diff --git a/jvm/深入理解java虚拟机.md b/jvm/深入理解java虚拟机.md
index 86aa4dc..6e55e76 100644
--- a/jvm/深入理解java虚拟机.md
+++ b/jvm/深入理解java虚拟机.md
@@ -28,6 +28,25 @@
- [垃圾回收细节](#垃圾回收细节)
- [回收方法区](#回收方法区)
- [判断类是否可回收](#判断类是否可回收)
+ - [垃圾收集算法](#垃圾收集算法)
+ - [标记-清除算法](#标记-清除算法)
+ - [复制算法](#复制算法)
+ - [基于复制算法的虚拟机新生代内存划分](#基于复制算法的虚拟机新生代内存划分)
+ - [标记-整理算法](#标记-整理算法)
+ - [分代收集算法](#分代收集算法)
+ - [Hotspot算法实现](#hotspot算法实现)
+ - [枚举根节点](#枚举根节点)
+ - [OopMap](#oopmap)
+ - [安全点](#安全点)
+ - [安全区域](#安全区域)
+ - [垃圾收集器](#垃圾收集器)
+ - [Serial收集器](#serial收集器)
+ - [ParNew](#parnew)
+ - [Parallel Scavenge](#parallel-scavenge)
+ - [MaxGCPauseMillis](#maxgcpausemillis)
+ - [GCTimeRatio](#gctimeratio)
+ - [Serial Old](#serial-old)
+ - [Parallel Old](#parallel-old)
# 深入理解java虚拟机
@@ -245,7 +264,129 @@ Java虚拟机规范并不强制要求对方法区进行垃圾回收,并且在
在大量使用反射、动态代理、Cglib、动态生成jsp、动态生成osgi等频繁自定义ClassLoader的场景都需要虚拟机具备类卸载功能,已保证永久代不会溢出。
-
+### 垃圾收集算法
+#### 标记-清除算法
+最基础的垃圾收集算法是`标记-清除`算法(Mark-Sweep),算法分为`标记`和`清除`两个阶段:
+- 首先,算法会标记出需要回收的对象
+ - 对象在被认定为需要回收前,需要经历两次标记,具体细节在前文有描述
+- 在标记完成后,会对所有被标记对象进行统一回收
+
+标记清除算法存在如下不足之处:
+- `效率问题`:标记和清除这两个过程的效率都不高
+- `空间问题`: 标记和清除之后会产生大量不连续的内存碎片,大量碎片可能导致后续需要分配大对象时无法找到足够的连续内存而不得不触发另一次垃圾收集动作
+
+#### 复制算法
+为了解决效率问题,提出了一种`复制`算法。该算法将可用内存划分为大小相等的两块,每次只使用其中的一块,当本块内存用尽后,其会将存活对象复制到另一块上,并将已使用的内存空间一次性清理掉。这样,每次回收都是针对半区的,并且在分配内存时也不用考虑内存碎片的问题。
+
+复制算法存在如下弊端:
+- 复制算法将可用内存划分为相同的两部分,每次只使用一半,该代价比较高昂
+
+##### 基于复制算法的虚拟机新生代内存划分
+当前,商用虚拟机都采用该种方法来回收新生代。在新生代中,98%的对象生命周期都很短暂,完全不需要根据1:1来划分内存空间。`对于新生代内存空间,将其划分为了一块较大的Eden空间和两块较小的Survivor空间,每次只会使用Eden和其中一块Survivor。`
+
