diff --git a/mysql/mysql集群/CAP Theorem in DBMS.md b/mysql/mysql集群/CAP Theorem in DBMS.md
index 35f7a85..cd6d6f3 100644
--- a/mysql/mysql集群/CAP Theorem in DBMS.md
+++ b/mysql/mysql集群/CAP Theorem in DBMS.md
@@ -3,6 +3,10 @@
- [Consistency](#consistency)
- [Availability](#availability)
- [Partition Tolerance](#partition-tolerance)
+ - [The Trade-Offs in the CAP Theorem](#the-trade-offs-in-the-cap-theorem)
+ - [CA(Consistency and Availability)](#caconsistency-and-availability)
+ - [AP(Availability and Partition Tolerance)](#apavailability-and-partition-tolerance)
+ - [CP(Consistency and Partition Tolerance)](#cpconsistency-and-partition-tolerance)
# CAP Theorem in DBMS
在网络共享数据系统设计中固有的权衡令构建一个可靠且高效的系统十分困难。CAP理论是理解分布式系统中这些权衡的核心基础。CAP理论强调了系统设计者在处理distributed data replication时的局限性。CAP理论指出,在分布式系统中,只能同时满足`一致性、可用性、分区容错`这三个特性中的两种。
@@ -27,8 +31,50 @@ CAP理论是分布式系统的基础概念,其指出分布式系统中所有
### Availability
Availability代表每个对数据项的read/write request要么能被成功处理,要么能收到一个操作无法被完成的响应。每个non-failing节点都会为所有读写请求在合理的时间范围内生成响应。
+其中,“每个节点”代表,即使发生network partition,节点只要不处于failing状态,无论位于network partition的哪一侧,都应该能在合理的时间范围内返回响应。
+
### Partition Tolerance
partition tolerance代表在连接节点的网络发生错误、造成两个或多个分区时,系统仍然能够继续进行操作。通常,在出现network partition时,每个partition中的节点只能彼此互相沟通,跨分区的节点通信被阻断。
这意味着,即使发生network partition,系统仍然能持续运行并保证其一致性。network partition是不可避免地,在网络分区恢复正常后,拥有partition tolerance的分布式系统能够优雅的从分区状态中恢复。
+CAP理论指出分布式数据库最多只能兼顾如下三个特性中的两种:consistency, availability, partition tolerance。
+
+ +
+## The Trade-Offs in the CAP Theorem
+CAP理论表明分布式系统中只能同时满足三种特性中的两种。
+### CA(Consistency and Availability)
+> 对于CA类型的系统,其总是可以接收来源于用户的查询和修改数据请求,并且分布式网络中所有database nodes都会返回相同的响应
+
+然而,该种类似的分布式系统在现实世界中不可能存在,因为在network failure发生时,仅有如下两种选项:
+- 发送network failure发生前复制的old data
+- 不允许用户访问old data
+
+如果我们选择第一个选项,那么系统将满足Availibility;如果选择第二个选项,系统则是Consistent。
+
+`在分布式系统中,consistency和availability的组合是不可能的`。为了实现`CA`,系统必须是单体架构,当用户更新系统状态时,所有其他用户都能访问到该更新,这将代表系统满足一致性;而在单体架构中,所有用户都连接到一个节点上,这代表其是可用的。`CA`系统通常不被青睐,因为实现分布式计算必须牺牲consistency或availability中的一种,并将剩余的和partition tolerance组合,即`CP/AP`系统。
+
+> CAP中的A(Availability)只是要求非failing状态下的节点能够在合理的时间范围内返回响应,故而单体架构可以满足`Availability`。
+>
+> 即使单体架构可能因单点故障导致系统不可用,不满足`Reliable`(可靠性),并不影响其满足`Availability`(可用性)。
+
+
+
+## The Trade-Offs in the CAP Theorem
+CAP理论表明分布式系统中只能同时满足三种特性中的两种。
+### CA(Consistency and Availability)
+> 对于CA类型的系统,其总是可以接收来源于用户的查询和修改数据请求,并且分布式网络中所有database nodes都会返回相同的响应
+
+然而,该种类似的分布式系统在现实世界中不可能存在,因为在network failure发生时,仅有如下两种选项:
+- 发送network failure发生前复制的old data
