11FA47-71CA-11E1-9E33-C80AA9429562 | 40 | 40 | Domain_1 |
+| 3E11FA47-71CA-11E1-9E33-C80AA9429562 | 41 | 41 | Domain_1 |
+| 3E11FA47-71CA-11E1-9E33-C80AA9429562 | 42 | 42 | Domain_1 |
+| 3E11FA47-71CA-11E1-9E33-C80AA9429562 | 43 | 43 | Domain_1 |
+| 3E11FA47-71CA-11E1-9E33-C80AA9429562 | 44 | 44 | Domain_2 |
+| 3E11FA47-71CA-11E1-9E33-C80AA9429562 | 45 | 45 | Domain_2 |
+| 3E11FA47-71CA-11E1-9E33-C80AA9429562 | 46 | 46 | Domain_2 |
+| 3E11FA47-71CA-11E1-9E33-C80AA9429562 | 47 | 47 | Domain_1 |
+| 3E11FA47-71CA-11E1-9E33-C80AA9429562 | 48 | 48 | Domain_1 |
+```
+
+为了节省空间,可以对gtid_executed表周期性的进行压缩,将多个`single GTID`替换为单个`GTID set`,压缩后的数据如下;
+```
++--------------------------------------+----------------+--------------+----------+
+| source_uuid | interval_start | interval_end | gtid_tag |
+|--------------------------------------+----------------+--------------|----------+
+| 3E11FA47-71CA-11E1-9E33-C80AA9429562 | 31 | 35 | Domain_1 |
+| 3E11FA47-71CA-11E1-9E33-C80AA9429562 | 36 | 39 | Domain_2 |
+| 3E11FA47-71CA-11E1-9E33-C80AA9429562 | 40 | 43 | Domain_1 |
+| 3E11FA47-71CA-11E1-9E33-C80AA9429562 | 44 | 46 | Domain_2 |
+| 3E11FA47-71CA-11E1-9E33-C80AA9429562 | 47 | 48 | Domain_1 |
+...
+```
+server可通过名为`thread/sql/compress_gtid_table`的前台线程来执行gtid_executed表的压缩操作,该线程并不会在`show processlist`的输出中被列出,但是可以通过查询`threads`表来查看,示例如下:
+```sql
+mysql> SELECT * FROM performance_schema.threads WHERE NAME LIKE '%gtid%'\G
+*************************** 1. row ***************************
+ THREAD_ID: 26
+ NAME: thread/sql/compress_gtid_table
+ TYPE: FOREGROUND
+ PROCESSLIST_ID: 1
+ PROCESSLIST_USER: NULL
+ PROCESSLIST_HOST: NULL
+ PROCESSLIST_DB: NULL
+PROCESSLIST_COMMAND: Daemon
+ PROCESSLIST_TIME: 1509
+ PROCESSLIST_STATE: Suspending
+ PROCESSLIST_INFO: NULL
+ PARENT_THREAD_ID: 1
+ ROLE: NULL
+ INSTRUMENTED: YES
+ HISTORY: YES
+ CONNECTION_TYPE: NULL
+ THREAD_OS_ID: 18677
+```
+当server启用了binary log时,上述压缩方式并不会被使用,`mysql.gtid_executed`在每次binary log rotation时会被压缩。但是,当binary logging被禁用时,`thread/sql/compress_gtid`线程处于sleep状态,每有一定数量的事务被执行时,线程会wake up并执行压缩操作。在table被压缩之前经过的事务数量,即压缩率,可由system variable `gtid_executed_compression_period`来进行控制。如果将值设置为0,代表该thread永远不会wake up。
+
+相比于其他存储引擎,innodb事务写入`mysql.gtid_executed`的过程有所不同,在innodb存储引擎中,过程通过线程`innodb/clone_gtid_thread`来执行。此GTID持久化线程将会分组收集GTIDs,并将其刷新到`mysql.gtid_executed`表中,并对table进行压缩。如果server中既包含innodb事务,又包含non-innodb事务,那么由`compress_gtid_table`线程执行的压缩操作将会干扰`clone_gtid_thread`的工作,并对其效率进行显著下降。为此,在此场景下更推荐将`gtid_executed_compression_period`设置为0,故而`compress_gtid_table`线程将永远不被激活。
+
+`gtid_executed_compression_period`的默认值为0,且所有事务不论其所属存储引擎,都会被`clone_gitid_thread`写入到`mysql.gtid_exec uted`中。
+
+当server实例启动后,如果`gtid_executed_compression_preiod`被设置为非0值,并且`compress_gtid_table`线程也启动,在多数server配置中,将会对`msyql.gtid_executed`表执行显式压缩。压缩通过线程的启动触发。
+
+#### GTID生命周期
+GTID生命周期由如下步骤组成:
+1. 事务在source上被执行并提交,client transaction将会被分配GTID,GTID由`source UUID`和`smallest nonzero transaction sequence number not yet used on this server`组成。GTID也会被写入到binary log中(在log中,GTID被写入在事务之前)。如果client transaction没有被写入binary log(例如,事务被过滤或事务为read-only),那么该事务不会被分配GTID
+2. 如果为事务分配了GTID,那么在事务提交时GTID会被原子的持久化。在binary log中,GTID会被写入到事务开始的位置。不管何时,如果binary log发生rotation或server shutdown,server会将所有写入到binary log file中事务的GTIDs写入到`mysql.gtid_executed`表中
+3. 如果为事务分配了GTID,那么GTID的外部化是`non-atomically`的(在事务提交后非常短的时间)。外部化过程会将GTID添加到`gtid_executed` system variable所代表的GTID set中(`@@GLOBAL.gtid_executed`)。该GTID set中包含`representation of the set of all committed GTID transactions`,并且在replication中会作为代表server state的token使用。
+ 1. 当binary logging启用时,`gtid_executed` system variable代表的GTIDs set是已被应用事务的完整记录。但是`mysql.gtid_executed`表则并记录所有GTIDs,可能由部分GTIDs仍存在于active binary log file中尚未被写入到gtid_executed table
+4. 在binary log data被转移到replica并存储在replica的relay log中后,replica会读取GTID的值,并且将其设置到`gtid_next` system variable中。这告知replica下一个事务将会使用`gtid_next`所代表的GTID。replica在session context中设置`gtid_next`
+5. replica在处理事务前,会验证没有其他线程已经持有了`gtid_next`中GTID的所有权。通过该方法,replica可以保证该该GTID关联的事务在replica上没有被应用过,并且还能保证没有其他session已经读取该GTID但是尚未提交关联事务。故而,如果并发的尝试应用相同的事务,那么server只会让其中的一个运行。
+ 1. replica的`gtid_owned` system variable(`@@GLOBAL.gtid_owned`)代表了当前正在使用的每个GTID和拥有该GTID的线程ID。如果GTID已经被使用过,并不会抛出错误,`auto-skip`功能会忽略该事务
+6. 如果GTID尚未被使用,那么replica将会对replicated transaction进行应用。因为`gtid_next`被设置为了`由source分配的GTID`,replica将不会尝试为事务分配新的GTID,而是直接使用存储在`gtid_next`中存储的GTID
+7. 如果replica上启用了binary logging,GTID将会在提交时被原子的持久化,写入到binary log中事务开始的位置。无论何时,如果binary log发生rotation或server shutdown,server会将`先前写入到binary log中事务的GTIDs`写入到`mysql.gtid_executed`表中
+8. 如果replica禁用binary log,GTID将会原子的被持久化,直接被写入到`mysql.gtid_executed`表中。mysql会向事务中追加一个statement,并且将GTID插入到table中该操作是原子的,在该场景下,`mysql.gtid_executed`表记录了完整的`transactions applied on the replica`。
+9. 在replicated transaction提交后很短的时间,GTID会被非原子的externalized,GTID会被添加到replica的`gtid_executed` system variable代表的GTIDs中。在source中,`gtid_executed` system variable包含了所有提交的GTID事务。
+
+在source上被完全过滤的client transactions并不会被分配GTID,因此其不会被添加到`gtid_executed` system variable或被添加到`mysql.gtid_executed`表中。然而,replicated transaction中的GTIDs即使在replica被完全过滤,也会被持久化。
+- 如果binary logging在replica开启,被过滤的事务将会作为gtid_log_event的形式被写入到binary log,后续跟着一个empty transaction,事务中仅包含BEGIN和COMMIT语句
+- 如果binary logging在replica被禁用,给过滤事务的GTID将会被写入到`mysql.gtid_executed`表
+
+将filtered-out transactions的GTIDs保留,可以确保`mysql.gtid_executed`表和`gtid_executed`system variable中的GTIDs可以被压缩。同时其也能确保replica重新连接到source时,filtered-out transactions不会被重新获取
+
+在多线程的replica上(`replica_parallel_workers > 0`),事务可以被并行的应用,故而replicated transactions可以以不同的顺序来提交(除非`replica_preserve_commit_order = 1`)。在并行提交时,`gtid_executed`system variable中的GTIDs将包含多个GTID ranges,多个范围之间存在空隙。在多线程replicas上,只有最近被应用的事务间才会存在空隙,并且会随着replication的进行而被填充。当replication threads通过`STOP REPLICA`停止时,这些空隙会被填补。当发生shutdown event时(server failure导致),此时replication 停止,空隙仍可能保留。
+
+##### What changes are assign a GTID
+GTID生成的典型场景为`server为提交事务生成新的GTID`。然而,GTIDs可以被分配给除事务外的其他修改,且在某些场景下一个事务可以被分配多个GTIDs。
+
+每个写入binary log的数据库修改(`DDL/DML`)都会被分配一个GTID。其包含了自动提交的变更、使用`BEGIN...COMMIT`的变更和使用`START TRANSACTION`的变更。一个GTID会被分配给数据库的`creation, alteration, deletion`操作,并且`non-table` database object例如`procedure, function, trigger, event, view, user, role, grant`的`creation, alteration, deletion`也会被分配GTID。
+
+非事务更新和事务更新都会被分配`GTID`,额外的,对于非事务更新,如果在尝试写入binary log cahche时发生disk write failure,导致binary log中出现间隙,那么生成的日志事件将会被分配一个GTID。
+
+## Replication Implementation
+在replication的设计中,source server会追踪其binary log中所有对databases的修改。binary log中记录了自server启动时所有修改数据库结构或内容的事件。通常,`SELECT`语句将不会被记录,其并没有对数据库结构或内容造成修改。
+
+每个连接到source的replica都会请求binary log的副本,replica会从source处拉取数据,而不是source向replica推送数据。replica也会执行其从binary log收到的事件。`发生在source上的修改将会在replica上进行重现`。在重现过程中,会发生表创建、表结构修改、数据的新增/删除/修改等操作。
+
+由于每个replica都是独立的,每个连接到source的replica,其对`source中binary log`内容的replaying都是独立的。此外,因为每个replica只通过请求source来接收binary log的拷贝,replica能够以其自身的节奏来读取和更新其数据副本,并且其能在不对source和其他replicas造成影响的条件下开启或停止replication过程。
+
+### Replication Formats
+在binary log中,events根据其事件类型以不同的格式被记录。replication使用的foramts取决于事件被记录到source server的binary log中时所使用的foramt。binary log format和replciation过程中使用到的format,其关联关系如下:
+- 当使用statement-based binary logging时,source会将sql statements写入到binary log。从source到replica的replication将会在replica上执行该sql语句。这被称之为statement-based replication,关联了mysql statement-based binary logging format
+- 当使用row-based loggging时,source将会将`table rows如何变更`的事件写入到binary log中。在replica中,将会重现events对table rows所做的修改。则会被成为row-based replication
+ - `row-based logging`是默认的方法
+- 可以配置mysql使用`mix-format logging`,但使用`mix-format logging`时,将默认使用statement-based log。但是对于特定的语句,也取决于使用的存储引擎,在某些床惊吓log也会被自动切换到row-based。使用mixed format的replication被称之为mix-based replication或mix-format replication
+
+mysql server中的logging format通过`binlog_format` system variable来进行控制。该变量可以在session/global级别进行设置
+- 在将variable设置为session级别时,将仅会对当前session生效,并且仅持续到当前session结束
+- 将variable设置为global级别时,该设置将会对`clients that connect after the change`生效,`但对于any current client sessions,包括.发出该修改请求的session都不生效`
+
+#### 使用statement-based和row-based replication的优缺点对比
+每个binary logging format都有优缺点。对大多数users,mixed replication format能够提供性能和数据完整性的最佳组合。
+
+##### Advantages of statement-based replication
+- 在使用statement-based格式时,会向log files中写入更少的数据。特别是在更新或删除大量行时,使用statement-based格式能够导致更少的空间占用。在从备份中获取和恢复时,其速度也更快
+- log files包含所有造成修改的statements,可以被用于审核database
+
+##### Disadvantages of statement-based replication