+当发生垃圾回收时,会将Eden区和Survivor区中还存活的对象一次性复制到另一块Survivor。Hotspot虚拟机默认Eden区和两块Survivor区的大小比例为`8:1:1`,即每次新生代内存区域中可用内存为`90%`。当然,`并不能确保每次发生垃圾回收时,另一块Survivor区能够容纳Eden+Survivor中所有的存活对象`,故而,需要老年代来作为担保。
+
+#### 标记-整理算法
+在采用复制算法时,如果存活对象较多,那么将会需要大量复制操作,这样会带来较高的性能开销,并且,如果不想带来50%的内存空间浪费,就需要额外的内存空间来进行担保,故而,在老年代采用复制算法来进行垃圾回收是不适当的。
+
+基于老年代的特点,提出了`标记-整理`算法(Mark-Compact):
+- 标记过程仍然和`标记-清除`一样
+- 标记过程完成后,并不是直接对可回收对象进行清理,而是将存活对象都向一端移动,然后直接清理掉边界以外的内存
+
+`标记-整理`算法相对于`标记-清除`算法,其能够避免产生内存碎片。
+
+#### 分代收集算法
+目前,商业虚拟机的垃圾收集都采用`分代收集`的算法,这种算法将对象根据存活周期的不同,将内存划分为好几块。
+
+一般,会将java堆内存划分为新生代和老年代,针对新生代对象的特点和老年代对象的特点采用不同且适当的垃圾回收算法:
+- 在新生代中,对象生命周期短暂,每次垃圾收集都有大量对象需要被回收,只有少部分对象才能存活,应采用复制算法
+ - 在新生代,存活对象较少,复制的目标区的内存占比也可以划分的更少,并且较少存活对象带来的复制成本也较低
+- 在老年代,对象存活率更高,并且没有额外的内存空间来对齐进行担保,故而不应使用复制算法,而是应当采用`标记-清除`算法或`标记-整理`算法来进行回收
+
+### Hotspot算法实现
+#### 枚举根节点
+在可达性分析中,需要通过GC Roots来查找引用链。可以作为GC Roots的节点有:
+- 全局性的引用
+ - 常量
+ - 类静态属性
+- 执行上下文
+ - 栈帧中的本地变量表
+
+目前,很多应用仅方法区就包含数百兆,如果需要逐个检查这方面引用,需要消耗较多时间。
+
+可达性分析对执行时间的敏感还体现在GC停顿上,在执行可达性分析时,需要停顿所有的Java执行线程(STW),避免在进行可达性分析时对象之间的引用关系还在不断的变化。
+
+在Hotspot实现中,采用OopMap的数据结构来实现该目的,在类加载完成时,Hotspot会计算出对象内什么位置是什么类型的数据,在JIT编译过程中也会在特定位置记录栈和寄存器中哪些位置是引用。
+
+##### OopMap
+OopMap用于存储java stack中object referrence的位置。其主用于在java stack中查找GC roots,并且在堆中对象发生移动时,更新references。
+
+OopMaps的种类示例如下:
+- `OopMaps for interpreted methods`: 这类OopMap是惰性计算的,仅当GC发生时才通过分析字节码流生成
+- `OopMaps for JIT-compiled methods`:这类OopMap在JIT编译时产生,并且和编译后的代码一起保存
+
+#### 安全点
+在OopMap的帮助下,Hotspot可以快速完成GC Roots的枚举。但是,可能会导致OopMap内容变化的指令非常多,如果为每条指令都生成OopMap,将耗费大量额外空间。
+
