diff --git a/mysql/mysql集群/Mysql Group Replication.md b/mysql/mysql集群/Mysql Group Replication.md
index 9e33b92..b782b9b 100644
--- a/mysql/mysql集群/Mysql Group Replication.md
+++ b/mysql/mysql集群/Mysql Group Replication.md
@@ -17,6 +17,16 @@
- [Group Membership](#group-membership)
- [group\_replication\_member\_expel\_timeout](#group_replication_member_expel_timeout)
- [Failure detection](#failure-detection)
+ - [Fault-tolerance](#fault-tolerance)
+ - [Observability](#observability)
+ - [group replication plugin architecture](#group-replication-plugin-architecture)
+ - [APIs for Capture, Apply, Lifecycle](#apis-for-capture-apply-lifecycle)
+ - [components](#components)
+ - [protocol](#protocol)
+ - [GCS API/XCom](#gcs-apixcom)
+ - [Getting Started](#getting-started)
+ - [Deploying Group Replication in Single-Primary Mode](#deploying-group-replication-in-single-primary-mode)
+ - [Deploying Instances for Group Replication](#deploying-instances-for-group-replication)
# Mysql Group Replication
@@ -246,4 +256,90 @@ group replication failure detection mechanism是一个分布式的service,用
将不参与communicating的member驱逐出group是必要的,因为group在对transaction或view change需要majority of members达成一致。如果member不参与这些决策,group必须对member进行移除,从而增加group中包含majority of correctly working members的可能性,从而能够继续处理transactions。
-在replication group中,每两个member间都有一个point-to-point的communication channel,从而形成了一个full connected graph。这些连接通过group communication engine(XCom, a Paxos variant)来进行管理,来凝结使用TCP/IP sockets。
\ No newline at end of file
+在replication group中,每两个member间都有一个point-to-point的communication channel,从而形成了一个full connected graph。这些连接通过group communication engine(XCom, a Paxos variant)来进行管,连接使用TCP/IP sockets。
+
+如果member经过5s都没有从另一个member处接收到消息,那么其会假设另一个member已经处于failed状态,并且在其自己的`performance_schema.replication_group_members`中将failed member的状态标记为`UNREACHABLE`。通常来说,两个member都会假定对方failed,因为二者之间没有进行通信。但是,有小概率存在如下场景:member A假定member B处于failed状态,但是member B仍然认为member A正常;这可能是由routing和firewall导致的问题。当member被group的其他members怀疑时,其将假设所有的其他members都已经失败。
+
+如果怀疑持续超过10s,那么发出怀疑的member将会尝试将`被怀疑member可能已经失败`的观点传播给group中的其他members。如果member实际上和group中的其他members隔离,其会尝试传播其view,但是该传播不会产生任何后果,因为其无法让其view与其他members达成共识。
+
+`怀疑`只会在满足如下条件时生效:
+- memeber是notifier
+- 怀疑持续的时间足够长,可以被传播到group中的其他members
+- group中其他的members就该怀疑达成一致
+
+在该种场景下,被怀疑member将会根据协调决策被标记为`从group中移除`的状态,并且在等待`group_replication_member_expel_timeout`后,由移除机制检测到并执行移除操作。
+
+### Fault-tolerance
+mysql group replication基于Paxos分布式算法来实现,为servers间提供了分布式协调。故而,其需要`majority of servers`处于活跃状态,从而参与决策。这直接影响了系统可以容忍的`failures`个数。
+
+> `当server的数量为2*f+1时,其能够容忍f个failures`
+
+故而,能够影响1个failure的group必须含有3个servers。当一个server失败时,剩下的2个servers仍然能够形成majority(2~3),并允许系统继续执行决策。但是,当故障的server达到两台时,group将会陷入阻塞状态,因无法达成majority的决策条件。
+
+下表展示了不同group规模下可容忍的failures数量和形成majority的数量
+| group size | majority | instant failures tolerated |
+| :-: | :-: | :-: |
+| 1 | 1 | 0 |
+| 2 | 2 | 0 |
+| 3 | 2 | 1 |
+| 4 | 3 | 1 |
+| 5 | 3 | 2 |
+| 6 | 4 | 2 |
+| 7 | 4 | 3 |
+
+若group size为n,各指标计算公式如下:
+- `majority`: `floor(n/2)+1`
+- `tolerated failures`: `n - floor(n/2) - 1`
+
+### Observability
+在group replication plugin中,存在大量的自动功能,但是,有时需要对其进行观测。故而,整个系统的状态(包括view、冲突数据、service状态)可以通过`performance_schema`的表来查询。`replication protocol的分布式特性`以及`servers就元数据和事务达成一致并同步的事实`,使得检查group状态变得更加容易。
+
+例如,可以通过连接到single server并通过select语句查询performance_schema中对应的表来获取local information和global information。
+
+### group replication plugin architecture