+- 对于Statement-based replication而言,statements并不是安全的。并非所有对数据造成修改的statements都可以使用statement-based replication。在使用statement-based replication时,任何非确定性的行为都难以复制(例如在语句中包含随机函数等非确定性行为)
+- 对于复杂语句,statement必须在实际对目标行执行修改前重新计算。而当使用row-based replication时,replica可以直接修改受影响行,而无需重新计算
+
+##### Advantages of row-based replication
+- 所有的修改可以被replicated,其是最安全的replication形式
+
+##### disadvantages of row-based replication
+- 相比于statement-based replication,row-based replication通常会向log中ieur更多数据,特别是当statement操作大量行数据是
+- 在replica并无法查看从source接收并执行的statements。可以通过`mysqlbinlog`的`--base64-output=DECODE-ROWS`和`--verbose`选项来查看数据变更
+
+### Replay Log and Replication Metadata Repositories
+replica server会创建一系列仓库,其中存储在replication过程中使用的信息;
+- `relay log`: 该日志被replication I/O线程写入,包含从source server的binary log读取的事务。relay log中记录的事务将会被replication SQL thread应用到replica
+- `connection metadata repository`: 包含replication receiver thread连接到source server并从binary log获取事务时,需要的信息。connection metadata repository会被写入到`mysql.slave_master_info`中
+- `applier metadata repository`: 包含replication applier thread从relay log读取并应用事务时所需要的信息。applier metadata repository会被写入到`mysql.slave_relay_log_info`表中
+
+#### The Relay Log
+relay log和binary log类似,由一些`numbered files`构成,文件中包含`描述数据库变更的事件`。relay log还包含一个index file,其中记录了所有被使用的relay log files的名称。默认情况下,relay log files位于data directory中
+
+relay log files拥有和binary log相同的格式,也可以通过mysqlbinlog进行读取。如果使用了binary log transaction compression,那么写入relay log的事务payloads也会按照和binary log相同的方式被压缩。
+
+对于默认的replication channel,relay log file命名形式如下`host_name-relay-bin.nnnnnn`:
+- `host_name`为replica server host的名称
+- `nnnnnn`是序列号,序列号从000001开始
+
+对于非默认的replication channels,默认的名称为`host_name-relay-bin-channel`:
+- `channel`为replciation channel的名称
+
+replica会使用index file来追踪当前在使用的relay log files。默认relay log index file的名称为`host_name-relay-bin.index`。
+
+当如下条件下,replica server将会创建新的relay log file:
+- 每次replication I/O thread开启时
+- 当logs被刷新时(例如,当执行`FLUSH LOGS`命令时)
+- 当当前relay log file的大小太大时,大小上限可以通过如下方式决定
+ - 如果`max_relay_log_size`的大小大于0,那么其就是relay log file的最大大小
+ - 如果`max_relay_log_size`为0,那么relay log file的最大大小由`max_binlog_size`决定
+
+replication sql thread在其执行完文件中所有events之后,都不再需要该文件,被执行完的relay log file都会被自动删除。目前没有显式的机制来删除relay logs,relay log的删除由replciation sql thread来处理。但是,`FLUSH LOGS`可以针对relay logs进行rotation。
+
+
diff --git a/spring/Spring Cloud/Spring Cloud.md b/spring/Spring Cloud/Spring Cloud.md
index 220745c..2812075 100644
--- a/spring/Spring Cloud/Spring Cloud.md
+++ b/spring/Spring Cloud/Spring Cloud.md
@@ -1,33 +1,33 @@
-# Spring Cloud简介
-## eureka
-eureka是由netflix公司开源的一个服务注册与发现组件。eureka和其他一些同样由netflix公司开源的组建一起被整合为spring cloud netflix模块。
-### eureka和zookeeper的区别
-#### CAP原则
-CAP原则指的是在一个分布式系统中,一致性(Consistency)、可用性(Aailability)和分区容错性(Partition Tolerance),三者中最多只能实现两者,无法实现三者兼顾。
-- C:一致性表示分布式系统中,不同节点中的数据都要相同
-- A:可用性代表可以允许某一段时间内分布式系统中不同节点的数据可以不同,只要分布式系统能够保证最终数据的一致性。中途,允许分布式系统中的节点数据存在不一致的情形
-- P:及Partition Tolerance,通常情况下,节点之间的网络的断开被称之为network partition。故而,partition tolerance则是能够保证即使发生network partition,分布式系统中的节点也能够继续运行
-
-通常P是必选的,而在满足P的前提下,A和C只能够满足一条,即AP或CP。
-#### zookeeper遵循的原则
-zookeeper遵循的是cp原则,如果zookeeper集群中的leader宕机,那么在新leader选举出来之前,zookeeper集群是拒绝向外提供服务的。
-#### eureka遵循的原则
-和zookeeper不同,eureka遵循的是ap原则,这这意味着eureka允许多个节点之间存在数据不一致的情况,即使某个节点的宕机,eureka仍然能够向外提供服务。
-
-### eureka使用
-可以通过向项目中添加eureka-server的依赖来启动一个eureka-server实例。eureka-server作为注册中心,会将其本身也作为一个服务注册到注册中心中。
-#### 注册实例id
-注册实例id由三部分组成,`主机名称:应用名称:端口号`构成了实例的id。每个实例id都唯一。
-#### eureka-server配置
-- eviction-interval-timer-in-ms:eureka-server会运行固定的scheduled task来清除过期的client,eviction-interval-timer-in-ms属性用于定义task之间的间隔,默认情况下该属性值为60s
-- renewal-percent-threshold:基于该属性,eureka来计算每分钟期望从所有客户端接受到的心跳数。根据eureka-server的自我保护机制,如果eureka-server收到的心跳数小于threshold,那么eureka-server会停止进行客户端实例的淘汰,直到接收到的心跳数大于threshold
-#### eureka-instance配置
-eureka-server-instance本身也作为一个instance注册到注册中心中,故而可以针对eureka-instance作一些配置。
-#### eureka集群
-eureka集群是去中心化的集群,没有主机和从机的概念,eureka节点会向集群中所有其他的节点广播数据的变动。
-## Ribbon
-Spring Cloud Ribbon是一个基于Http和Tcp的客户端负载均衡工具,基于Netflix Ribbon实现,Ribbon主要用于提供负载均衡算法和服务调用。Ribbon的客户端组件提供了一套完善的配置项,如超时和重试等。
-在通过Spring Cloud构建微服务时,Ribbon有两种使用方法,一种是和RedisTemplate结合使用,另一种是和OpenFegin相结合。
-## OpenFeign
-OpenFeign是一个远程调用组件,使用接口和注解以http的形式完成调用。
-Feign中集成了Ribbon,而Ribbon中则集成了eureka。
+# Spring Cloud简介
+## eureka
+eureka是由netflix公司开源的一个服务注册与发现组件。eureka和其他一些同样由netflix公司开源的组建一起被整合为spring cloud netflix模块。
+### eureka和zookeeper的区别
+#### CAP原则
+CAP原则指的是在一个分布式系统中,一致性(Consistency)、可用性(Aailability)和分区容错性(Partition Tolerance),三者中最多只能实现两者,无法实现三者兼顾。
+- C:一致性表示分布式系统中,不同节点中的数据都要相同
+- A:可用性代表可以允许某一段时间内分布式系统中不同节点的数据可以不同,只要分布式系统能够保证最终数据的一致性。中途,允许分布式系统中的节点数据存在不一致的情形
+- P:及Partition Tolerance,通常情况下,节点之间的网络的断开被称之为network partition。故而,partition tolerance则是能够保证即使发生network partition,分布式系统中的节点也能够继续运行
+
+通常P是必选的,而在满足P的前提下,A和C只能够满足一条,即AP或CP。
+#### zookeeper遵循的原则
+zookeeper遵循的是cp原则,如果zookeeper集群中的leader宕机,那么在新leader选举出来之前,zookeeper集群是拒绝向外提供服务的。
+#### eureka遵循的原则
+和zookeeper不同,eureka遵循的是ap原则,这这意味着eureka允许多个节点之间存在数据不一致的情况,即使某个节点的宕机,eureka仍然能够向外提供服务。
+
+### eureka使用
+可以通过向项目中添加eureka-server的依赖来启动一个eureka-server实例。eureka-server作为注册中心,会将其本身也作为一个服务注册到注册中心中。
+#### 注册实例id
+注册实例id由三部分组成,`主机名称:应用名称:端口号`构成了实例的id。每个实例id都唯一。
+#### eureka-server配置
+- eviction-interval-timer-in-ms:eureka-server会运行固定的scheduled task来清除过期的client,eviction-interval-timer-in-ms属性用于定义task之间的间隔,默认情况下该属性值为60s
+- renewal-percent-threshold:基于该属性,eureka来计算每分钟期望从所有客户端接受到的心跳数。根据eureka-server的自我保护机制,如果eureka-server收到的心跳数小于threshold,那么eureka-server会停止进行客户端实例的淘汰,直到接收到的心跳数大于threshold
+#### eureka-instance配置
+eureka-server-instance本身也作为一个instance注册到注册中心中,故而可以针对eureka-instance作一些配置。
+#### eureka集群
+eureka集群是去中心化的集群,没有主机和从机的概念,eureka节点会向集群中所有其他的节点广播数据的变动。
+## Ribbon
+Spring Cloud Ribbon是一个基于Http和Tcp的客户端负载均衡工具,基于Netflix Ribbon实现,Ribbon主要用于提供负载均衡算法和服务调用。Ribbon的客户端组件提供了一套完善的配置项,如超时和重试等。
+在通过Spring Cloud构建微服务时,Ribbon有两种使用方法,一种是和RedisTemplate结合使用,另一种是和OpenFegin相结合。
+## OpenFeign
+OpenFeign是一个远程调用组件,使用接口和注解以http的形式完成调用。
+Feign中集成了Ribbon,而Ribbon中则集成了eureka。
diff --git a/spring/caffeine/caffeine.md b/spring/caffeine/caffeine.md
index aa2da22..1abcc07 100644
--- a/spring/caffeine/caffeine.md
+++ b/spring/caffeine/caffeine.md
@@ -1,234 +1,234 @@
-- [caffeine](#caffeine)
- - [Cache](#cache)
- - [注入](#注入)
- - [手动](#手动)
- - [Loading](#loading)
- - [异步(手动)](#异步手动)
- - [Async Loading](#async-loading)
- - [淘汰](#淘汰)
- - [基于时间的](#基于时间的)
- - [基于时间的淘汰策略](#基于时间的淘汰策略)
- - [基于引用的淘汰策略](#基于引用的淘汰策略)
- - [移除](#移除)
- - [removal listener](#removal-listener)
- - [compute](#compute)
- - [统计](#统计)
- - [cleanup](#cleanup)
- - [软引用和弱引用](#软引用和弱引用)
- - [weakKeys](#weakkeys)
- - [weakValues](#weakvalues)
- - [softValues](#softvalues)
-
-
-# caffeine
-caffeine是一个高性能的java缓存库,其几乎能够提供最佳的命中率。
-cache类似于ConcurrentMap,但并不完全相同。在ConcurrentMap中,会维护所有添加到其中的元素,直到元素被显式移除;而Cache则是可以通过配置来自动的淘汰元素,从而限制cache的内存占用。
-## Cache
-### 注入
-Cache提供了如下的注入策略
-#### 手动
-```java
-Cache cache = Caffeine.newBuilder()
- .expireAfterWrite(10, TimeUnit.MINUTES)
- .maximumSize(10_000)
- .build();
-
-// Lookup an entry, or null if not found
-Graph graph = cache.getIfPresent(key);
-// Lookup and compute an entry if absent, or null if not computable
-graph = cache.get(key, k -> createExpensiveGraph(key));
-// Insert or update an entry
-cache.put(key, graph);
-// Remove an entry
-cache.invalidate(key);
-```
-Cache接口可以显示的操作缓存条目的获取、失效、更新。
-条目可以直接通过cache.put(key,value)来插入到缓存中,该操作会覆盖已存在的key对应的条目。
-也可以使用cache.get(key,k->value)的形式来对缓存进行插入,该方法会在缓存中查找key对应的条目,如果不存在,会调用k->value来进行计算并将计算后的将计算后的结果插入到缓存中。该操作是原子的。如果该条目不可计算,会返回null,如果计算过程中发生异常,则是会抛出异常。
-除上述方法外,也可以通过cache.asMap()返回map对象,并且调用ConcurrentMap中的接口来对缓存条目进行修改。
-#### Loading
-```java
-// build方法可以指定一个CacheLoader参数
-LoadingCache cache = Caffeine.newBuilder()
- .maximumSize(10_000)
- .expireAfterWrite(10, TimeUnit.MINUTES)
- .build(key -> createExpensiveGraph(key));
-
-// Lookup and compute an entry if absent, or null if not computable
-Graph graph = cache.get(key);
-// Lookup and compute entries that are absent
-Map graphs = cache.getAll(keys);
-```
-LoadingCache和CacheLoader相关联。
-可以通过getAll方法来执行批量查找,默认情况下,getAll方法会为每个cache中不存在的key向CacheLoader.load发送一个请求。当批量查找比许多单独的查找效率更加高时,可以重写CacheLoader.loadAll方法。
-#### 异步(手动)
-```java
-AsyncCache cache = Caffeine.newBuilder()
- .expireAfterWrite(10, TimeUnit.MINUTES)
- .maximumSize(10_000)
- .buildAsync();
-
-// Lookup an entry, or null if not found
-CompletableFuture graph = cache.getIfPresent(key);
-// Lookup and asynchronously compute an entry if absent
-graph = cache.get(key, k -> createExpensiveGraph(key));