+故而,Hotspot引入了安全点的概念,只有到达安全点时,才能暂停并进行GC。在选定Safepoint时,选定既不能太少以让GC等待时间太长,也不能过于频繁。在选定安全点时,一般会选中`令程序长时间执行`的的指令,例如`方法调用、循环跳转、异常跳转`等。
+
+对于Safepoint,需要考虑如何在GC发生时让所有线程都跑到最近的安全点上再停顿下来。这里有两种方案:
+- `抢先式中断`:在GC发生时,首先把所有线程全部中断,如果有线程中断的地方不在安全点上,就恢复线程,让其跑到安全点上
+- `主动式中断`:需要中断线程时,不直接对线程进行操作,只是会设置一个全局标志,线程在执行时主动轮询该标志,发现中断标志为true时自己中断挂起。
+ - 轮询的时机和安全点是重合的
+
+VM Thread会控制JVM的STW过程,其会设置全局safepoint标志,所有线程都会轮询该标志,并中断执行。当所有线程都中断后,才会实际发起GC操作。
+
+#### 安全区域
+safepoint解决了线程执行时如何进入GC的问题,但是如果此时线程处于Sleep或Blocked状态,此时线程无法响应JVM的中断请求,jvm也不可能等待线程重新被分配cpu时间。
+
+在上述描述的场景下,需要使用安全区域(Safe Region)。安全区域是指在一段代码片段中,引用关系不会发生变化。在这个区域中的任意位置开始GC都是安全的。可以把Safe Region看作是Safe Point的拓展版本。
+
+当线程执行到SafeRegion时,首先标识自身已经进入Safe Region。此时,当这段时间里JVM要发起GC时,对于状态已经被标识为Safe Region的线程,不用进行处理。当线程要离开安全区域时,需要检查系统是否已经完成了根节点枚举(或整个GC过程),如果完成了,线程继续执行,否则其必须等待,直到收到可以安全离开SafeRegion的信号。
+
+Safe Region可以用于解决线程在GC时陷入sleep或blocked状态的问题。
+
+### 垃圾收集器
+Java中常见垃圾回收器搭配如下
+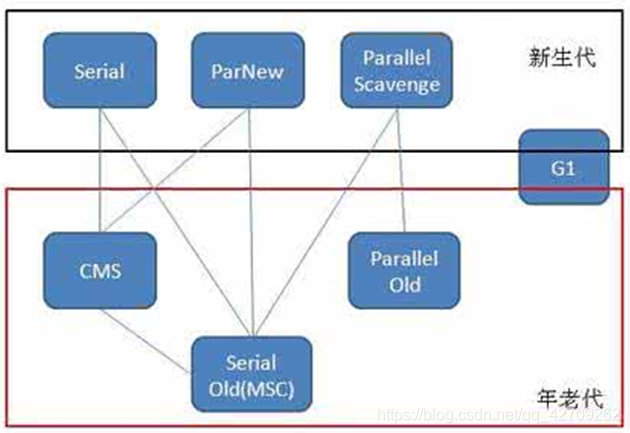 +
+#### Serial收集器
+Serial是最基本、历史最悠久的收集器,负责新生代对象的回收。该收集器是单线程的,并且`在serial收集器进行回收时,必须暂停其他所有的工作线程`,直到serial收集器回收结束。
+
+Serial搭配Serial Old的收集方式如下所示:
+
+
+#### Serial收集器
+Serial是最基本、历史最悠久的收集器,负责新生代对象的回收。该收集器是单线程的,并且`在serial收集器进行回收时,必须暂停其他所有的工作线程`,直到serial收集器回收结束。
+
+Serial搭配Serial Old的收集方式如下所示:
+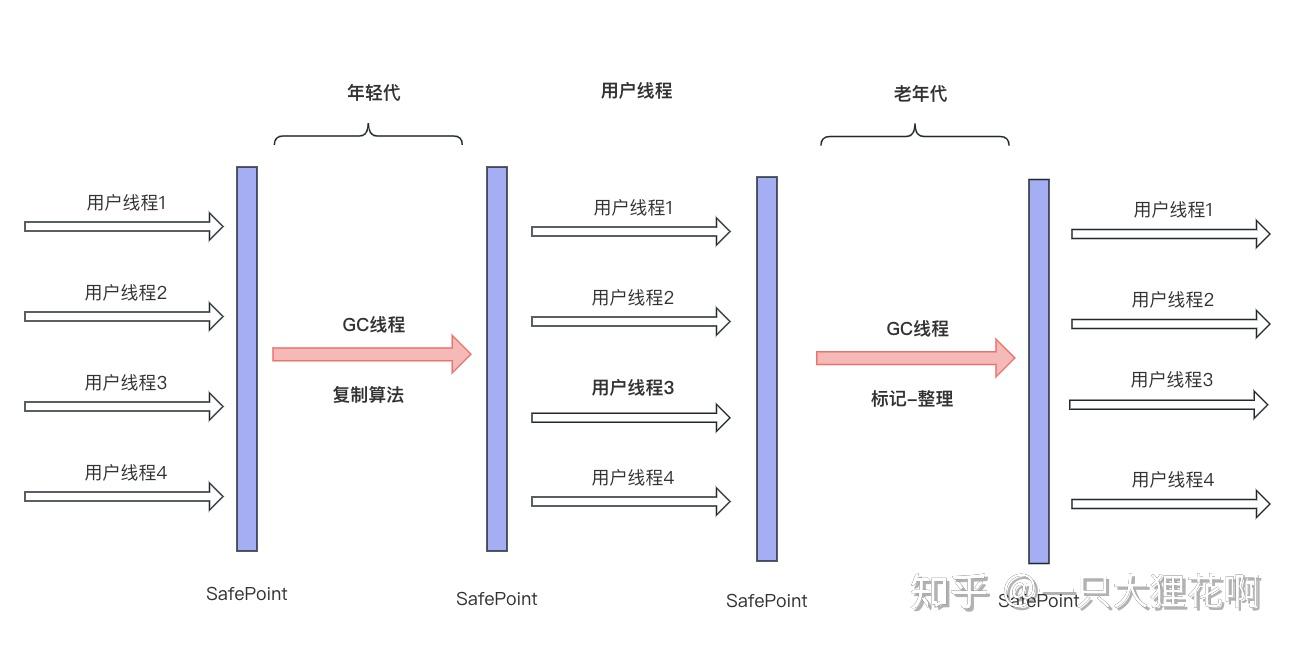 +
+#### ParNew
+ParNew即是Serial的多线程版本,除了使用多线程进行垃圾收集外,其他行为都和Serial完全一样。
+
+ParNew运行示意图如下所示:
+
+
+#### ParNew
+ParNew即是Serial的多线程版本,除了使用多线程进行垃圾收集外,其他行为都和Serial完全一样。
+
+ParNew运行示意图如下所示:
+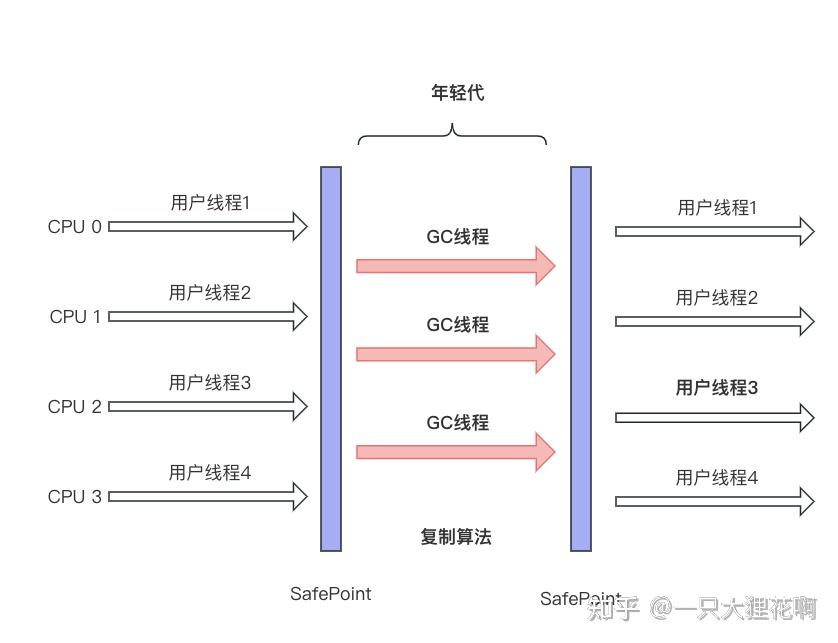 +
+#### Parallel Scavenge
+Parallel Scavenge是一个新生代的垃圾收集器,也采用了多线程并行的垃圾收集方式。
+