+mysql group replication是mysql plugin,其基于现存的mysql replication结构构建,利用了binary log、row-based logging、global transaction identifiers等特性。其和当前mysql的框架做了集成,例如`performance_schema`、plugin和service结构。下图展示了mysql group replication的架构:
+
+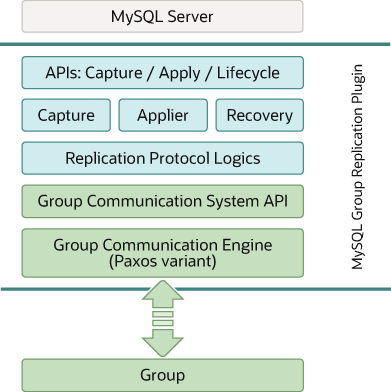 +
+#### APIs for Capture, Apply, Lifecycle
+mysql group replication plugin包含了一系列用于capture、apply、lifecycle的API,其可以用于控制plugin和mysql server的交互。存在令消息在server和plugin之间双向流动的接口,这些接口将mysql server core和group replication plugin进行了隔离,并且接口大部分都是位于事务执行pipeline的hooks。
+
+在server到plugin的方向,存在如下事件通知:
+- server starting
+- server recovering
+- server being ready to accept connections
+- server being about to commit a transaction
+
+在plugin到server的方向,plugin会指示server去执行一些操作,例如`对正在执行中的事务进行提交/回滚`,`将事务放入relay log中排队`
+
+#### components
+再group replication plugin的再下一层,则是一系列components,对被路由给其的notification进行响应。
+- capture component负责对执行事务的上下文进行跟踪
+- applier component负责再database执行远程事务
+- recovery component用于管理分布式recovery,并负责将加入到group的server更新到最新
+
+#### protocol
+再下一层,则是replciation protocol module,包含了replication protocol的特定逻辑。其处理冲突检测,接收事务并将事务传播给group。
+
+#### GCS API/XCom
+最后两层则是GCS API和基于Paxos实现的group communication engine(XCom)。
+
+GCS API是高层API,对构建replicated state machine所需的属性进行了抽象,其将消息曾的实现和插件的上层进行了解耦。
+
+group communication engine则是负责处理replication group中members的通信。
+
+## Getting Started
+mysql group replication为mysql server提供了插件。在group中,每个server都需要配置并安装插件。
+
+### Deploying Group Replication in Single-Primary Mode
+在group中,每个mysql server都可以运行在一台独立的物理host machine上,这也是部署group replication推荐的方式。本次介绍了如何创建一个拥有3个server实例的replication group,每个实例都运行在一个不同的host machine上。
+
+
+
+#### APIs for Capture, Apply, Lifecycle
+mysql group replication plugin包含了一系列用于capture、apply、lifecycle的API,其可以用于控制plugin和mysql server的交互。存在令消息在server和plugin之间双向流动的接口,这些接口将mysql server core和group replication plugin进行了隔离,并且接口大部分都是位于事务执行pipeline的hooks。
+
+在server到plugin的方向,存在如下事件通知:
+- server starting
+- server recovering
+- server being ready to accept connections
+- server being about to commit a transaction
+
+在plugin到server的方向,plugin会指示server去执行一些操作,例如`对正在执行中的事务进行提交/回滚`,`将事务放入relay log中排队`
+
+#### components
+再group replication plugin的再下一层,则是一系列components,对被路由给其的notification进行响应。
+- capture component负责对执行事务的上下文进行跟踪
+- applier component负责再database执行远程事务
+- recovery component用于管理分布式recovery,并负责将加入到group的server更新到最新
+
+#### protocol
+再下一层,则是replciation protocol module,包含了replication protocol的特定逻辑。其处理冲突检测,接收事务并将事务传播给group。
+
+#### GCS API/XCom
+最后两层则是GCS API和基于Paxos实现的group communication engine(XCom)。
+
+GCS API是高层API,对构建replicated state machine所需的属性进行了抽象,其将消息曾的实现和插件的上层进行了解耦。
+
+group communication engine则是负责处理replication group中members的通信。
+
+## Getting Started
+mysql group replication为mysql server提供了插件。在group中,每个server都需要配置并安装插件。
+
+### Deploying Group Replication in Single-Primary Mode
+在group中,每个mysql server都可以运行在一台独立的物理host machine上,这也是部署group replication推荐的方式。本次介绍了如何创建一个拥有3个server实例的replication group,每个实例都运行在一个不同的host machine上。
+
+ +
+上述为replication group的结构示意图。
+
+#### Deploying Instances for Group Replication
+在本示例中,group中会包含3个实例,也是创建group所需的最少示例数。为group增加更多的实例能够提升group的fault tolerance。
+
+当group中包含3个实例时,group可以容忍一个实例的失败。通过向group中添加更多实例,group可容忍的失败实例数量也会增加。group中可以使用的最大实例数量为9.
+
+
+上述为replication group的结构示意图。
+
+#### Deploying Instances for Group Replication
+在本示例中,group中会包含3个实例,也是创建group所需的最少示例数。为group增加更多的实例能够提升group的fault tolerance。
+
+当group中包含3个实例时,group可以容忍一个实例的失败。通过向group中添加更多实例,group可容忍的失败实例数量也会增加。group中可以使用的最大实例数量为9.
+