-// Insert or update an entry
-cache.put(key, graph);
-// Remove an entry
-cache.synchronous().invalidate(key);
-```
-AsyncCache允许异步的计算条目,并且返回CompletableFuture。
-AsyncCache可以调用synchronous方法来提供同步的视图。
-默认情况下executor是ForkJoinPool.commonPool(),可以通过Caffeine.executor(threadPool)来进行覆盖。
-#### Async Loading
-```java
-AsyncLoadingCache cache = Caffeine.newBuilder()
- .maximumSize(10_000)
- .expireAfterWrite(10, TimeUnit.MINUTES)
- // Either: Build with a synchronous computation that is wrapped as asynchronous
- .buildAsync(key -> createExpensiveGraph(key));
- // Or: Build with a asynchronous computation that returns a future
- .buildAsync((key, executor) -> createExpensiveGraphAsync(key, executor));
-
-// Lookup and asynchronously compute an entry if absent
-CompletableFuture graph = cache.get(key);
-// Lookup and asynchronously compute entries that are absent
-CompletableFuture> graphs = cache.getAll(keys);
-```
-AsyncLoadingCache是一个AsyncCache加上一个AsyncCacheLoader。
-同样地,AsyncCacheLoader支持重写load和loadAll方法。
-### 淘汰
-Caffeine提供了三种类型的淘汰:基于size的,基于时间的,基于引用的。
-#### 基于时间的
-```java
-// Evict based on the number of entries in the cache
-LoadingCache graphs = Caffeine.newBuilder()
- .maximumSize(10_000)
- .build(key -> createExpensiveGraph(key));
-
-// Evict based on the number of vertices in the cache
-LoadingCache graphs = Caffeine.newBuilder()
- .maximumWeight(10_000)
- .weigher((Key key, Graph graph) -> graph.vertices().size())
- .build(key -> createExpensiveGraph(key));
-```
-如果你的缓存不应该超过特定的容量限制,应该使用`Caffeine.maximumSize(long)`方法。该缓存会对不常用的条目进行淘汰。
-如果每条记录的权重不同,那么可以通过`Caffeine.weigher(Weigher)`指定一个权重计算方法,并且通过`Caffeine.maximumWeight(long)`指定缓存最大的权重值。
-#### 基于时间的淘汰策略
-```java
-// Evict based on a fixed expiration policy
-LoadingCache graphs = Caffeine.newBuilder()
- .expireAfterAccess(5, TimeUnit.MINUTES)
- .build(key -> createExpensiveGraph(key));
-LoadingCache graphs = Caffeine.newBuilder()
- .expireAfterWrite(10, TimeUnit.MINUTES)
- .build(key -> createExpensiveGraph(key));
-
-// Evict based on a varying expiration policy
-LoadingCache graphs = Caffeine.newBuilder()
- .expireAfter(new Expiry() {
- public long expireAfterCreate(Key key, Graph graph, long currentTime) {
- // Use wall clock time, rather than nanotime, if from an external resource
- long seconds = graph.creationDate().plusHours(5)
- .minus(System.currentTimeMillis(), MILLIS)
- .toEpochSecond();
- return TimeUnit.SECONDS.toNanos(seconds);
- }
- public long expireAfterUpdate(Key key, Graph graph,
- long currentTime, long currentDuration) {
- return currentDuration;
- }
- public long expireAfterRead(Key key, Graph graph,
- long currentTime, long currentDuration) {
- return currentDuration;
- }
- })
- .build(key -> createExpensiveGraph(key));
-```
-caffine提供三种方法来进行基于时间的淘汰:
-- expireAfterAccess(long, TimeUnit):基于上次读写操作过后的时间来进行淘汰
-- expireAfterWrite(long, TimeUnit):基于创建时间、或上次写操作执行的时间来进行淘汰
-- expireAfter(Expire):基于自定义的策略来进行淘汰
-过期在写操作之间周期性的进行触发,偶尔也会在读操作之间进行出发。调度和发送过期事件都是在o(1)时间之内完成的。
-为了及时过期,而不是通过缓存活动来触发过期,可以通过`Caffeine.scheuler(scheduler)`来指定调度线程
-#### 基于引用的淘汰策略
-```java
-// Evict when neither the key nor value are strongly reachable
-LoadingCache graphs = Caffeine.newBuilder()
- .weakKeys()
- .weakValues()
- .build(key -> createExpensiveGraph(key));
-
-// Evict when the garbage collector needs to free memory
-LoadingCache graphs = Caffeine.newBuilder()
- .softValues()
- .build(key -> createExpensiveGraph(key));
-```
-caffeine允许设置cache支持垃圾回收,通过使用为key指定weak reference,为value制定soft reference
-
-### 移除
-可以通过下述方法显式移除条目:
-```java
-// individual key
-cache.invalidate(key)
-// bulk keys
-cache.invalidateAll(keys)
-// all keys
-cache.invalidateAll()
-```
-#### removal listener
-```java
-Cache graphs = Caffeine.newBuilder()
- .evictionListener((Key key, Graph graph, RemovalCause cause) ->
- System.out.printf("Key %s was evicted (%s)%n", key, cause))
- .removalListener((Key key, Graph graph, RemovalCause cause) ->
- System.out.printf("Key %s was removed (%s)%n", key, cause))
- .build();
-```
-在entry被移除时,可以指定listener来执行一系列操作,通过`Caffeine.removalListener(RemovalListener)`。操作是通过Executor异步执行的。
-当想要在缓存失效之后同步执行操作时,可以使用`Caffeine.evictionListener(RemovalListener)`.该监听器将会在`RemovalCause.wasEvicted()`时被触发
-### compute
-通过compute,caffeine可以在entry创建、淘汰、更新时,原子的执行一系列操作:
-```java
-Cache graphs = Caffeine.newBuilder()
- .evictionListener((Key key, Graph graph, RemovalCause cause) -> {
- // atomically intercept the entry's eviction
- }).build();
-
-graphs.asMap().compute(key, (k, v) -> {
- Graph graph = createExpensiveGraph(key);
- ... // update a secondary store
- return graph;
-});
-```
-### 统计
-通过`Caffeine.recordStats()`方法,可以启用统计信息的收集,`cache.stats()`方法将返回一个CacheStats对象,提供如下接口:
-- hitRate():返回请求命中率
-- evictionCount():cache淘汰次数
-- averageLoadPenalty():load新值花费的平均时间
-```java
-Cache graphs = Caffeine.newBuilder()
- .maximumSize(10_000)
- .recordStats()
- .build();
-```
-### cleanup
-默认情况下,Caffine并不会在自动淘汰entry后或entry失效之后立即进行清理,而是在写操作之后执行少量的清理工作,如果写操作很少,则是偶尔在读操作后执行少量读操作。
-如果你的缓存是高吞吐量的,那么不必担心过期缓存的清理,如果你的缓存读写操作都比较少,那么需要新建一个外部线程来调用`Cache.cleanUp()`来进行缓存清理。
-```java
-LoadingCache graphs = Caffeine.newBuilder()
- .scheduler(Scheduler.systemScheduler())
- .expireAfterWrite(10, TimeUnit.MINUTES)
- .build(key -> createExpensiveGraph(key));
-```
-scheduler可以用于及时的清理过期缓存
-
-### 软引用和弱引用
-caffeine支持基于引用来设置淘汰策略。caffeine支持针对key和value使用弱引用,针对value使用软引用。
-#### weakKeys
-`caffeine.weakKeys()`存储使用弱引用的key,如果没有强引用指向key,那么key将会被垃圾回收。垃圾回收时只会比较对象地址,故而整个缓存在比较key时会通过`==`而不是`equals`来进行比较
-#### weakValues
-`caffeine.weakValues()`存储使用弱引用的value,如果没有强引用指向value,value会被垃圾回收。同样地,在整个cache中,会使用`==`而不是`equals`来对value进行比较
-#### softValues
-软引用的value通常会在垃圾回收时按照lru的方式进行回收,根据内存情况决定是否进行回收。由于使用软引用会带来性能问题,通常更推荐使用基于max-size的回收策略。
-同样地,基于软引用的value在整个缓存中会通过`==`而不是`equals()`来进行垃圾回收。
+- [caffeine](#caffeine)
+ - [Cache](#cache)
+ - [注入](#注入)
+ - [手动](#手动)
+ - [Loading](#loading)
+ - [异步(手动)](#异步手动)
+ - [Async Loading](#async-loading)
+ - [淘汰](#淘汰)
+ - [基于时间的](#基于时间的)
+ - [基于时间的淘汰策略](#基于时间的淘汰策略)
+ - [基于引用的淘汰策略](#基于引用的淘汰策略)
+ - [移除](#移除)
+ - [removal listener](#removal-listener)
+ - [compute](#compute)
+ - [统计](#统计)
+ - [cleanup](#cleanup)
+ - [软引用和弱引用](#软引用和弱引用)
+ - [weakKeys](#weakkeys)
+ - [weakValues](#weakvalues)
+ - [softValues](#softvalues)
+
+
+# caffeine
+caffeine是一个高性能的java缓存库,其几乎能够提供最佳的命中率。
+cache类似于ConcurrentMap,但并不完全相同。在ConcurrentMap中,会维护所有添加到其中的元素,直到元素被显式移除;而Cache则是可以通过配置来自动的淘汰元素,从而限制cache的内存占用。
+## Cache
+### 注入
+Cache提供了如下的注入策略
+#### 手动
+```java
+Cache cache = Caffeine.newBuilder()
+ .expireAfterWrite(10, TimeUnit.MINUTES)
+ .maximumSize(10_000)
+ .build();
+
+// Lookup an entry, or null if not found
+Graph graph = cache.getIfPresent(key);
+// Lookup and compute an entry if absent, or null if not computable
+graph = cache.get(key, k -> createExpensiveGraph(key));
+// Insert or update an entry
+cache.put(key, graph);
+// Remove an entry
+cache.invalidate(key);
+```
+Cache接口可以显示的操作缓存条目的获取、失效、更新。
+条目可以直接通过cache.put(key,value)来插入到缓存中,该操作会覆盖已存在的key对应的条目。
+也可以使用cache.get(key,k->value)的形式来对缓存进行插入,该方法会在缓存中查找key对应的条目,如果不存在,会调用k->value来进行计算并将计算后的将计算后的结果插入到缓存中。该操作是原子的。如果该条目不可计算,会返回null,如果计算过程中发生异常,则是会抛出异常。
+除上述方法外,也可以通过cache.asMap()返回map对象,并且调用ConcurrentMap中的接口来对缓存条目进行修改。
+#### Loading
+```java
+// build方法可以指定一个CacheLoader参数
+LoadingCache cache = Caffeine.newBuilder()
+ .maximumSize(10_000)
+ .expireAfterWrite(10, TimeUnit.MINUTES)
+ .build(key -> createExpensiveGraph(key));
+
+// Lookup and compute an entry if absent, or null if not computable
+Graph graph = cache.get(key);
+// Lookup and compute entries that are absent
+Map graphs = cache.getAll(keys);
+```
+LoadingCache和CacheLoader相关联。
+可以通过getAll方法来执行批量查找,默认情况下,getAll方法会为每个cache中不存在的key向CacheLoader.load发送一个请求。当批量查找比许多单独的查找效率更加高时,可以重写CacheLoader.loadAll方法。
+#### 异步(手动)
+```java
+AsyncCache cache = Caffeine.newBuilder()
+ .expireAfterWrite(10, TimeUnit.MINUTES)
+ .maximumSize(10_000)
+ .buildAsync();
+
+// Lookup an entry, or null if not found
+CompletableFuture graph = cache.getIfPresent(key);
+// Lookup and asynchronously compute an entry if absent
+graph = cache.get(key, k -> createExpensiveGraph(key));
+// Insert or update an entry
+cache.put(key, graph);
+// Remove an entry
+cache.synchronous().invalidate(key);
+```
+AsyncCache允许异步的计算条目,并且返回CompletableFuture。
+AsyncCache可以调用synchronous方法来提供同步的视图。
+默认情况下executor是ForkJoinPool.commonPool(),可以通过Caffeine.executor(threadPool)来进行覆盖。
+#### Async Loading
+```java