+Parallel Scavenge收集器的特点是其关注点和其他收集器不同,CMS等收集器会尽可能缩短收集时STW的时间,而Parallel Scavenge的目标则是达到一个可控制的吞吐量。
+
+> 此处,吞吐量指的是 `运行用户代码时间/(运行用户代码时间 + 垃圾收集时间)`,例如,虚拟机总共运行100分钟,垃圾收集花掉1分钟,那么吞吐量就为99%
+
+- 对于吞吐量较高的应用,则可以更高效的利用cpu时间,更快完成运算任务,主要适合在后台运行且不需要太多交互的任务
+- 而对于和用户交互的应用,STW时间越短则相应时间越短,用户交互体验越好
+
+##### MaxGCPauseMillis
+`-XX:MaxGCPauseMillis`用于控制最大的GC停顿时间,该值是一个大于0的毫秒数,垃圾回收器尽量确保内存回收花费的时间不超过该设定值。
+
+##### GCTimeRatio
+该值应该是一个大于0且小于100的整数,如果该值为n,代表允许的GC时间占总时间的最大比例为`1/(1+n)`。
+
+#### Serial Old
+Serial Old是Serial的老年代版本,同样是一个单线程的收集器,采用`标记-整理`算法对老年代对象进行垃圾收集。
+
+#### Parallel Old
+Parallel Old是Parallel Scavenge的老年代版本,使用多线程和`标记-整理`算法。
+
+Parallel Old主要是和Parallel Scavenge搭配使用,否则Parallel Scavenge只能搭配Serial Old使用。
+
+> 在Parallel Scavenge/Parallel Old搭配使用时,发生GC时用户线程也都处于暂停状态。
+
+#### Parallel Scavenge
+Parallel Scavenge是一个新生代的垃圾收集器,也采用了多线程并行的垃圾收集方式。
+
+Parallel Scavenge收集器的特点是其关注点和其他收集器不同,CMS等收集器会尽可能缩短收集时STW的时间,而Parallel Scavenge的目标则是达到一个可控制的吞吐量。
+
+> 此处,吞吐量指的是 `运行用户代码时间/(运行用户代码时间 + 垃圾收集时间)`,例如,虚拟机总共运行100分钟,垃圾收集花掉1分钟,那么吞吐量就为99%
+
+- 对于吞吐量较高的应用,则可以更高效的利用cpu时间,更快完成运算任务,主要适合在后台运行且不需要太多交互的任务
+- 而对于和用户交互的应用,STW时间越短则相应时间越短,用户交互体验越好
+
+##### MaxGCPauseMillis
+`-XX:MaxGCPauseMillis`用于控制最大的GC停顿时间,该值是一个大于0的毫秒数,垃圾回收器尽量确保内存回收花费的时间不超过该设定值。
+
+##### GCTimeRatio
+该值应该是一个大于0且小于100的整数,如果该值为n,代表允许的GC时间占总时间的最大比例为`1/(1+n)`。
+
+#### Serial Old
+Serial Old是Serial的老年代版本,同样是一个单线程的收集器,采用`标记-整理`算法对老年代对象进行垃圾收集。
+
+#### Parallel Old
+Parallel Old是Parallel Scavenge的老年代版本,使用多线程和`标记-整理`算法。
+
+Parallel Old主要是和Parallel Scavenge搭配使用,否则Parallel Scavenge只能搭配Serial Old使用。
+
+> 在Parallel Scavenge/Parallel Old搭配使用时,发生GC时用户线程也都处于暂停状态。