+- 不允许用户访问old data
+
+如果我们选择第一个选项,那么系统将满足Availibility;如果选择第二个选项,系统则是Consistent。
+
+`在分布式系统中,consistency和availability的组合是不可能的`。为了实现`CA`,系统必须是单体架构,当用户更新系统状态时,所有其他用户都能访问到该更新,这将代表系统满足一致性;而在单体架构中,所有用户都连接到一个节点上,这代表其是可用的。`CA`系统通常不被青睐,因为实现分布式计算必须牺牲consistency或availability中的一种,并将剩余的和partition tolerance组合,即`CP/AP`系统。
+
+> CAP中的A(Availability)只是要求非failing状态下的节点能够在合理的时间范围内返回响应,故而单体架构可以满足`Availability`。
+>
+> 即使单体架构可能因单点故障导致系统不可用,不满足`Reliable`(可靠性),并不影响其满足`Availability`(可用性)。
+
+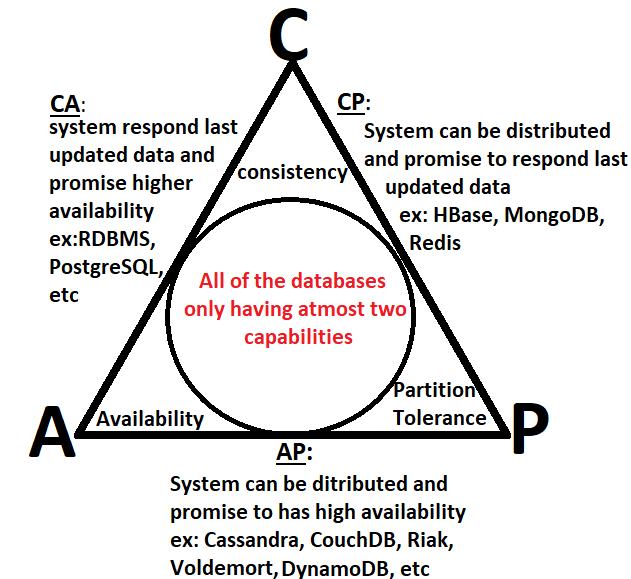 +
+### AP(Availability and Partition Tolerance)
+> 这种类型的系统本质上是分布式的,确保即使在network partition场景下,用户发送的针对database nodes中数据的查看和修改请求不会被丢失
+
+该系统优先考虑了Availability而非Consistency,并且可能会返回过期的数据。一些技术failure可能会导致partition,故而过期数据则是代表partition产生前被同步的数据。
+
+AP系统通常在构建社交媒体网站如Facebook和在线内容网站如YouTube时使用,其并不要求一致性。对于使用AP系统的场景,相比于不一致,不可用会造成更大的问题。
+
+AP系统是分布式的,可以分布于多个节点,即使在network partition发生的前提下也能够可靠运行。
+
+### CP(Consistency and Partition Tolerance)
+> 该类系统本质上是分布式的,确保由用户发起的针对database nodes中数据进行查看或修改的请求,在存在network partition的场景下,会直接被丢弃,而不是返回不一致的数据
+
+`CP`系统优先考虑了Consistency而非Availability,如果发生network partition,其不允许用户从replica读取`在network partition发生前同步的数据`。对于部分应用程序来说,相比于可用性,其更强调数据的一致性,例如股票交易系统、订票系统、银行系统等)
+
+例如,在订票系统中,还剩余一个可订购座位。在该CP系统中,将会创建数据库的副本,并且将副本发送给系统中其他的节点。此时,如果发生网络问题,那么连接到partitioned node的用户将会从replica获取数据。此时,其他连接到unpartitioned部分的用户则可以对剩余的作为进行预定。这样,在连接到partitioned node的用户视角中,仍然存在一个seat,其将导致数据不一致。
+
+在上述场景下,CP系统通常会令其系统对`连接到partitioned node的用户`不可用。
\ No newline at end of file
+
+### AP(Availability and Partition Tolerance)
+> 这种类型的系统本质上是分布式的,确保即使在network partition场景下,用户发送的针对database nodes中数据的查看和修改请求不会被丢失
+
+该系统优先考虑了Availability而非Consistency,并且可能会返回过期的数据。一些技术failure可能会导致partition,故而过期数据则是代表partition产生前被同步的数据。
+
+AP系统通常在构建社交媒体网站如Facebook和在线内容网站如YouTube时使用,其并不要求一致性。对于使用AP系统的场景,相比于不一致,不可用会造成更大的问题。
+
+AP系统是分布式的,可以分布于多个节点,即使在network partition发生的前提下也能够可靠运行。
+
+### CP(Consistency and Partition Tolerance)
+> 该类系统本质上是分布式的,确保由用户发起的针对database nodes中数据进行查看或修改的请求,在存在network partition的场景下,会直接被丢弃,而不是返回不一致的数据
+
+`CP`系统优先考虑了Consistency而非Availability,如果发生network partition,其不允许用户从replica读取`在network partition发生前同步的数据`。对于部分应用程序来说,相比于可用性,其更强调数据的一致性,例如股票交易系统、订票系统、银行系统等)
+
+例如,在订票系统中,还剩余一个可订购座位。在该CP系统中,将会创建数据库的副本,并且将副本发送给系统中其他的节点。此时,如果发生网络问题,那么连接到partitioned node的用户将会从replica获取数据。此时,其他连接到unpartitioned部分的用户则可以对剩余的作为进行预定。这样,在连接到partitioned node的用户视角中,仍然存在一个seat,其将导致数据不一致。
+
+在上述场景下,CP系统通常会令其系统对`连接到partitioned node的用户`不可用。
\ No newline at end of file