+AsyncLoadingCache cache = Caffeine.newBuilder()
+ .maximumSize(10_000)
+ .expireAfterWrite(10, TimeUnit.MINUTES)
+ // Either: Build with a synchronous computation that is wrapped as asynchronous
+ .buildAsync(key -> createExpensiveGraph(key));
+ // Or: Build with a asynchronous computation that returns a future
+ .buildAsync((key, executor) -> createExpensiveGraphAsync(key, executor));
+
+// Lookup and asynchronously compute an entry if absent
+CompletableFuture graph = cache.get(key);
+// Lookup and asynchronously compute entries that are absent
+CompletableFuture> graphs = cache.getAll(keys);
+```
+AsyncLoadingCache是一个AsyncCache加上一个AsyncCacheLoader。
+同样地,AsyncCacheLoader支持重写load和loadAll方法。
+### 淘汰
+Caffeine提供了三种类型的淘汰:基于size的,基于时间的,基于引用的。
+#### 基于时间的
+```java
+// Evict based on the number of entries in the cache
+LoadingCache graphs = Caffeine.newBuilder()
+ .maximumSize(10_000)
+ .build(key -> createExpensiveGraph(key));
+
+// Evict based on the number of vertices in the cache
+LoadingCache graphs = Caffeine.newBuilder()
+ .maximumWeight(10_000)
+ .weigher((Key key, Graph graph) -> graph.vertices().size())
+ .build(key -> createExpensiveGraph(key));
+```
+如果你的缓存不应该超过特定的容量限制,应该使用`Caffeine.maximumSize(long)`方法。该缓存会对不常用的条目进行淘汰。
+如果每条记录的权重不同,那么可以通过`Caffeine.weigher(Weigher)`指定一个权重计算方法,并且通过`Caffeine.maximumWeight(long)`指定缓存最大的权重值。
+#### 基于时间的淘汰策略
+```java
+// Evict based on a fixed expiration policy
+LoadingCache graphs = Caffeine.newBuilder()
+ .expireAfterAccess(5, TimeUnit.MINUTES)
+ .build(key -> createExpensiveGraph(key));
+LoadingCache graphs = Caffeine.newBuilder()
+ .expireAfterWrite(10, TimeUnit.MINUTES)
+ .build(key -> createExpensiveGraph(key));
+
+// Evict based on a varying expiration policy
+LoadingCache graphs = Caffeine.newBuilder()
+ .expireAfter(new Expiry() {
+ public long expireAfterCreate(Key key, Graph graph, long currentTime) {
+ // Use wall clock time, rather than nanotime, if from an external resource
+ long seconds = graph.creationDate().plusHours(5)
+ .minus(System.currentTimeMillis(), MILLIS)
+ .toEpochSecond();
+ return TimeUnit.SECONDS.toNanos(seconds);
+ }
+ public long expireAfterUpdate(Key key, Graph graph,
+ long currentTime, long currentDuration) {
+ return currentDuration;
+ }
+ public long expireAfterRead(Key key, Graph graph,
+ long currentTime, long currentDuration) {
+ return currentDuration;
+ }
+ })
+ .build(key -> createExpensiveGraph(key));
+```
+caffine提供三种方法来进行基于时间的淘汰:
+- expireAfterAccess(long, TimeUnit):基于上次读写操作过后的时间来进行淘汰
+- expireAfterWrite(long, TimeUnit):基于创建时间、或上次写操作执行的时间来进行淘汰
+- expireAfter(Expire):基于自定义的策略来进行淘汰
+过期在写操作之间周期性的进行触发,偶尔也会在读操作之间进行出发。调度和发送过期事件都是在o(1)时间之内完成的。
+为了及时过期,而不是通过缓存活动来触发过期,可以通过`Caffeine.scheuler(scheduler)`来指定调度线程
+#### 基于引用的淘汰策略
+```java
+// Evict when neither the key nor value are strongly reachable
+LoadingCache graphs = Caffeine.newBuilder()
+ .weakKeys()
+ .weakValues()
+ .build(key -> createExpensiveGraph(key));
+
+// Evict when the garbage collector needs to free memory
+LoadingCache graphs = Caffeine.newBuilder()
+ .softValues()
+ .build(key -> createExpensiveGraph(key));
+```
+caffeine允许设置cache支持垃圾回收,通过使用为key指定weak reference,为value制定soft reference
+
+### 移除
+可以通过下述方法显式移除条目:
+```java
+// individual key
+cache.invalidate(key)
+// bulk keys
+cache.invalidateAll(keys)
+// all keys
+cache.invalidateAll()
+```
+#### removal listener
+```java
+Cache graphs = Caffeine.newBuilder()
+ .evictionListener((Key key, Graph graph, RemovalCause cause) ->
+ System.out.printf("Key %s was evicted (%s)%n", key, cause))
+ .removalListener((Key key, Graph graph, RemovalCause cause) ->
+ System.out.printf("Key %s was removed (%s)%n", key, cause))
+ .build();
+```
+在entry被移除时,可以指定listener来执行一系列操作,通过`Caffeine.removalListener(RemovalListener)`。操作是通过Executor异步执行的。
+当想要在缓存失效之后同步执行操作时,可以使用`Caffeine.evictionListener(RemovalListener)`.该监听器将会在`RemovalCause.wasEvicted()`时被触发
+### compute
+通过compute,caffeine可以在entry创建、淘汰、更新时,原子的执行一系列操作:
+```java
+Cache graphs = Caffeine.newBuilder()
+ .evictionListener((Key key, Graph graph, RemovalCause cause) -> {
+ // atomically intercept the entry's eviction
+ }).build();
+
+graphs.asMap().compute(key, (k, v) -> {
+ Graph graph = createExpensiveGraph(key);
+ ... // update a secondary store
+ return graph;
+});
+```
+### 统计
+通过`Caffeine.recordStats()`方法,可以启用统计信息的收集,`cache.stats()`方法将返回一个CacheStats对象,提供如下接口:
+- hitRate():返回请求命中率
+- evictionCount():cache淘汰次数
+- averageLoadPenalty():load新值花费的平均时间
+```java
+Cache graphs = Caffeine.newBuilder()
+ .maximumSize(10_000)
+ .recordStats()
+ .build();
+```
+### cleanup
+默认情况下,Caffine并不会在自动淘汰entry后或entry失效之后立即进行清理,而是在写操作之后执行少量的清理工作,如果写操作很少,则是偶尔在读操作后执行少量读操作。
+如果你的缓存是高吞吐量的,那么不必担心过期缓存的清理,如果你的缓存读写操作都比较少,那么需要新建一个外部线程来调用`Cache.cleanUp()`来进行缓存清理。
+```java
+LoadingCache graphs = Caffeine.newBuilder()
+ .scheduler(Scheduler.systemScheduler())
+ .expireAfterWrite(10, TimeUnit.MINUTES)
+ .build(key -> createExpensiveGraph(key));
+```
+scheduler可以用于及时的清理过期缓存
+
+### 软引用和弱引用
+caffeine支持基于引用来设置淘汰策略。caffeine支持针对key和value使用弱引用,针对value使用软引用。
+#### weakKeys
+`caffeine.weakKeys()`存储使用弱引用的key,如果没有强引用指向key,那么key将会被垃圾回收。垃圾回收时只会比较对象地址,故而整个缓存在比较key时会通过`==`而不是`equals`来进行比较
+#### weakValues
+`caffeine.weakValues()`存储使用弱引用的value,如果没有强引用指向value,value会被垃圾回收。同样地,在整个cache中,会使用`==`而不是`equals`来对value进行比较
+#### softValues
+软引用的value通常会在垃圾回收时按照lru的方式进行回收,根据内存情况决定是否进行回收。由于使用软引用会带来性能问题,通常更推荐使用基于max-size的回收策略。
+同样地,基于软引用的value在整个缓存中会通过`==`而不是`equals()`来进行垃圾回收。
diff --git a/中间件/redis/redis sentinel.md b/中间件/redis/redis sentinel.md
new file mode 100644
index 0000000..f3f0570
--- /dev/null
+++ b/中间件/redis/redis sentinel.md
@@ -0,0 +1,83 @@
+- [redis sentinel](#redis-sentinel)
+ - [sentinel as a distributed system](#sentinel-as-a-distributed-system)
+ - [sentinel部署要点](#sentinel部署要点)
+ - [sentinel配置](#sentinel配置)
+ - [sentinel monitor](#sentinel-monitor)
+ - [其他sentinel选项](#其他sentinel选项)
+ - [down-after-milliseconds](#down-after-milliseconds)
+ - [parallel-syncs](#parallel-syncs)
+
+
+# redis sentinel
+## sentinel as a distributed system
+redis sentinel是一个分布式系统,其设计旨在多个sentinel进程协同工作。
+
+redis sentinel的优势如下:
+- 当多个sentinel节点都一致认为master不再可访问时,将会触发故障检测机制。该机制能够有效的降低false positive几率
+- 即使并非所有sentinel进程都正常工作,sentinel机制仍然能够正常工作,确保整个sentinel机制拥有容错性
+
+sentinels、redis实例、客户端共同构成了包含特定属性的更大分布式系统。
+
+sentinels默认会监听26379端口, sentinels实例之间会通过该端口进行通信。如果该端口未开放,那么sentinels之间将无法通信,也无法协商一致,failover将不会被执行。
+
+### sentinel部署要点
+- 对于一个具备鲁棒性的形同部署而言,至少需要三个sentinels进程实例
+- 三个sentinel实例应当被部署在独立故障的计算机/虚拟机中
+- sentinel + redis 分布式系统并不保证在发生故障时,对系统的`acked writes`不被丢失。
+ - 因为redis的replication是异步的,故而在发生故障时可能会丢失部分写入
+- clients需要sentinel支持,大部分client library中包含sentinel支持
+
+### sentinel配置
+redis包含一个名为`sentinel.conf`的文件,用于配置sentinel,典型的最小化配置如下:
+```redis
+sentinel monitor mymaster 127.0.0.1 6379 2
+sentinel down-after-milliseconds mymaster 60000
+sentinel failover-timeout mymaster 180000
+sentinel parallel-syncs mymaster 1
+
+sentinel monitor resque 192.168.1.3 6380 4
+sentinel down-after-milliseconds resque 10000
+sentinel failover-timeout resque 180000
+sentinel parallel-syncs resque 5
+```
+
+只需要指定监控的主节点,并为每个主节点指定不同的名称。无需手动指定replicas,系统会自动发现replicas。sentinel将会自动使用replicas的额外信息来更新配置。
+
+并且,发生故障转移replica被提升为主节点时/新sentinel被发现时,该配置文件也会被重写。
+
+在上述配置文件示例中,监控了两个redis实例集合,每个redis实例集合都由一个master和一系列replicas组成。上述,一个集合被称为`mymaster`,另一个集合被称为`resque`。
+
+### sentinel monitor
+```
+sentinel monitor
+```
+上述是`sentinel monitor`的语法,其用于告知redis监控名为`mymaster`的master实例,并且其地址为`127.0.0.1`,端口号为`6379`,quorum为2。
+
+其中,quorum的含义如下:
+- quorm为需要达成`master不可访问`这一共识的sentinels数量,其将将master标记为失败,并且在条件允许的情况下启动failover
+- quorum仅用于检测失败。为了实际的执行故障转移,sentinels中的一个需要被选举为leader,这需要获取多数sentinel进程的投票后才能完成
+
+例如,假设有5个sentinel进程,并且给定master的quorum为2,那么:
+- 如果两个sentinels达成共识master不可访问,那么其中一个sentinel将会尝试开启故障转移
+- 只有当至少存在3个sentinels可访问时,故障转移才会被授权,并实际启动故障转移
+
+在实际应用中,少数派分区将永远不会在故障时触发故障转移。
+
+### 其他sentinel选项
+其他sentinel选项的格式集合都如下:
+```
+sentinel
+```
+
+#### down-after-milliseconds
+`down-after-milliseconds`选项代表sentinel认为实例宕机的时间,在该段时间内实例应当是不可访问的
+
+#### parallel-syncs
+`parallel-syncs`代表故障转移时,replicas同时被重新配置的数量。replicas在故障转移时,会被重新配置并使用新的master节点。
+
+- 当`parallel-syncs`参数指定的值被降低时,故障转移过程耗费的时间将会增加
+- replication过程通常是非阻塞的,但是其间有一个时间段会中止并从master批量加载数据。此时,可能并不希望所有的replicas都不可用并从新master同步数据
+
+配置参数可以在运行时被修改,
+- 针对master的配置参数可以通过`SENTINEL SET`命令修改
+- 全局配置参数可以通过`SENTINEL CONFIG SET`命令来进行修改
 -如上图所示,innodb中的数据是按照索引来进行组织的。但是,通过B+树索引,其无法直接查询到指定的记录,其只能查询到记录所位于的页。
-
-例如,在上图示例中,其在查询`ID=32`的时,只能查询到该记录位于page 17中。
-
-> 在B+树的叶子节点,每个页的File Header中都存有指向前一个页和后一个页的指针,`故而每个页之间是通过双向列表结构来维护的`;但是对于页中的记录,`记录与记录之间维维护的时单向列表的关系`。
->
-> 对于Compact或Dynamic行格式的页,其每条记录的record header中都包含一个next_record字段指向下一条记录。故而,位于同一个页中的记录可以单向访问。
-
-但是,在一个页内查找某条记录时,沿着单向链表进行查找其效率很低。故而,page中的数据时机被分为了多个组,被分为的组构成了一个subdirectory,故而,通过子目录能够缩小查询范围,提高查询性能。
-
-page directory是一个能够存储多个slots的部分,每个slot中存储了group中最后一条记录的相对位置。假设slot中最大一条记录为`r`,那么group中记录的条数被存储在`r`记录record header的`n_owned`字段中。
-
-group中record的数量约束如下:
-- infimum group中records数量限制为`[1,8]`
-- supremum group中records数量限制为`[1,8]`
-- 其他group中records限制为`[4,8]`
-
-page directory生成过程如下所示:
-- 最开始时,页中只有infimum和supremum两条记录,它们分别属于两个group。page directory中有两个slots指向这两条记录,两个slot的n_owned都为1
-- 后续,当新的记录被插入页时,系统会查找page directory中主键值大于待插入记录的第一个slot。slot对应最大记录的`n_owned`字段会增加1,代表group中新插入了记录,直到group中的记录数量到达8
-- 当新纪录被插入到的group中记录数大于8时,group中的记录被分为2个group,一个group包含4条记录,另一个group包含5条记录。该过程将会向page directory中新增一个新的slot
-- 当记录被删除时,slot最最大一条记录的`n_owned`将会减少1,当n_owned字段小于4时,会触发再平衡操作,平衡后的page directory满足上述要求
-
-page directory中的slots数量如page header中的`PAGE_N_DIR_SLOTS`所示。
-
-一旦innodb中页包含page directory后,其会通过二分查找快速的定位slot,并且从group中最小记录开始,通过`next_record`指针来遍历页中的记录列表。这样能够快速的定位记录位置。
-
-### File Trailer
-
-#### 完整性校验
-在innodb中,页的大小为16KB,可能和磁盘的扇区大小不同。通常磁盘的扇区大小为512字节,故而在写入一个页到磁盘中时,需要分32个扇区进行写入。
-
-在写入一个页时,可能会发生宕机场景,这时,一个页只写入了一部分,可能会发生脏写。此时,可以通过double write buffer机制对脏写的页进行恢复。
-
-在一个页被写入到磁盘中时,首先会被写入的是File Header的`FIL_PAGE_SPACE_OR_CHKSUM`,该部分是page的checksum。
-
-innodb设置了File Trailer部分来校验page是否被完全写入到磁盘中,File Trailer中只包含一个`FIL_PAGE_END_LSN`部分,占用8字节,前4字节代表该页的checksum值,后4字节和File Header中的`FIL_PAGE_LSN`相同,`代表最后一次修改该页关联的LSN位置`。将上述两个字段和File Header中的`FIL_PAGE_SPACE_OR_CHKSUM`和`FIL_PAGE_LSN`值进行比较,查看是否一致,从而保证页的完整性。
-
-默认情况下,在innodb每次从磁盘读取page时,都会检查页面的完整性。
-
-## 分区表
-innodb存储引擎支持分区功能,分区过程将一个表或索引分为多个更小、更可管理的部分。
-
-对于访问数据库的应用而言,逻辑上的一个表或索引,其物理上可能由多个物理分区组成,每个分区都是独立的对象,既可以独自进行处理,又可以作为一个更大对象的一部分进行处理。
-
-> mysql仅支持水平分区(将同一张表中的不同行记录分配到不同的物理文件中),并不支持垂直分区(将同一张表中的不同列分配到不同的物理文件中)。
-
-目前mysql支持如下几种类型的分区:
-- `RANGE`: 行数据基于一个给定连续区间的列值被放入分区
-- `LIST`: 和`RANGE`类似,但`LIST`分区面对的是更加离散的值
-- `HASH`: 根据用户自定义的表达式返回值来进行分区,返回值不能为负数
-- `KEY`:根据mysql提供的哈希函数来进行分区
-
-`不论创建何种类型的分区,如果表中存在唯一索引或主键,分区列必须是唯一索引的一个组成部分。`
-
-### partition keys & primary keys & unique keys
-对于分区表而言,`所有在partition expression中使用到的col,其必须被包含在分区表所有的唯一索引中`。
-
-> `所有唯一索引`中包含主键索引。
-
-正确建立分区表的声明示例如下:
-```sql
-CREATE TABLE t1 (
- col1 INT NOT NULL,
- col2 DATE NOT NULL,
- col3 INT NOT NULL,
- col4 INT NOT NULL,
- UNIQUE KEY (col1, col2, col3)
-)
-PARTITION BY HASH(col3)
-PARTITIONS 4;
-
-CREATE TABLE t2 (
- col1 INT NOT NULL,
- col2 DATE NOT NULL,
- col3 INT NOT NULL,
- col4 INT NOT NULL,
- UNIQUE KEY (col1, col3)
-)
-PARTITION BY HASH(col1 + col3)
-PARTITIONS 4;
-
-
-CREATE TABLE t7 (
- col1 INT NOT NULL,
- col2 DATE NOT NULL,
- col3 INT NOT NULL,
- col4 INT NOT NULL,
- PRIMARY KEY(col1, col2)
-)
-PARTITION BY HASH(col1 + YEAR(col2))
-PARTITIONS 4;
-
-CREATE TABLE t8 (
- col1 INT NOT NULL,
- col2 DATE NOT NULL,
- col3 INT NOT NULL,
- col4 INT NOT NULL,
- PRIMARY KEY(col1, col2, col4),
- UNIQUE KEY(col2, col1)
-)
-PARTITION BY HASH(col1 + YEAR(col2))
-PARTITIONS 4;
-
-
-create table t2_partition (
- col1 int ,
- col2 date,
- col3 int null,
- col4 int null,
- unique index `idx_t2_partition_cols` (col1, col2,col3),
- primary key (col2, col1)
-)
-partition by hash(col1)
-partitions 4;
-```
-#### 表中不存在唯一索引
-如果表中没有唯一索引(也未定义primary key),那么上述要求并不会生效,可以在partition expression中使用任意cols。
-
-#### 后续向分区表添加唯一索引
-如果想要向分区表中添加唯一索引,那么新增的唯一索引中必须包含partition expression中所有的列。
-
-#### 对非分区表进行分区
-可以参照如下示例对非分区表进行分区:
-```sql
-CREATE TABLE np_pk (
- id INT NOT NULL AUTO_INCREMENT,
- name VARCHAR(50),
- added DATE,
- PRIMARY KEY (id)
-);
-```
-可以按`id`进行分区
-```sql
-ALTER TABLE np_pk
- PARTITION BY HASH(id)
- PARTITIONS 4;
-```
-### 分区类型
-#### RANGE
-RANGE为较常见的分区类型,如下示例为创建RANGE类型分区表的示例:
-```sql
-create table t1 (
- id bigint auto_increment not null,
- tran_date datetime(6) not null default now(6) on update now(6),
- primary key (id, tran_date)
-) engine=innodb
-partition by range (year(tran_date)) (
- partition part_y_let_2024 values less than (2025),
- partition part_y_eq_2025 values less than (2026)
- );
-```
-上述创建了表`t1`,t1主键为`(id, tran_date)`,且按照`tran_date`字段的年部分进行分区,分区类型为RANGE。
-
-表t1的分区为两部分,分区1为`tran_date位于2024或之前年份`的分区`part_y_let_2024`,分区2是`tran_date位于2025年`的分区`part_y_eq_2025`。
-
-##### information_schema.partitions
-如果要查看表的分区情况,可以查询`information_schema.partitions`表,示例如下
-```sql
-select * from information_schema.partitions where table_schema = 'learn_innodb' and table_name = 't1';
-```
-查询结果如下所示:
-| TABLE\_CATALOG | TABLE\_SCHEMA | TABLE\_NAME | PARTITION\_NAME | SUBPARTITION\_NAME | PARTITION\_ORDINAL\_POSITION | SUBPARTITION\_ORDINAL\_POSITION | PARTITION\_METHOD | SUBPARTITION\_METHOD | PARTITION\_EXPRESSION | SUBPARTITION\_EXPRESSION | PARTITION\_DESCRIPTION | TABLE\_ROWS | AVG\_ROW\_LENGTH | DATA\_LENGTH | MAX\_DATA\_LENGTH | INDEX\_LENGTH | DATA\_FREE | CREATE\_TIME | UPDATE\_TIME | CHECK\_TIME | CHECKSUM | PARTITION\_COMMENT | NODEGROUP | TABLESPACE\_NAME |
-| :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- |
-| def | learn\_innodb | t1 | part\_y\_eq\_2025 | null | 2 | null | RANGE | null | year\(\`tran\_date\`\) | null | 2026 | 0 | 0 | 16384 | 0 | 0 | 0 | 2025-02-08 01:05:53 | null | null | null | | default | null |
-| def | learn\_innodb | t1 | part\_y\_let\_2024 | null | 1 | null | RANGE | null | year\(\`tran\_date\`\) | null | 2025 | 0 | 0 | 16384 | 0 | 0 | 0 | 2025-02-08 01:05:53 | null | null | null | | default | null |
-
-为分区表预置如下数据
-```sql
-insert into t1(tran_date) values ('2023-01-01'), ('2024-12-31'), ('2025-01-01');
-```
-可以看到分区表中数据分布如下:
-```sql
-select partition_name, table_rows from information_schema.partitions where table_schema = 'learn_innodb' and table_name = 't1';
-```
-| PARTITION\_NAME | TABLE\_ROWS |
-| :--- | :--- |
-| part\_y\_eq\_2025 | 1 |
-| part\_y\_let\_2024 | 2 |
-
-易知`('2023-01-01'), ('2024-12-31')`数据位于`part_y_let_2024`分区,故而该分区存在两条数据;而`('2025-01-01')`数据位于`part_y_let_2024`分区,该分区存在一条数据。
-
-##### 看select语句查询了哪些分区
-数据分布可以通过如下方式验证:
-```sql
-explain select * from t1 where tran_date >= '2023-01-01' and tran_date <= '2024-12-31';
-```
-| id | select\_type | table | partitions | type | possible\_keys | key | key\_len | ref | rows | filtered | Extra |
-| :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- |
-| 1 | SIMPLE | t1 | part\_y\_let\_2024 | index | PRIMARY | PRIMARY | 16 | null | 2 | 50 | Using where; Using index |
-
-```sql
-explain select * from t1 where tran_date >= '2025-01-01'
-```
-| id | select\_type | table | partitions | type | possible\_keys | key | key\_len | ref | rows | filtered | Extra |
-| :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- |
-| 1 | SIMPLE | t1 | part\_y\_eq\_2025 | index | PRIMARY | PRIMARY | 16 | null | 1 | 100 | Using where; Using index |
-
-##### 插入超过分区范围的数据
-如果尝试向分区表中插入超过所有分区范围的数据,会执行失败,示例如下:
-```sql
-insert into t1(tran_date) values ('2026-01-01');
-```
-由于分区表`t1`中现有分区最大只支持2025年的分区,故而当尝试插入2026年分区时,会抛出如下错误:
-```bash
-[2025-02-08 01:32:51] [HY000][1526] Table has no partition for value 2026
-```
-##### 向分区表中添加分区
-mysql支持向分区表中添加分区,语法如下
-```sql
-alter table t1 add partition (
- partition part_year_egt_2026 values less than maxvalue
- );
-```
-添加分区后,mysql支持`tran_date大于等于2026`的分区,执行如下语句
-```sql
-insert into t1(tran_date) values ('2026-01-01'), ('2027-12-31'), ('2028-01-01');
-```
-之后,再次分区分区中的数据分区,结果如下
-| PARTITION\_NAME | TABLE\_ROWS |
-| :--- | :--- |
-| part\_y\_eq\_2025 | 1 |
-| part\_y\_let\_2024 | 2 |
-| part\_year\_egt\_2026 | 3 |
-
-> `information.partitions`表中,`table_rows`字段可能存在不准确的情况,如果想要获取准确的值,需要执行`analyze table {schema}.{table_name}`语句
-
-##### 向分区表中删除分区
-当想要删除分区表中现存分区时,可以通过执行如下语句
-```sql
-alter table t1 drop partition part_year_egt_2026;
-```
-在删除分区后,分区中的数据也会被删除,执行查询语句后
-```sql
-select * from t1;
-
-```
-可知`part_year_egt_2026`被删除后分区中数据全部消失
-| id | tran\_date |
-| :--- | :--- |
-| 1 | 2023-01-01 00:00:00.000000 |
-| 2 | 2024-12-31 00:00:00.000000 |
-| 3 | 2025-01-01 00:00:00.000000 |
-
-#### LIST
-LIST分区类型和RANGE分区类型非常相似,但是LIST分区列的值是离散的,RANGE分区列的值是连续的。
-
-创建LIST类型分区表的示例如下:
-```sql
-create table p_list_t1 (
- id bigint not null auto_increment,
- area smallint not null,
- primary key (id, area)
-)
-partition by list (area) (
- partition p_ch_beijing values in (1),
- partition p_ch_hubei values in (2),
- partition p_ch_jilin values in (3)
- );
-```
-之后可向`p_list_t1`表中预置数据,执行语句如下:
-```sql
-insert into p_list_t1(area) values (1),(1), (2), (3), (3);
-```
-此时,数据分布如下:
-| PARTITION\_METHOD | PARTITION\_NAME | TABLE\_ROWS |
-| :--- | :--- | :--- |
-| LIST | p\_ch\_beijing | 2 |
-| LIST | p\_ch\_hubei | 1 |
-| LIST | p\_ch\_jilin | 2 |
-
-如果想要向分区表中插入不位于现存分区中的值,那么插入语句同样会执行失败,示例如下
-```sql
-insert into p_list_t1(area) values (4);
-```
-由于目前没有area为4的分区,故而插入语句执行失败,报错如下
-```bash
-[2025-02-09 20:30:03] [HY000][1526] Table has no partition for value 4
-```
-
-#### HASH
-HASH分区方式是将数据均匀分布到预先定义的各个分区中,期望各个分区中散列的数据数量大致相同。
-
-在通过hash来进行分区时,建表时需要指定一个分区表达式,该表达式返回整数。
-
-创建hash分区的示例如下:
-```sql
-create table p_hash_t1 (
- id bigint not null auto_increment,
- content varchar(256),
- primary key (id)
-)
-partition by hash (id)
-partitions 4;
-```
-上述ddl创建了一个按照`id`列进行hash分区的分区表,分区表包含4个分区。
-
-预置数据sql如下:
-```sql
-insert into p_hash_t1(content) values ('asahi'), ('maki'), ('katahara');
-```
-预置数据后数据分布如下
-| PARTITION\_METHOD | PARTITION\_NAME | TABLE\_ROWS |
-| :--- | :--- | :--- |
-| HASH | p0 | 0 |
-| HASH | p1 | 1 |
-| HASH | p2 | 1 |
-| HASH | p3 | 1 |
-
-预置的三条数据id分别为`1, 2, 3`,被hash放置到分区`p1, p2, p3`中。
-
-> 当使用hash分区方式时,例如存在`4`个分区,对于待插入数据其分区表达式的值为`2`,那么待插入数据将会被插入到`2%4 = 2`,第`3`个分区中(0,1,2分区,排第三),也就是`p2`。
->
-> 可以通过`explain select * from p_hash_t1 where id = 2;`语句来进行验证,得到如下结果。
->
-> | id | select\_type | table | partitions | type | possible\_keys | key | key\_len | ref | rows | filtered | Extra |
-> | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- |
-> | 1 | SIMPLE | p\_hash\_t1 | p2 | const | PRIMARY | PRIMARY | 8 | const | 1 | 100 | null |
-
-
-##### 新增HASH分区
-对于hash分区方式,可以通过如下方式来新增分区:
-```sql
-alter table p_hash_t1 add partition partitions 3;
-```
-其会新增3个分区,执行后分区数量为7。
-
-此时,原本分区中的数据会被重新散列到新分区中
-
-##### 减少HASH分区
-对于hash分区,在尝试减少分区数量的同时,通常不希望删除任何数据,故而无法使用`drop`。
-
-故而,可以使用`coalesce`,其只会减少分区数量,不会删除数据。
-
-示例如下:
-```sql
-alter table p_hash_t1 coalesce partition 4;
-```
-上述语句会将分区数量减少4个,故而减少后分区数量为`3`。
-
-
-#### LINEAR HASH
-创建linear hash分区表的方式和hash类似,可以通过如下方式
-```sql
-create table p_linear_hash_t1 (
- id bigint not null auto_increment,
- content varchar(256),
- primary key(id)
-)
-partition by linear hash (id)
-partitions 5;
-```
-相较于hash分区,在使用linear hash分区时,添加、删除、合并、拆分分区将会变得更加快捷,但是相比于hash分区,其数据分区可能会不太均匀。
-
-#### KEY & LINEAR KEY
-KEY分区方式和HASH分区方式类似,但是HASH分区采用用户自定义的函数进行分区,而KEY分区方式则是采用mysql提供的函数进行分区。
-
-创建key分区表的示例如下:
-```sql
-create table p_key_t1 (
- id bigint not null auto_increment,
- content varchar(256),
- primary key(id)
-)
-partition by key(id)
-partitions 5;
-```
-> key分区方式同样可以使用linear进行修饰,效果和hash分区方式类似。
-
-> 对于key分区,可以指定除了integer之外的col类型,而`range, list, hash`等分区类型只支持integer类型的col。
-
-
-#### COLUMNS
-COLUMNS分区方式为`RANGE`和`LIST`分区的变体。
-
-COLUMNS分区方式支持在分区时使用多个列,在插入新数据或查询数据决定分区时,所有的列都会被考虑。
-
-COLUMNS分区方式分为如下两种
-- RANGE COLUMNS
-- LIST COLUMNS
-
-上述两种方式都支持非整数类型的列,COLUMNS支持的数据类型如下:
-- 所有integers类型(DECIMAL, FLOAT则不受支持)
-- DATE和DATETIME类型
-- 字符串类型:CHAR, VARCHAR, BINARY, VARBINARY(TEXT, BLOB类型不受支持)
-
-##### range columns
-创建range columns分区表的示例如下:
-```sql
-create table p_range_columns_t1 (
- id bigint not null auto_increment,
- name varchar(256),
- born_ts datetime(6),
- primary key (id, born_ts)
-)
-partition by range columns (born_ts) (
- partition p0 values less than ('1900-01-01'),
- partition p1 values less than ('2000-01-01'),
- partition p2 values less than ('2999-01-01')
- );
-```
-
-##### list columns
-创建list columns分区表的示例则如下:
-```sql
-create table p_list_columns_t1 (
- id bigint not null auto_increment,
- province varchar(256),
- city varchar(256),
- primary key (id, province, city)
-)
-partition by list columns (province, city) (
- partition p_beijing values in (('china', 'beijing')),
- partition p_wuhan values in (('hubei', 'wuhan'))
- );
-```
-
-> 通过range columns和list columns,可以很好的替代range和list分区,而无需将列值都转换为整型。
-
-### 子分区
-`子分区`代表在分区的基础上再次进行分区,mysql允许`在range和list分区的基础`上再次进行`hash或key`的子分区,示例如下:
-```sql
-create table p_list_columns_t1 (
- id bigint not null auto_increment,
- province varchar(256),
- city varchar(256),
- primary key (id, province, city)
-)
-partition by list columns (province, city)
-subpartition by key(id)
-subpartitions 3
-(
- partition p_beijing values in (('china', 'beijing')),
- partition p_wuhan values in (('hubei', 'wuhan'))
-);
-```
-上述示例先按照`list columns`分区方式进行了分区,然后在为每个分区都按`key`分了三个子分区,查看分区和子分区详情可以通过如下语句:
-```sql
-select partition_name, partition_method, subpartition_name, subpartition_method from information_schema.partitions where table_name = 'p_list_columns_t1';
-```
-| PARTITION\_NAME | PARTITION\_METHOD | SUBPARTITION\_NAME | SUBPARTITION\_METHOD |
-| :--- | :--- | :--- | :--- |
-| p\_wuhan | LIST COLUMNS | p\_wuhansp0 | KEY |
-| p\_wuhan | LIST COLUMNS | p\_wuhansp1 | KEY |
-| p\_wuhan | LIST COLUMNS | p\_wuhansp2 | KEY |
-| p\_beijing | LIST COLUMNS | p\_beijingsp0 | KEY |
-| p\_beijing | LIST COLUMNS | p\_beijingsp1 | KEY |
-| p\_beijing | LIST COLUMNS | p\_beijingsp2 | KEY |
-
-### 分区中的NULL值
-mysql允许对null值做分区,但`mysql数据库中的分区总是视null值小于任何非null的值`,该逻辑`和order by处理null值的逻辑一致`。
-
-故而,在使用不同的分区类型时,对于null值的处理逻辑如下:
-- 对于range类型分区,当插入null值时,其会被放在最左侧的分区中
-- 对于list类型的分区,如果要插入null值,必须在分区的`values in (...)`表达式中指定null值,否则插入语句将会报错
-- hash和key的分区类型,将会将null值当作`0`来散列
-
-### 分区和性能
-对于OLTP类型的应用,使用分区表时应该相当小心,因为分区表可能会带来严重的性能问题。
-
-例如,对于包含1000w条数据的表`t`,如果包含主键索引`id`和非主键索引`code`,分区和不分区,其性能分析如下
-
-#### 不分区
-如果不对表t进行分区,那么根据`id`(唯一主键索引)或`code`(非unique索引)进行查询,例如`select * from t where id = xxx`或`select * from t where code = xxx`时,可能只会进行2~3次磁盘io(1000w数据构成的B+树其层高为2~3)。
-
-#### 按id进行分区
-如果对表`t`按照`id`进行`hash`分区,分为10个分区,那么:
-- 对于按`id`进行查找的语句`select * from t where id = xxx`
- - 将t按id分为10个区后,如果分区均匀,那么每个分区数据大概为100w,对分区的查询开销大概为2次磁盘io
- - 根据`id`的查询只会在一个分区内进行查找,故而磁盘io会从3次减少为2次,可以提升查询效率
-- 对于按`code`进行查找的语句`select * from t where code = xxx`
- - 对于按code进行查找的语句,需要扫描所有的10个分区,每个分区大概需要2次磁盘io,故而总共的磁盘io大约为20次
-
-> 在使用分区表时,应尽量小心,不正确的使用分区将可能会带来大量的io,造成性能瓶颈
-
-### 在表和分区之间交换数据
-mysql支持在表分区和非分区表之间交换数据:
-- 在非分区表为空的场景下,相当于将分区中的数据移动到非分区表中
-- 在表分区为空的场景下,相当于将非分区表中的数据移动到表分区中
-
-在表和分区之间交换数据,可以通过`alter table ... exchange partition`语句,且必须满足如下条件:
-- 要交换的非分区表和分区表必须要拥有相同的结构,但是,非分区表中不能够含有分区
-- 非分区表中的数据都要位于表分区的范围内
-- 被交换的表中不能含有外键,或是其他表含有被交换表的外键引用
-- 用户需要拥有`alter, insert, create, drop`权限
-- 使用`alter table ... exchange parition`语句时,不会触发交换表和被交换表上的触发器
-- `auto_increment`将会被重置
-
-`exchange partition ... with table`的示例如下:
-```sql
-alter table p_range_columns_t exchange partition p_2024 with table np_t
-```
+- [表](#表)
+ - [索引组织表](#索引组织表)
+ - [innodb逻辑存储结构](#innodb逻辑存储结构)
+ - [表空间](#表空间)
+ - [innodb\_file\_per\_table](#innodb_file_per_table)
+ - [段(segment)](#段segment)
+ - [区(Extent)](#区extent)
+ - [页(Page)](#页page)
+ - [行](#行)
+ - [innodb行记录格式](#innodb行记录格式)
+ - [Compact](#compact)
+ - [变长字段长度列表](#变长字段长度列表)
+ - [NULL标志位](#null标志位)
+ - [记录头信息](#记录头信息)
+ - [行溢出数据](#行溢出数据)
+ - [dynamic](#dynamic)
+ - [char存储结构](#char存储结构)
+ - [innodb数据页结构](#innodb数据页结构)
+ - [File Header](#file-header)
+ - [Infimum和Supremum record](#infimum和supremum-record)
+ - [user record 和 free space](#user-record-和-free-space)
+ - [page directory](#page-directory)
+ - [B+树索引](#b树索引)
+ - [File Trailer](#file-trailer)
+ - [完整性校验](#完整性校验)
+ - [分区表](#分区表)
+ - [partition keys \& primary keys \& unique keys](#partition-keys--primary-keys--unique-keys)
+ - [表中不存在唯一索引](#表中不存在唯一索引)
+ - [后续向分区表添加唯一索引](#后续向分区表添加唯一索引)
+ - [对非分区表进行分区](#对非分区表进行分区)
+ - [分区类型](#分区类型)
+ - [RANGE](#range)
+ - [information\_schema.partitions](#information_schemapartitions)
+ - [看select语句查询了哪些分区](#看select语句查询了哪些分区)
+ - [插入超过分区范围的数据](#插入超过分区范围的数据)
+ - [向分区表中添加分区](#向分区表中添加分区)
+ - [向分区表中删除分区](#向分区表中删除分区)
+ - [LIST](#list)
+ - [HASH](#hash)
+ - [新增HASH分区](#新增hash分区)
+ - [减少HASH分区](#减少hash分区)
+ - [LINEAR HASH](#linear-hash)
+ - [KEY \& LINEAR KEY](#key--linear-key)
+ - [COLUMNS](#columns)
+ - [range columns](#range-columns)
+ - [list columns](#list-columns)
+ - [子分区](#子分区)
+ - [分区中的NULL值](#分区中的null值)
+ - [分区和性能](#分区和性能)
+ - [不分区](#不分区)
+ - [按id进行分区](#按id进行分区)
+ - [在表和分区之间交换数据](#在表和分区之间交换数据)
+
+
+# 表
+## 索引组织表
+innodb存储引擎中,表都是根据主键顺序组织存放的,这种存储方式被称为索引组织表(index organized table)。在innodb存储引擎表中,每张表都有主键(primary key),如果在创建表时没有显式指定主键,那么innodb会按照如下方式创建主键:
+- 首先判断表中是否存在非空的唯一索引(unique not null)字段,如果有,则其为主键
+- 如果不存在非空唯一索引,那么innodb会自动创建一个6字节大小的指针作为主键
+
+如果有多个非空唯一索引,innodb存储引擎将会选择第一个定义的非空唯一索引作为主键。
+
+## innodb逻辑存储结构
+在innodb的存储逻辑结构中,所有的数据都被逻辑存放在表空间(table space)中。表空间则由`段(segement),区(extent),页(page)`组成。
+
+组成如图所示:
+
+
-如上图所示,innodb中的数据是按照索引来进行组织的。但是,通过B+树索引,其无法直接查询到指定的记录,其只能查询到记录所位于的页。
-
-例如,在上图示例中,其在查询`ID=32`的时,只能查询到该记录位于page 17中。
-
-> 在B+树的叶子节点,每个页的File Header中都存有指向前一个页和后一个页的指针,`故而每个页之间是通过双向列表结构来维护的`;但是对于页中的记录,`记录与记录之间维维护的时单向列表的关系`。
->
-> 对于Compact或Dynamic行格式的页,其每条记录的record header中都包含一个next_record字段指向下一条记录。故而,位于同一个页中的记录可以单向访问。
-
-但是,在一个页内查找某条记录时,沿着单向链表进行查找其效率很低。故而,page中的数据时机被分为了多个组,被分为的组构成了一个subdirectory,故而,通过子目录能够缩小查询范围,提高查询性能。
-
-page directory是一个能够存储多个slots的部分,每个slot中存储了group中最后一条记录的相对位置。假设slot中最大一条记录为`r`,那么group中记录的条数被存储在`r`记录record header的`n_owned`字段中。
-
-group中record的数量约束如下:
-- infimum group中records数量限制为`[1,8]`
-- supremum group中records数量限制为`[1,8]`
-- 其他group中records限制为`[4,8]`
-
-page directory生成过程如下所示:
-- 最开始时,页中只有infimum和supremum两条记录,它们分别属于两个group。page directory中有两个slots指向这两条记录,两个slot的n_owned都为1
-- 后续,当新的记录被插入页时,系统会查找page directory中主键值大于待插入记录的第一个slot。slot对应最大记录的`n_owned`字段会增加1,代表group中新插入了记录,直到group中的记录数量到达8
-- 当新纪录被插入到的group中记录数大于8时,group中的记录被分为2个group,一个group包含4条记录,另一个group包含5条记录。该过程将会向page directory中新增一个新的slot
-- 当记录被删除时,slot最最大一条记录的`n_owned`将会减少1,当n_owned字段小于4时,会触发再平衡操作,平衡后的page directory满足上述要求
-
-page directory中的slots数量如page header中的`PAGE_N_DIR_SLOTS`所示。
-
-一旦innodb中页包含page directory后,其会通过二分查找快速的定位slot,并且从group中最小记录开始,通过`next_record`指针来遍历页中的记录列表。这样能够快速的定位记录位置。
-
-### File Trailer
-
-#### 完整性校验
-在innodb中,页的大小为16KB,可能和磁盘的扇区大小不同。通常磁盘的扇区大小为512字节,故而在写入一个页到磁盘中时,需要分32个扇区进行写入。
-
-在写入一个页时,可能会发生宕机场景,这时,一个页只写入了一部分,可能会发生脏写。此时,可以通过double write buffer机制对脏写的页进行恢复。
-
-在一个页被写入到磁盘中时,首先会被写入的是File Header的`FIL_PAGE_SPACE_OR_CHKSUM`,该部分是page的checksum。
-
-innodb设置了File Trailer部分来校验page是否被完全写入到磁盘中,File Trailer中只包含一个`FIL_PAGE_END_LSN`部分,占用8字节,前4字节代表该页的checksum值,后4字节和File Header中的`FIL_PAGE_LSN`相同,`代表最后一次修改该页关联的LSN位置`。将上述两个字段和File Header中的`FIL_PAGE_SPACE_OR_CHKSUM`和`FIL_PAGE_LSN`值进行比较,查看是否一致,从而保证页的完整性。
-
-默认情况下,在innodb每次从磁盘读取page时,都会检查页面的完整性。
-
-## 分区表
-innodb存储引擎支持分区功能,分区过程将一个表或索引分为多个更小、更可管理的部分。
-
-对于访问数据库的应用而言,逻辑上的一个表或索引,其物理上可能由多个物理分区组成,每个分区都是独立的对象,既可以独自进行处理,又可以作为一个更大对象的一部分进行处理。
-
-> mysql仅支持水平分区(将同一张表中的不同行记录分配到不同的物理文件中),并不支持垂直分区(将同一张表中的不同列分配到不同的物理文件中)。
-
-目前mysql支持如下几种类型的分区:
-- `RANGE`: 行数据基于一个给定连续区间的列值被放入分区
-- `LIST`: 和`RANGE`类似,但`LIST`分区面对的是更加离散的值
-- `HASH`: 根据用户自定义的表达式返回值来进行分区,返回值不能为负数
-- `KEY`:根据mysql提供的哈希函数来进行分区
-
-`不论创建何种类型的分区,如果表中存在唯一索引或主键,分区列必须是唯一索引的一个组成部分。`
-
-### partition keys & primary keys & unique keys
-对于分区表而言,`所有在partition expression中使用到的col,其必须被包含在分区表所有的唯一索引中`。
-
-> `所有唯一索引`中包含主键索引。
-
-正确建立分区表的声明示例如下:
-```sql
-CREATE TABLE t1 (
- col1 INT NOT NULL,
- col2 DATE NOT NULL,
- col3 INT NOT NULL,
- col4 INT NOT NULL,
- UNIQUE KEY (col1, col2, col3)
-)
-PARTITION BY HASH(col3)
-PARTITIONS 4;
-
-CREATE TABLE t2 (
- col1 INT NOT NULL,
- col2 DATE NOT NULL,
- col3 INT NOT NULL,
- col4 INT NOT NULL,
- UNIQUE KEY (col1, col3)
-)
-PARTITION BY HASH(col1 + col3)
-PARTITIONS 4;
-
-
-CREATE TABLE t7 (
- col1 INT NOT NULL,
- col2 DATE NOT NULL,
- col3 INT NOT NULL,
- col4 INT NOT NULL,
- PRIMARY KEY(col1, col2)
-)
-PARTITION BY HASH(col1 + YEAR(col2))
-PARTITIONS 4;
-
-CREATE TABLE t8 (
- col1 INT NOT NULL,
- col2 DATE NOT NULL,
- col3 INT NOT NULL,
- col4 INT NOT NULL,
- PRIMARY KEY(col1, col2, col4),
- UNIQUE KEY(col2, col1)
-)
-PARTITION BY HASH(col1 + YEAR(col2))
-PARTITIONS 4;
-
-
-create table t2_partition (
- col1 int ,
- col2 date,
- col3 int null,
- col4 int null,
- unique index `idx_t2_partition_cols` (col1, col2,col3),
- primary key (col2, col1)
-)
-partition by hash(col1)
-partitions 4;
-```
-#### 表中不存在唯一索引
-如果表中没有唯一索引(也未定义primary key),那么上述要求并不会生效,可以在partition expression中使用任意cols。
-
-#### 后续向分区表添加唯一索引
-如果想要向分区表中添加唯一索引,那么新增的唯一索引中必须包含partition expression中所有的列。
-
-#### 对非分区表进行分区
-可以参照如下示例对非分区表进行分区:
-```sql
-CREATE TABLE np_pk (
- id INT NOT NULL AUTO_INCREMENT,
- name VARCHAR(50),
- added DATE,
- PRIMARY KEY (id)
-);
-```
-可以按`id`进行分区
-```sql
-ALTER TABLE np_pk
- PARTITION BY HASH(id)
- PARTITIONS 4;
-```
-### 分区类型
-#### RANGE
-RANGE为较常见的分区类型,如下示例为创建RANGE类型分区表的示例:
-```sql
-create table t1 (
- id bigint auto_increment not null,
- tran_date datetime(6) not null default now(6) on update now(6),
- primary key (id, tran_date)
-) engine=innodb
-partition by range (year(tran_date)) (
- partition part_y_let_2024 values less than (2025),
- partition part_y_eq_2025 values less than (2026)
- );
-```
-上述创建了表`t1`,t1主键为`(id, tran_date)`,且按照`tran_date`字段的年部分进行分区,分区类型为RANGE。
-
-表t1的分区为两部分,分区1为`tran_date位于2024或之前年份`的分区`part_y_let_2024`,分区2是`tran_date位于2025年`的分区`part_y_eq_2025`。
-
-##### information_schema.partitions
-如果要查看表的分区情况,可以查询`information_schema.partitions`表,示例如下
-```sql
-select * from information_schema.partitions where table_schema = 'learn_innodb' and table_name = 't1';
-```
-查询结果如下所示:
-| TABLE\_CATALOG | TABLE\_SCHEMA | TABLE\_NAME | PARTITION\_NAME | SUBPARTITION\_NAME | PARTITION\_ORDINAL\_POSITION | SUBPARTITION\_ORDINAL\_POSITION | PARTITION\_METHOD | SUBPARTITION\_METHOD | PARTITION\_EXPRESSION | SUBPARTITION\_EXPRESSION | PARTITION\_DESCRIPTION | TABLE\_ROWS | AVG\_ROW\_LENGTH | DATA\_LENGTH | MAX\_DATA\_LENGTH | INDEX\_LENGTH | DATA\_FREE | CREATE\_TIME | UPDATE\_TIME | CHECK\_TIME | CHECKSUM | PARTITION\_COMMENT | NODEGROUP | TABLESPACE\_NAME |
-| :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- |
-| def | learn\_innodb | t1 | part\_y\_eq\_2025 | null | 2 | null | RANGE | null | year\(\`tran\_date\`\) | null | 2026 | 0 | 0 | 16384 | 0 | 0 | 0 | 2025-02-08 01:05:53 | null | null | null | | default | null |
-| def | learn\_innodb | t1 | part\_y\_let\_2024 | null | 1 | null | RANGE | null | year\(\`tran\_date\`\) | null | 2025 | 0 | 0 | 16384 | 0 | 0 | 0 | 2025-02-08 01:05:53 | null | null | null | | default | null |
-
-为分区表预置如下数据
-```sql
-insert into t1(tran_date) values ('2023-01-01'), ('2024-12-31'), ('2025-01-01');
-```
-可以看到分区表中数据分布如下:
-```sql
-select partition_name, table_rows from information_schema.partitions where table_schema = 'learn_innodb' and table_name = 't1';
-```
-| PARTITION\_NAME | TABLE\_ROWS |
-| :--- | :--- |
-| part\_y\_eq\_2025 | 1 |
-| part\_y\_let\_2024 | 2 |
-
-易知`('2023-01-01'), ('2024-12-31')`数据位于`part_y_let_2024`分区,故而该分区存在两条数据;而`('2025-01-01')`数据位于`part_y_let_2024`分区,该分区存在一条数据。
-
-##### 看select语句查询了哪些分区
-数据分布可以通过如下方式验证:
-```sql
-explain select * from t1 where tran_date >= '2023-01-01' and tran_date <= '2024-12-31';
-```
-| id | select\_type | table | partitions | type | possible\_keys | key | key\_len | ref | rows | filtered | Extra |
-| :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- |
-| 1 | SIMPLE | t1 | part\_y\_let\_2024 | index | PRIMARY | PRIMARY | 16 | null | 2 | 50 | Using where; Using index |
-
-```sql
-explain select * from t1 where tran_date >= '2025-01-01'
-```
-| id | select\_type | table | partitions | type | possible\_keys | key | key\_len | ref | rows | filtered | Extra |
-| :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- |
-| 1 | SIMPLE | t1 | part\_y\_eq\_2025 | index | PRIMARY | PRIMARY | 16 | null | 1 | 100 | Using where; Using index |
-
-##### 插入超过分区范围的数据
-如果尝试向分区表中插入超过所有分区范围的数据,会执行失败,示例如下:
-```sql
-insert into t1(tran_date) values ('2026-01-01');
-```
-由于分区表`t1`中现有分区最大只支持2025年的分区,故而当尝试插入2026年分区时,会抛出如下错误:
-```bash
-[2025-02-08 01:32:51] [HY000][1526] Table has no partition for value 2026
-```
-##### 向分区表中添加分区
-mysql支持向分区表中添加分区,语法如下
-```sql
-alter table t1 add partition (
- partition part_year_egt_2026 values less than maxvalue
- );
-```
-添加分区后,mysql支持`tran_date大于等于2026`的分区,执行如下语句
-```sql
-insert into t1(tran_date) values ('2026-01-01'), ('2027-12-31'), ('2028-01-01');
-```
-之后,再次分区分区中的数据分区,结果如下
-| PARTITION\_NAME | TABLE\_ROWS |
-| :--- | :--- |
-| part\_y\_eq\_2025 | 1 |
-| part\_y\_let\_2024 | 2 |
-| part\_year\_egt\_2026 | 3 |
-
-> `information.partitions`表中,`table_rows`字段可能存在不准确的情况,如果想要获取准确的值,需要执行`analyze table {schema}.{table_name}`语句
-
-##### 向分区表中删除分区
-当想要删除分区表中现存分区时,可以通过执行如下语句
-```sql
-alter table t1 drop partition part_year_egt_2026;
-```
-在删除分区后,分区中的数据也会被删除,执行查询语句后
-```sql
-select * from t1;
-
-```
-可知`part_year_egt_2026`被删除后分区中数据全部消失
-| id | tran\_date |
-| :--- | :--- |
-| 1 | 2023-01-01 00:00:00.000000 |
-| 2 | 2024-12-31 00:00:00.000000 |
-| 3 | 2025-01-01 00:00:00.000000 |
-
-#### LIST
-LIST分区类型和RANGE分区类型非常相似,但是LIST分区列的值是离散的,RANGE分区列的值是连续的。
-
-创建LIST类型分区表的示例如下:
-```sql
-create table p_list_t1 (
- id bigint not null auto_increment,
- area smallint not null,
- primary key (id, area)
-)
-partition by list (area) (
- partition p_ch_beijing values in (1),
- partition p_ch_hubei values in (2),
- partition p_ch_jilin values in (3)
- );
-```
-之后可向`p_list_t1`表中预置数据,执行语句如下:
-```sql
-insert into p_list_t1(area) values (1),(1), (2), (3), (3);
-```
-此时,数据分布如下:
-| PARTITION\_METHOD | PARTITION\_NAME | TABLE\_ROWS |
-| :--- | :--- | :--- |
-| LIST | p\_ch\_beijing | 2 |
-| LIST | p\_ch\_hubei | 1 |
-| LIST | p\_ch\_jilin | 2 |
-
-如果想要向分区表中插入不位于现存分区中的值,那么插入语句同样会执行失败,示例如下
-```sql
-insert into p_list_t1(area) values (4);
-```
-由于目前没有area为4的分区,故而插入语句执行失败,报错如下
-```bash
-[2025-02-09 20:30:03] [HY000][1526] Table has no partition for value 4
-```
-
-#### HASH
-HASH分区方式是将数据均匀分布到预先定义的各个分区中,期望各个分区中散列的数据数量大致相同。
-
-在通过hash来进行分区时,建表时需要指定一个分区表达式,该表达式返回整数。
-
-创建hash分区的示例如下:
-```sql
-create table p_hash_t1 (
- id bigint not null auto_increment,
- content varchar(256),
- primary key (id)
-)
-partition by hash (id)
-partitions 4;
-```
-上述ddl创建了一个按照`id`列进行hash分区的分区表,分区表包含4个分区。
-
-预置数据sql如下:
-```sql
-insert into p_hash_t1(content) values ('asahi'), ('maki'), ('katahara');
-```
-预置数据后数据分布如下
-| PARTITION\_METHOD | PARTITION\_NAME | TABLE\_ROWS |
-| :--- | :--- | :--- |
-| HASH | p0 | 0 |
-| HASH | p1 | 1 |
-| HASH | p2 | 1 |
-| HASH | p3 | 1 |
-
-预置的三条数据id分别为`1, 2, 3`,被hash放置到分区`p1, p2, p3`中。
-
-> 当使用hash分区方式时,例如存在`4`个分区,对于待插入数据其分区表达式的值为`2`,那么待插入数据将会被插入到`2%4 = 2`,第`3`个分区中(0,1,2分区,排第三),也就是`p2`。
->
-> 可以通过`explain select * from p_hash_t1 where id = 2;`语句来进行验证,得到如下结果。
->
-> | id | select\_type | table | partitions | type | possible\_keys | key | key\_len | ref | rows | filtered | Extra |
-> | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- |
-> | 1 | SIMPLE | p\_hash\_t1 | p2 | const | PRIMARY | PRIMARY | 8 | const | 1 | 100 | null |
-
-
-##### 新增HASH分区
-对于hash分区方式,可以通过如下方式来新增分区:
-```sql
-alter table p_hash_t1 add partition partitions 3;
-```
-其会新增3个分区,执行后分区数量为7。
-
-此时,原本分区中的数据会被重新散列到新分区中
-
-##### 减少HASH分区
-对于hash分区,在尝试减少分区数量的同时,通常不希望删除任何数据,故而无法使用`drop`。
-
-故而,可以使用`coalesce`,其只会减少分区数量,不会删除数据。
-
-示例如下:
-```sql
-alter table p_hash_t1 coalesce partition 4;
-```
-上述语句会将分区数量减少4个,故而减少后分区数量为`3`。
-
-
-#### LINEAR HASH
-创建linear hash分区表的方式和hash类似,可以通过如下方式
-```sql
-create table p_linear_hash_t1 (
- id bigint not null auto_increment,
- content varchar(256),
- primary key(id)
-)
-partition by linear hash (id)
-partitions 5;
-```
-相较于hash分区,在使用linear hash分区时,添加、删除、合并、拆分分区将会变得更加快捷,但是相比于hash分区,其数据分区可能会不太均匀。
-
-#### KEY & LINEAR KEY
-KEY分区方式和HASH分区方式类似,但是HASH分区采用用户自定义的函数进行分区,而KEY分区方式则是采用mysql提供的函数进行分区。
-
-创建key分区表的示例如下:
-```sql
-create table p_key_t1 (
- id bigint not null auto_increment,
- content varchar(256),
- primary key(id)
-)
-partition by key(id)
-partitions 5;
-```
-> key分区方式同样可以使用linear进行修饰,效果和hash分区方式类似。
-
-> 对于key分区,可以指定除了integer之外的col类型,而`range, list, hash`等分区类型只支持integer类型的col。
-
-
-#### COLUMNS
-COLUMNS分区方式为`RANGE`和`LIST`分区的变体。
-
-COLUMNS分区方式支持在分区时使用多个列,在插入新数据或查询数据决定分区时,所有的列都会被考虑。
-
-COLUMNS分区方式分为如下两种
-- RANGE COLUMNS
-- LIST COLUMNS
-
-上述两种方式都支持非整数类型的列,COLUMNS支持的数据类型如下:
-- 所有integers类型(DECIMAL, FLOAT则不受支持)
-- DATE和DATETIME类型
-- 字符串类型:CHAR, VARCHAR, BINARY, VARBINARY(TEXT, BLOB类型不受支持)
-
-##### range columns
-创建range columns分区表的示例如下:
-```sql
-create table p_range_columns_t1 (
- id bigint not null auto_increment,
- name varchar(256),
- born_ts datetime(6),
- primary key (id, born_ts)
-)
-partition by range columns (born_ts) (
- partition p0 values less than ('1900-01-01'),
- partition p1 values less than ('2000-01-01'),
- partition p2 values less than ('2999-01-01')
- );
-```
-
-##### list columns
-创建list columns分区表的示例则如下:
-```sql
-create table p_list_columns_t1 (
- id bigint not null auto_increment,
- province varchar(256),
- city varchar(256),
- primary key (id, province, city)
-)
-partition by list columns (province, city) (
- partition p_beijing values in (('china', 'beijing')),
- partition p_wuhan values in (('hubei', 'wuhan'))
- );
-```
-
-> 通过range columns和list columns,可以很好的替代range和list分区,而无需将列值都转换为整型。
-
-### 子分区
-`子分区`代表在分区的基础上再次进行分区,mysql允许`在range和list分区的基础`上再次进行`hash或key`的子分区,示例如下:
-```sql
-create table p_list_columns_t1 (
- id bigint not null auto_increment,
- province varchar(256),
- city varchar(256),
- primary key (id, province, city)
-)
-partition by list columns (province, city)
-subpartition by key(id)
-subpartitions 3
-(
- partition p_beijing values in (('china', 'beijing')),
- partition p_wuhan values in (('hubei', 'wuhan'))
-);
-```
-上述示例先按照`list columns`分区方式进行了分区,然后在为每个分区都按`key`分了三个子分区,查看分区和子分区详情可以通过如下语句:
-```sql
-select partition_name, partition_method, subpartition_name, subpartition_method from information_schema.partitions where table_name = 'p_list_columns_t1';
-```
-| PARTITION\_NAME | PARTITION\_METHOD | SUBPARTITION\_NAME | SUBPARTITION\_METHOD |
-| :--- | :--- | :--- | :--- |
-| p\_wuhan | LIST COLUMNS | p\_wuhansp0 | KEY |
-| p\_wuhan | LIST COLUMNS | p\_wuhansp1 | KEY |
-| p\_wuhan | LIST COLUMNS | p\_wuhansp2 | KEY |
-| p\_beijing | LIST COLUMNS | p\_beijingsp0 | KEY |
-| p\_beijing | LIST COLUMNS | p\_beijingsp1 | KEY |
-| p\_beijing | LIST COLUMNS | p\_beijingsp2 | KEY |
-
-### 分区中的NULL值
-mysql允许对null值做分区,但`mysql数据库中的分区总是视null值小于任何非null的值`,该逻辑`和order by处理null值的逻辑一致`。
-
-故而,在使用不同的分区类型时,对于null值的处理逻辑如下:
-- 对于range类型分区,当插入null值时,其会被放在最左侧的分区中
-- 对于list类型的分区,如果要插入null值,必须在分区的`values in (...)`表达式中指定null值,否则插入语句将会报错
-- hash和key的分区类型,将会将null值当作`0`来散列
-
-### 分区和性能
-对于OLTP类型的应用,使用分区表时应该相当小心,因为分区表可能会带来严重的性能问题。
-
-例如,对于包含1000w条数据的表`t`,如果包含主键索引`id`和非主键索引`code`,分区和不分区,其性能分析如下
-
-#### 不分区
-如果不对表t进行分区,那么根据`id`(唯一主键索引)或`code`(非unique索引)进行查询,例如`select * from t where id = xxx`或`select * from t where code = xxx`时,可能只会进行2~3次磁盘io(1000w数据构成的B+树其层高为2~3)。
-
-#### 按id进行分区
-如果对表`t`按照`id`进行`hash`分区,分为10个分区,那么:
-- 对于按`id`进行查找的语句`select * from t where id = xxx`
- - 将t按id分为10个区后,如果分区均匀,那么每个分区数据大概为100w,对分区的查询开销大概为2次磁盘io
- - 根据`id`的查询只会在一个分区内进行查找,故而磁盘io会从3次减少为2次,可以提升查询效率
-- 对于按`code`进行查找的语句`select * from t where code = xxx`
- - 对于按code进行查找的语句,需要扫描所有的10个分区,每个分区大概需要2次磁盘io,故而总共的磁盘io大约为20次
-
-> 在使用分区表时,应尽量小心,不正确的使用分区将可能会带来大量的io,造成性能瓶颈
-
-### 在表和分区之间交换数据
-mysql支持在表分区和非分区表之间交换数据:
-- 在非分区表为空的场景下,相当于将分区中的数据移动到非分区表中
-- 在表分区为空的场景下,相当于将非分区表中的数据移动到表分区中
-
-在表和分区之间交换数据,可以通过`alter table ... exchange partition`语句,且必须满足如下条件:
-- 要交换的非分区表和分区表必须要拥有相同的结构,但是,非分区表中不能够含有分区
-- 非分区表中的数据都要位于表分区的范围内
-- 被交换的表中不能含有外键,或是其他表含有被交换表的外键引用
-- 用户需要拥有`alter, insert, create, drop`权限
-- 使用`alter table ... exchange parition`语句时,不会触发交换表和被交换表上的触发器
-- `auto_increment`将会被重置
-
-`exchange partition ... with table`的示例如下:
-```sql
-alter table p_range_columns_t exchange partition p_2024 with table np_t
-```
+- [表](#表)
+ - [索引组织表](#索引组织表)
+ - [innodb逻辑存储结构](#innodb逻辑存储结构)
+ - [表空间](#表空间)
+ - [innodb\_file\_per\_table](#innodb_file_per_table)
+ - [段(segment)](#段segment)
+ - [区(Extent)](#区extent)
+ - [页(Page)](#页page)
+ - [行](#行)
+ - [innodb行记录格式](#innodb行记录格式)
+ - [Compact](#compact)
+ - [变长字段长度列表](#变长字段长度列表)
+ - [NULL标志位](#null标志位)
+ - [记录头信息](#记录头信息)
+ - [行溢出数据](#行溢出数据)
+ - [dynamic](#dynamic)
+ - [char存储结构](#char存储结构)
+ - [innodb数据页结构](#innodb数据页结构)
+ - [File Header](#file-header)
+ - [Infimum和Supremum record](#infimum和supremum-record)
+ - [user record 和 free space](#user-record-和-free-space)
+ - [page directory](#page-directory)
+ - [B+树索引](#b树索引)
+ - [File Trailer](#file-trailer)
+ - [完整性校验](#完整性校验)
+ - [分区表](#分区表)
+ - [partition keys \& primary keys \& unique keys](#partition-keys--primary-keys--unique-keys)
+ - [表中不存在唯一索引](#表中不存在唯一索引)
+ - [后续向分区表添加唯一索引](#后续向分区表添加唯一索引)
+ - [对非分区表进行分区](#对非分区表进行分区)
+ - [分区类型](#分区类型)
+ - [RANGE](#range)
+ - [information\_schema.partitions](#information_schemapartitions)
+ - [看select语句查询了哪些分区](#看select语句查询了哪些分区)
+ - [插入超过分区范围的数据](#插入超过分区范围的数据)
+ - [向分区表中添加分区](#向分区表中添加分区)
+ - [向分区表中删除分区](#向分区表中删除分区)
+ - [LIST](#list)
+ - [HASH](#hash)
+ - [新增HASH分区](#新增hash分区)
+ - [减少HASH分区](#减少hash分区)
+ - [LINEAR HASH](#linear-hash)
+ - [KEY \& LINEAR KEY](#key--linear-key)
+ - [COLUMNS](#columns)
+ - [range columns](#range-columns)
+ - [list columns](#list-columns)
+ - [子分区](#子分区)
+ - [分区中的NULL值](#分区中的null值)
+ - [分区和性能](#分区和性能)
+ - [不分区](#不分区)
+ - [按id进行分区](#按id进行分区)
+ - [在表和分区之间交换数据](#在表和分区之间交换数据)
+
+
+# 表
+## 索引组织表
+innodb存储引擎中,表都是根据主键顺序组织存放的,这种存储方式被称为索引组织表(index organized table)。在innodb存储引擎表中,每张表都有主键(primary key),如果在创建表时没有显式指定主键,那么innodb会按照如下方式创建主键:
+- 首先判断表中是否存在非空的唯一索引(unique not null)字段,如果有,则其为主键
+- 如果不存在非空唯一索引,那么innodb会自动创建一个6字节大小的指针作为主键
+
+如果有多个非空唯一索引,innodb存储引擎将会选择第一个定义的非空唯一索引作为主键。
+
+## innodb逻辑存储结构
+在innodb的存储逻辑结构中,所有的数据都被逻辑存放在表空间(table space)中。表空间则由`段(segement),区(extent),页(page)`组成。
+
+组成如图所示:
+
+